一种并行化工作流关联数据发现方法与流程
本发明涉及信息技术领域,更具体地,涉及一种并行化工作流关联数据发现方法。
背景技术:
目前,数据密集型服务是一类以数据为中心,通过对大量数据进行操作从而完成一系列特定任务的服务。在数据感知的流程中,数据实体记录了流程流转的关键信息,这些数据实体存在一定的关联关系。
随着云计算技术的快速发展,越来越多的机构开始将工作流部署在云环境中。随着云工作流的发展,一些问题相应产生,例如数据放置问题和数据备份问题。数据放置是云工作流中的一个典型问题。由于数据密集型服务需要处理大量的数据,而这些数据大多分布在不同的数据中心,因而数据放置成为了一个至关重要的问题。为降低数据通信量,我们需要将相关联数据尽量放置于同一数据中心中。另外,数据备份也是一不可忽视的问题。由于数据密集型服务流程涉及的数据量很大,例如在LIGO(激光干涉引力波天文台)的科学工作流中至少涉及到221GB的数据量和大约70,000个工作节点。因此需要有选择地对数据进行备份。故我们需要区分出数据的重要层次。
纵观云工作流中数据放置的研究现状,一些研究学者已然着眼于该研究点,并提出许多有效的方法,但大多数都采用基于聚类的方法来区分数据。这些方法缺乏对数据的频繁模式的考虑,因而有可能导致一些无用的不重要的数据项的产生。
综上所述,为了为云工作流的数据放置提供理论基础支持,需要发现相关联的数据实体,区分出数据实体的重要层次。
技术实现要素:
数据密集型服务流程中需要处理大量数据,而这些数据大多相互关联,为了发现工作流中相关联数据,区分出数据间的重要层次,为云工作流的数据放置提供理论基础,本发明提供一种克服上述问题或者至少部分地解决上述问题的方法。
根据本发明的一个方面,提供一种并行化工作流关联数据发现方法,其特征在于,所述方法包括:
S1,从工作流日志中提取出原始数据集;
S2,基于所述原始数据集,利用两轮MapReduce模型分别并行化挖掘,计算出所有数据的数据频度计数和最终频繁二项集。
本申请提出一种基于频繁项集的并行化工作流关联数据发现方法,通过对工作流日志分析,基于MapReduce框架,设计出一种面向工作流的并行化数据频繁项集挖掘算法,挖掘出工作流中具有区分力的数据频繁二项集,从而发现工作流中相关联的数据实体,区分出数据实体间的重要层次,为云工作流的数据放置提供了理论基础支持。本方法自动化程度高,易于部署和实施,具有较好的运行时间,更适于数据密集型服务流程中使用。
附图说明
图1为根据本发明实施例一种并行化工作流关联数据发现方法总体流程的示意图;
图2为根据本发明实施例中利用MapReduce模型并行化挖掘计算出所有数据的频度计数方法框架结构的示意图;
图3为根据本发明实施例频繁模式树结构的示意图。
图4为根据本发明实施例频繁矩阵结构的示意图。
图5为根据本发明实施例建立频繁模式树及频繁矩阵方法流程的示意图。
图6为根据本发明实施例中并行化挖掘最终频繁项集方法的框架结构示意图。
图7为根据本发明实施例中并行化挖掘最终频繁项集方法流程的示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
首先对本发明涉及到的相关技术背景进行简要说明。
MapReduce,是一种用于大规模数据集并行运算的编程模型。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
频繁模式树(Frequent Pattern tree)简称为FP-tree,是满足下列条件的一个树结构:它由一个根节点(值为null)、项前缀子树(作为子女)和一个频繁项头表组成。
如图1所示,本发明的一个具体实施例中,示出了一种并行化工作流关联数据发现方法总体流程,该方法包括以下步骤:
S1,从工作流日志中提取出原始数据集;
S2,基于所述原始数据集,利用两轮MapReduce模型分别并行化挖掘,计算出所有数据的数据频度计数和最终频繁二项集。
本发明的另一个具体实施例中,步骤S2,基于所述原始数据集,利用两轮MapReduce模型分别并行化计算出所有数据的数据频度计数和最终频繁二项集,还包括以下步骤:S21,基于所述原始数据集,利用MapReduce模型并行化挖掘计算出所有数据的频度计数;S22,基于所述数据频度计数,利用齐夫分布特征,得到最小支持度阈值;S23,基于所述最小支持度阈值,建立频繁模式树及频繁矩阵;S24,利用MapReduce模型对频繁模式树进行并行化挖掘,得到最终频繁二项集。
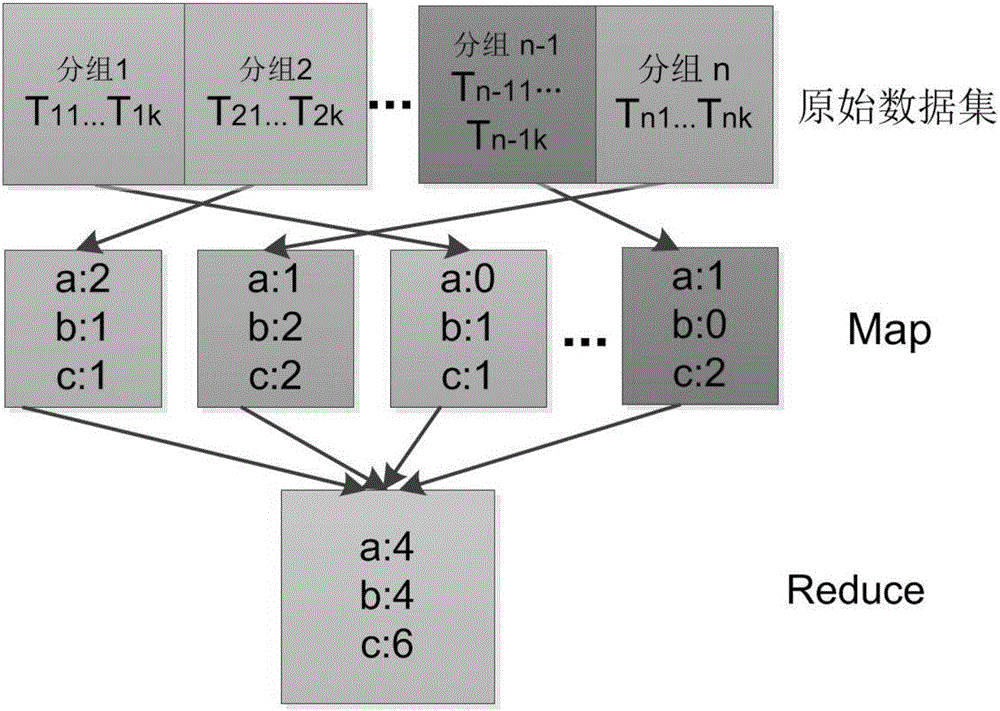
如图2所示,本发明的另一个具体实施例中,示出并行化计算出所有数据的频度计数方法的框架结构:在所述并行化计算出所有数据的频度计数方法中,将原始数据集分为组;利用Map(映射函数)分别对每个数据集组进行计数,得出相应的数据频度;最后,利用归约函数Reduce将所有数据频度进行汇总。
本发明的另一个具体实施例中,步骤S22基于所述数据频度计数,根据齐夫分布特征,设定最小支持度阈值,还包括以下步骤:假设原始数据集中数据频度分布服从齐夫分布,由于齐夫分布的累计分布函数如下:
其中,k为数据频度排序,N为数据个数,s为指数特征值。根据齐夫分布的特征,假设p为最小支持度阈值所占比例,当s一定时,其可以根据如下公式算出:
因此,最小支持度阈值自动设定方法包括如下步骤:
S221,对原始数据集按数据频度进行排序;
S222,计算p值,最小支持度阈值为pN所对应的数据频度,即
本发明又一个具体实施例中,步骤S23基于所述最小支持度阈值,建立频繁模式树及频繁矩阵具体包括如下步骤:设定好最小支持度阈值之后,需要对原始数据集中数据按照最小支持度阈值进行过滤,剩下数据频度大于最小支持度计数的数据,然后再建立FP树和FP矩阵。
如图3所示,本发明的另一个具体实施例中,示出了频繁模式树(FP树)结构,所述FP树记录了数据及其频度,并且数据按照频度从大到小的关系列于数据频繁队列中。
如图4所示,本发明的另一个具体实施例中,示出了频繁矩阵(FP矩阵)结构,所述FP矩阵是一个(m-1)×(m-1)的阶梯形矩阵,其用于记录数据频繁项的支持度计数以及兴趣度度量值,FP矩阵中的每个元素可记为如下二元组的形式:
如图5所示,本发明又一个具体实施例中,示出建立FP树及FP矩阵方法流程,包括如下步骤:
S231,扫描原始数据库,对于频度大于最小支持度阈值的数据,将其插入频繁数据项队列L中;
S232,将L中数据按照频度从大到小进行排序;
S233,创建FP树的根节点,以“Root”进行标记;
S234,对于原始数据集中的每个事务,选择其中的频繁数据项,集频繁项列表为[e|E],其中e是第一个元素,而E是剩余的元素列表。将元素的频度计数置为0。
S235,如果FP树中有子女N使得N.item_name=e.item_name,则将N的频度计数增加1;否则,创建一个新节点N,将其频度计数置为1,并将其连接到它的父节点。通过节点链结构将其链接到具有相同item_name的节点;
S236,如果E非空,则递归地调用S235;
S237,将FP矩阵中的支持度计数和兴趣度度量值置为0。扫描原始数据集中的每个事务,将FP矩阵中每个数据对相应的支持度计数增加1。
如图6所示,本发明又一个具体实施例中,示出并行化挖掘最终频繁项集方法的框架结构。将所述频繁模式树中数据频繁项队列进行分组,利用映射函数Map分别数挖掘每个小组中的数据频繁二项集;利用归约函数Reduce汇集所有Map的频繁二项集;将所有利用归约函数Reduce所得的频繁二项集进行组合,得到最终频繁二项集。
本发明又一个具体实施例中,本实施例提供的并行化数据频度计数方法包括:将所有数据频度计数置为0;将原始数据集划分为个组,并行计算各个组中每个数据aj对应的频度计数cj;将数据aj对应的全局支持度计数sup(aj)置为0,汇集aj的所有局部支持度计数,得到最终全局支持度计数sup(aj)。
如图7所示,本发明又一个具体实施例中,示出步骤S24中并行化挖掘最终频繁项集方法具体包括:
S241,将数据频繁项队列分为logm个小组;
S242,将每一个分组中的数据进行出队操作;
S243,依次计算每个出队数据与其在频繁模式树中父节点的兴趣度度量值,将大于正模式阈值的兴趣度度量值写入频繁矩阵对应元素中;
S244,依次确认频繁模式树的不同枝具有相同数据,则利用节点链结构链接上述枝,然后继续进行挖掘;
S245,当所有数据出队完之后,结束Map阶段,进入Reduce阶段。在Reduce阶段,利用归约函数,将所有的频繁项对进行汇总,得到最终频繁二项集。
本实施例提供的一种基于频繁项集的并行化工作流关联数据发现方法,通过对工作流日志分析,基于MapReduce框架,设计出一种面向工作流的并行化数据频繁项集挖掘算法,挖掘出工作流中具有区分力的数据频繁二项集,从而发现工作流中相关联的数据实体,区分出数据实体间的重要层次,为云工作流的数据放置提供了理论基础支持。本方法自动化程度高,易于部署和实施,具有较好的运行时间,更适于数据密集型服务流程中使用。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!