一种基于特征聚类比较的光伏电站功率预测方法及装置与流程
本发明涉及一种基于特征聚类比较的光伏电站功率预测方法及装置,属于光伏发电技术领域。
背景技术:
光伏发电作为清洁能源的一种,在世界范围内都受到了广泛的重视,我国大型地面光伏电站,分布式屋顶光伏电站已经越来越多,但是由于光伏发电具有波动性和间歇性,给电网调度带来了很大困难,光伏功率预测的开展有效缓解了这一问题,但是目前市面上的光伏功率预测误差较大,难以给电网调度以有效的参考。
目前,我国针对光伏电站的功率预测已经开展了部分技术研究,现有的预测模型包括神经网络模型、径向基函数模型和多层感知模型等。其中神经网络模型应用最为广泛,神经网络模型经过输入层、隐含层和输出层中各种神经元的作用生成输出量,再以误差为目标函数对网络权值进行不断地修正直至误差达到要求,经训练后的网络就可以进行预测光伏组件是输出功率。但是,目前的神经网络模型只能将预测误差控制在20%左右,若遇到雷雨大风天气,预测精度会更差,要想进一步提高预测精度,需对输入数据做合理的预处理,另外保证训练样本的历史数据的准确性。
名称为《基于天气类型聚类和LS-SVM的光伏出力预测》的论文中给出一种预测方法,该方法将历史气象数据按季节类型聚类,得到每个季节的四种不同类型聚类样本,形成相应的预测模型;实际预测时,先根据待预测日期确定所属季节,由待预测日气象特征找到对应的预测子模型,进行预测,文章中虽然给出了一种缩小样本范围寻求最佳预测子模型进行预测的预测方法,但是由于待预测日期是根据时间划分季节,寻求预测子模型,这样的划分方法具有一定的主观性和强制性,进而也限制了寻求最优预测模型的过程,部分样本数据尤其是在季节交替时间段内的样本数据难免出现因寻求不到最佳预测模型而使得预测精度降低的情况。
技术实现要素:
本发明的目的是提供一种基于特征聚类比较的光伏电站功率预测方法,以及巨额目前光伏电站功率预测精度低、准确性不高的问题。同时还提供了一种基于特征聚类比较的光伏电站功率预测装置。
本发明为解决上述技术问题而提供一种基于特征聚类比较的光伏电站功率预测方法,该预测方法的步骤如下:
1)采集影响光伏功率预测精度的特征量,总辐射、风速和温度,并利用特征量的历史数据构成样本集;
2)将得到的样本集进行特征聚类,将样本集化分成相似性较高的k类,并得到各类样本数据的聚类中心Ci,i=1,2,……,k;
3)分别采用各类样本数据对应建立k类预测模型;
4)计算当前预测对象与各类样本数据的聚类中心之间的距离,选取与当前预测对象距离最近的聚类中心所在类对应的预测模型进行预测。
进一步地,所述步骤2)采用K-means算法进行特征聚类,各类的初始聚类中心采用Huffman构造树的思想获取。
进一步地,所述步骤3)的预测模型采用BP神经网络预测模型,该预测模型采用包括输入层、隐含层和输出层的三层结构,输入层采用总辐射、温度、风速三个特征量,输出层为光伏电站输出功率。
进一步地,所述步骤4)中当前预测对象与各类的聚类中心之间的距离采用加权法的欧式距离计算得到。
进一步地,所述步骤2)将样本集划分为三类,分别代表阴雨、多云和晴天。
本发明还提供了一种基于特征聚类比较的光伏电站功率预测装置,该预测装置包括采集模块、特征聚类模块、预测模型建立模块和预测模块,
所述的采集模块用于采集影响光伏功率预测精度的特征量,总辐射、风速和温度,并利用特征量的历史数据构成样本集;
所述的特征聚类模块用于将得到的样本集进行特征聚类,将样本集化分成相似性较高的k类,并得到各类样本数据的聚类中心Ci,i=1,2,……,k;
所述的预测模块建立模块分别利用各类样本数据建立对应k类预测模型;
所述的预测模块用于计算当前预测对象与各类样本数据的聚类中心之间的距离,选取与当前预测对象距离最近的聚类中心所在类对应的预测模型进行预测。
进一步地,所述的特征聚类模块采用K-means算法进行特征聚类,各类的初始聚类中心采用Huffman构造树的思想获取。
进一步地,所述的预测模块建立模块采用BP神经网络预测模型,该预测模型采用包括输入层、隐含层和输出层的三层结构,输入层采用总辐射、温度、风速三个特征量,输出层为光伏电站输出功率。
进一步地,所述的预测模块在计算当前预测对象与各类的聚类中心之间的距离采用加权法的欧式距离计算得到。
进一步地,所述的特征聚类模块将样本集划分为三类,分别代表阴雨、多云和晴天。
本发明的有益效果是:本发明首先获取影响光伏功率预测精度的三个最主要特征量,并积累为历史气象数据;然后将得到的历史气象数据作为数据样本进行聚类,将样本分成相似性较高的k类,并得到各类的簇中心;分别使用各类历史数据建立相应类的预测模型;选取与当前对象距离最近簇中心所对应的预测模型进行预测。本发明将不同的气象数据分成不同的样本类型,并建立不同气象条件下的光伏出力预测模型,使预测模型的训练更有针对性,利用不同气象条件建立的功率预测模型进行预测,提高了光功率预测精度。
附图说明
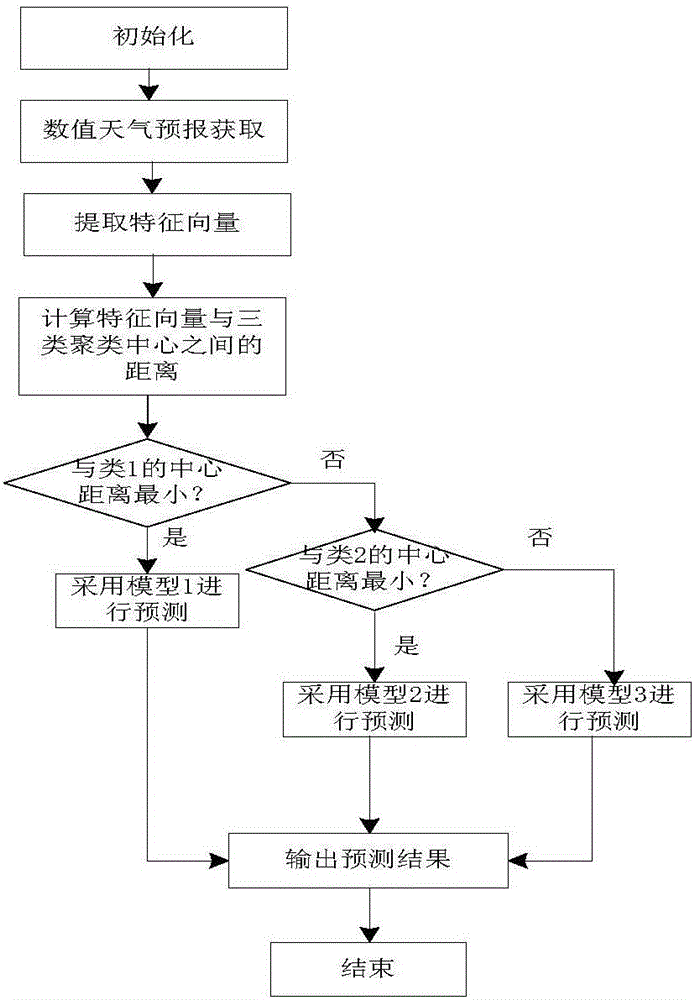
图1是本发明基于特征聚类比较的光伏电站功率预测方法的流程图;
图2是Huffman树的构造过程示意图;
图3是基于Huffman树的初始聚类中心选取流程图;
图4是基于BP神经网络的预测模型图。
具体实施方式
下面结合附图对本发明的具体实施方式做进一步的说明。
本发明基于特征聚类比较的光伏电站功率预测方法的实施例
本发明的光伏电站功率预测方法首先获取影响光伏功率预测精度特征量,利用特征量的历史数据构成样本集;然后通过特征聚类算法将样本集聚为k类,利用各类历史数据建立相应类的预测模型;最后计算当前对象与各类簇中心之间的距离,并选取与当前对象距离最近的簇中心所在类对应的预测模型对当前对象预测,从而实现光伏电站功率的预测。该方法的实施流程如图1所示,具体步骤如下。
1.获取影响光伏功率预测精度的三个最主要特征量,并利用特征量的历史数据构成样本集。
本发明所选取的影响光伏功率预测精度的三个最主要特征量分别为总辐射、风速和温度,这三种特征量可从NWP数值天气预报中获取。
2.将得到的样本集进行特征聚类,将样本分成相似性较高的k类,并得到各类的聚类中心Ci,i=1,2,……,k。
实现样本聚类的算法有多种,基于划分的聚类算法、基于层次的聚类算法、基于网格的聚类算法、基于密度的聚类算法等,均可实现本发明中的聚类过程,下面以基于划分聚类算法中最典型的K-means算法为例,对本发明的聚类过程进行详细说明,具体实施如下:
(1)建立特征矩阵。
以光伏电站历史气象数据作为样本,特征量分别为总辐射、温度、风速,则样本构成如下:
每个样本数据涵盖各个特征量
其中,ui1,ui2,ui3分别代表总辐射,风速,温度3个特征量。
(2)选取初始聚类中心。
本实施例采用基于Huffman树构造思想来选取初始聚类中心。向量个数为n,样本集维数为3,拟聚类种类为3类,聚类种类可根据实际情况进行调整,本实施例中仅给出3类的情况,初始中心点选取具体步骤如下。
第一步:计算两两向量之间的欧氏距离。
其中i=1,2…n;j=1,2…n;且i≠j。
得到相异度矩阵,矩阵如下式:
第二步:找到矩阵中最小值dij,计算ui,uj两个向量平均值,得到向量V1。
第三步:从原特征矩阵中删除ui,uj两个向量,并加入向量V1,得到新的特征矩阵。
第四步:重复步骤一、步骤二、步骤三,直到特征矩阵中仅剩下一个向量,迭代过程中构造树的过程如图2所示。
第五步:将数据聚为5类,从顶点Jm起依次将节点从树中减掉,减掉个数为4个,构成5个树,如图3所示。
第六步,分别求取3个树最底层的节点向量的平均值,得到向量即为初始聚类中心。
(3)计算初始聚类中心下平均误差准则函数。
其中k=3,代表所划分簇的个数;ui(0)代表3个簇的中心。
(4)计算新的聚类中心。
N1表示属于元素个数
N2表示属于元素个数
N3表示属于元素个数
其中N1+N2+N3=n n表示样本数据总量
(5)重复上述步骤(2)、(3)、(4),直至满足如下关系。
且存在E(s+1)≤E(s),说明经过s次聚类迭代后,平均误差准则函数呈现收敛状态,且簇中心不再发生变化,停止迭代,至此聚类结果完成。
3.建立光伏功率预测模型。
本实施例中采用BP神经网络预测模型作为光功率的预测模型,分别使用聚类后的各类历史数据对BP神经网络模型进行训练,以得到与各类对应的预测模型。如图4所示,BP神经网络预测模型采用三层结构,输入层、隐含层、输出层,输入层采用总辐射、温度、风速三个特征量,输出层为光伏电站输出功率、隐含层神经元个数通过工程实际验证获得。根据步骤2中得到聚类结果,将三类的样本数据分别带入到BP神经网络预测模型中进行训练,即可得到三类不同的预测模型。具体实现过程如下:
第一步,网络初始化:给各连接权值分别赋一个区间(-1、1)内的随机数,设定误差函数e,给定计算精度值Δ和最大学习次数。
第二步,选取k个输入样本(最近30天的历史数据)及对应期望输出(期望输出值为相应30天实际发电功率)。
第三步,计算隐含层各神经元的输入和输出。
第四步,利用网络期望输出(实际发电功率)和实际训练后输出结果,计算误差函数对输出各神经元的偏导数。
第五步,利用输出层各神经元的误差偏导数和隐含层各神经元的输出来修正连接权值。
第六步,利用隐含层各神经元的误差偏导数和输入层各神经元的输出修正连接权值。
第七步,计算全局误差。
第八步,判断网络误差是否满足要求,当误差达到预设精度或学习次数大于设定的最大次数,则结束算法,否则,选取下一个学习样本及对应的期望输出,返回到第三步,进入下一轮学习。
4.计算当前预测对象与各类的聚类中心之间的距离,选取与当前预测对象距离最近的聚类中心所在类对应的预测模型进行预测。
第一步,获取当前预测对象的气象数据,根据聚类算法输出结果,选定预测模型。
计算当前对象的气象数据与各类聚类中心之间的加权欧式距离,若与第i类簇中心Ci距离最小,则使用第i类预测模型进行预测。
第二步,气象数据归一化处理。
第三步,将当前气象数据作为输入,加载相应的预测模型,输出预测结果。
通过上述过程本发明能够根据不同的气象条件建立的功率预测模型,可有效改善阴雨天气条件下光伏输出功率预测精度低的问题。
本发明基于特征聚类比较的光伏电站功率预测装置的实施例
本实施例中的预测装置包括采集模块、特征聚类模块、预测模型建立模块和预测模块;采集模块用于采集影响光伏功率预测精度的特征量,总辐射、风速和温度,并利用特征量的历史数据构成样本集;特征聚类模块用于将得到的样本集进行特征聚类,将样本集化分成相似性较高的k类,并得到各类样本数据的聚类中心Ci,i=1,2,……,k;预测模块建立模块分别利用各类样本数据建立对应k类预测模型;预测模块用于计算当前预测对象与各类样本数据的聚类中心之间的距离,选取与当前预测对象距离最近的聚类中心所在类对应的预测模型进行预测。各模块的具体实现手段已在方法的实例中进行说明,这里不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!