一种分层首拼号编码系统方法与流程
本公开涉及一种分层首拼号编码系统方法,使用这种编码系统方法可以快速、高效、直观地用中文汉字词语编码,从而可使编码承载对象编码信息的同时,也能直观从汉字词语中承载对象的其他身份信息。且利用“分层首拼编码法”的专利技术可以实现这些汉字词语快速记录、传播、输出。
背景技术:
目前我国正处在信息化的进程中,在此进程中,参与信息化的对象可以分为两大类,人和物;信息化对象如果要交流信息,这些对象必须都有一个不能重码的“名字”,这个“名字”用专业词语表达就是“编码”,是具有唯一性、不能重码的特点,目前,这类编码系统大多采用英文字母或阿拉伯数字作为编码元素或采用英文字母和阿拉伯数字混合的方式作为编码元素来设计,比如身份证编码系统就是采用18位阿拉伯数字作为编码元素进行设计的,www网址和电子邮件实际上也是一种编码,它们就是主要以英文字母作为编码元素来编码的。传统的这些编码元素,在我国是以汉字为语言载体的国家都存在一个缺点——不能够使人容易记住这些编码,记住这些英文字母难度自然很大;而以纯数字为编码元素的编码,由于码长太长,也很难记忆。比如,手机号码,11位,身份证号18位,都是难记忆的,用专业词语表达就是这类编码只承载了对象的编码信息,都不能承载对象的其他身份信息。因此,还是需要一种方法能解决以上问题。
本专利的概念和方法是以许晓敏先生发明的《分层首拼编码法(专利申请号2015100853969)》和《英文字母和数字分层首拼编码法(专利申请号2016104532637)》为基础。
技术实现要素:
英文字母定义:指包括大写和小写的共52个字母,分别是:abcdefghijklmnopqrstuvxyzABCDEFGHIJKLMNOPQRSTUVWXYZ。
数字定义:指共十个阿拉伯数字,分别为0123456789。
广义汉字:指包括汉字、英文字母、阿拉伯数字(把英文字母和数字看作是只有一笔画的“汉字”),广义汉字是本专利的定义,特此说明。
一种分层首拼号编码系统方法,就是在传统采用英文字母和阿拉伯数字作为编码元素的基础上,加入“汉字”作为编码元素,形成一种主要采用汉字、英文字母、阿拉伯数字、符号为编码元素的混合编码方法,编码中汉字、英文字母、阿拉伯数字、符号可以任意搭配混合。根据分层首拼号编码系统方法形成的编码叫做“分层首拼号”,且定义分层首拼号由“主体关键词”+“数字识别号”+“结束标志符”三部分组成,其中“主体关键词”由注册者根据一定的规则要求提出,“主体关键词”的组成元素可以是汉字、英文字母、阿拉伯数字、符号;“数字识别号”则由电脑依据“分层首拼号”对应的“首拼字母码”不重码的规则自动生成,“数字识别号”的组成元素是01234566789共十个阿拉伯数字。“数字识别号”结构为“(n-1)”,其中,n取自然数(1,2,3…递增上不封顶),如果n=1,“数字识别号”就是“”;“结束标志符”是由三个数字字符“001”组成,是固定不变,也就是说所有的分层首拼号的后三位都为“001”,它的作用一是作为“分层首拼号”的结束符,一个分层首拼号到001就结束了;作用二是区别分层首拼号和一般长词条的标志符。举例,“许晓敏8856”就是一个普通混合词语,那么“许晓敏8856001”就是一个分层首拼号,又比如“广州小铁信息科技有限公司”是一个公司名字,那么“广州小铁信息科技有限公司001”就是一个分层首拼号;当然,001也可以用其他数字或字母或其他符号代替。
“首拼字母码”是“第1层首拼字母码”的简称,是指“分层首拼号”或“主体关键词”或其他编码对象依据许晓敏先生发明的《分层首拼编码法(专利申请号2015100853969)》和《英文字母和数字分层首拼编码法(专利申请号2016104532637)》,将分层首拼号中出现的汉字、英文字母、数字都用对应的英文字母代替,且取第1层首拼字母形成的编码。
“主体关键词”长度要求至少为一个广义汉字。例如,“许89567001”是“分层首拼号”,其中,“许”是主体关键词,“89567001”是识别号。“广州小铁信息科技有限公司001”是“分层首拼号”,其中,“广州小铁信息科技有限公司”是主体关键词,“001”是识别号。
“分层首拼号”生成过程:第一步提出“新主体关键词”;第二步过滤符号,依据分层首拼编码法规则,过滤掉“新主体关键词”中的符号,只保留汉字、英文字母和数字;第三步生成新主体关键词的“首拼字母码”(新主体关键词中如果有多音字,注册者要选择其一正确读音);第四步比较首拼字母码,取新主体关键词的“首拼字母码”作为比较对象与库中已经存在的主体关键词“首拼字母码”做比较,寻找相同编码,并取已经存在的主体关键词“首拼字母码”对应的最大的数字识别号值(记为n-1,n为自然数,下同),然后自动加1形成新的数字识别号(记为n)作为新主体关键词的“数字识别号”,且定义“&n”表示自然数n对应的“首拼字母码”;第五步合并,将新主体关键词“首拼字母码”+&n+结束标志符001的“首拼字母码”三部分合并,形成新分层首拼号的“首拼字母码”;第六步,检查有无重码,检查这个新分层首拼号的“首拼字母码”在库中是否存在重码,如果存在的话,自然数n要自动加1,然后又将新主体关键词“首拼字母码”+&n+结束标志符001的“首拼字母码”三部分合并,再形成新分层首拼号的“首拼字母码”,再检查新分层首拼号的“首拼字母码”在库中是否存在重码,依次循环,n值不断增加,直到分层首拼号的“首拼字母码”全部没有重码;第七步,确定分层首拼号和首拼字母码,没有重码后,锁定n值,这时候的“分层首拼号”就是该“新主体关键词”的分层首拼号,这时候的“首拼字母码”就是该“新主体关键词”的首拼字母码。
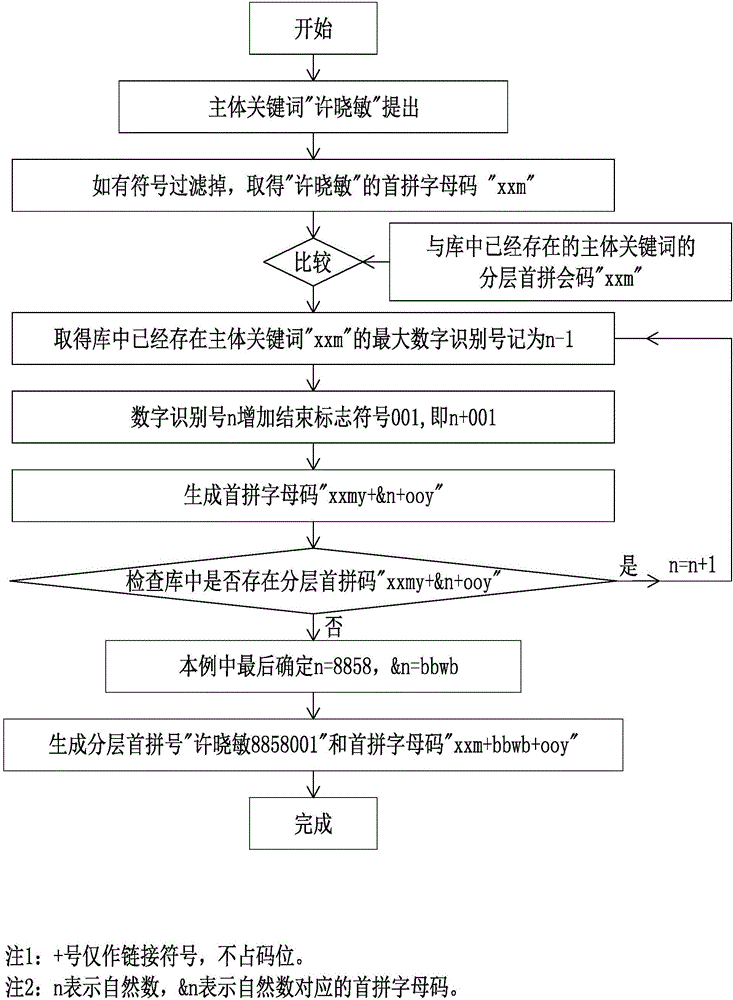
举例,一个新的人名叫“许晓敏”,编码系统库中已经有了一个分层首拼号叫“许晓敏8856001”,同时有一个分层首拼号“许小敏8857001”,那么此时这个新的“许晓敏”,它的分层首拼号只能是“许晓敏8858001”,因为“许晓敏”和“许小敏”的首拼字母码都是xxm,要以“xxm”作为比较对象,取最大的数字识别号(详细过程参见附图1、附图2、附图3)。
“分层首拼号”是不存在重码的,“首拼字母码”也是不存在重码的,它们之间更不存在重码。且一个“分层首拼号”一定有一个唯一的“首拼字母码”,它们之间是一一对应的关系,“分层首拼号”和“首拼字母码”都可以作为注册者的身份编码来使用。
含有中文汉字的“分层首拼号”一般用于注册者愿意将编码公开的场合;“首拼字母码”则可以适用于不宜将注册者信息公开的场所。因为“分层首拼号”中的汉字与对应的首拼字母是多对一的关系,所以“首拼字母码”不会泄漏注册者的真实信息;比如,许晓敏,徐小明,夏小毛,习秀美,这些人名字词语的首拼字母都是xxm,如果陌生的对方仅仅知道xxmbbwlooy,他是不知道注册者的真实信息的。
“分层首拼号”的末尾三位一定是001;“首拼字母码”由26个小写英文字母abcdefghijklmnopqrstuvxyz组成,是一种“纯小写英文字母编码”,如果用“分层首拼输入法软件”输入“首拼字母码”,电脑则自动输出“分层首拼号”的。例如,分层首拼号“广州小铁信息科技有限公司001”,他的“首拼字母码”是“gzxtxxkjyxgs+ooy”。
“分层首拼号”、“首拼字母码”、“主体关键词”、“数字识别号”、“结束标志符”是本专利的叫法,也可以用其他名字,但方法不变。
采用汉字作为编码的好处很多,第一,汉语是我们的母语,我们记忆一串汉字总比记忆一串英文字母要强,因此很好记,第二,运用“分层首拼编码法”技术,解决了汉字编码在人与人的交流过程中书写的问题,打个比方,人们通常要在电话中交流彼此中文姓名,好比有2个人名分别叫“章三”、“张三”吧(两个读音都一样),传统的介绍方法是“我叫章三,文章的章,一二三的三”,另外说,“我叫张三,弓长张的张,一二三的三”,是很麻烦,那么有了分层首拼号后,章三就可以这样介绍自己,“我叫章三,我的分层首拼号是‘章三8826001’”,另外的张三就可以这样介绍自己,“我叫张三,我的分层首拼号是‘张三8827001’”。此时电话那头对方记录的时候,不用记录汉字“章三”,也不用记“张三”,只需要记章三或张三这个词语汉语拼音的首拼字母码“zs”和后面分别对应的数字识别号826001、8827001,合起来就是zs+8826001和zs+8826001,大家注意到,两个读音完全相同的两个人名,最后在“分层首拼号”的区别下,轻松地被记录这区分开来。记录者只需要在“分层首拼输入法”软件中输入“首拼字母码”zs+bbelooy和zs+bbeqooy一查便知道对方的分层首拼号是“章三8826001”和“张三8827001”,自然就提取了他的姓名“章三”和“张三”(详细参见附图4)。
分层首拼号的设计方法,正是利用了汉字、阿拉伯数字和英文字母各自的优点,念汉字对方知道意思,容易记忆,念阿拉伯数字和英文字母对方书写相对简单些。这其中就包括了一个很典型的例子是,在电话等非面对面交流中,念一个汉字让对方去记录该汉字的首拼比念一个英文字母让对方去记录一个英文字母要容易的多。比如,高(gao)、饺(jiao),一方同时念出这两个汉字,对方一定正确写出g和j的,相反,如果一方直接念g和j,对方会弄错的,因为g的西文发音与j作为汉语拼音字母的发音是几乎一样的,都是念(鸡)。所以“分层首拼号”就实现了既好记忆又好书写的双重优点。再比如,许晓敏先生同时有两个分层首拼号,一个使用汉字,另外一个不使用汉字,这样分层首拼号分别是“许晓敏8856001”、“98589867001”,很显然,看到第一个分层首拼号就知道此号是许晓敏先生的,而第二个分层首拼号一点对象信息都不承载,想要记住是很难的(详细参见附图4)。
一种分层首拼号编码系统方法所产生的“分层首拼号”,可使编码承载两大信息,即可使编码承载对象编码信息和其他身份信息,分层首拼号中文部分长度越长,则承载的身份信息越多。例如,分层首拼号“许晓敏8856001”、“许晓敏老师51001”,后者显然比前者承载的对象信息更多。
附图说明
图1:分层首拼号编码生成流程图1。说明:下面以主体关键词“许晓敏”为例,阐述一条“分层首拼号”的生成过程。
图2:分层首拼号编码生成流程图2。说明:下面以汉字和字母组合的主体关键词“许晓敏y”为例,阐述一条“分层首拼号”的生成过程。
图3:分层首拼号编码生成流程图3。说明:下面以带符号的主体关键词“www.fen13.com”为例,阐述一条“分层首拼号”的生成过程。
图4:某编码系统注册身份信息登记举例表。
具体实施方式
一种分层首拼号编码系统方法适用于信息社会的各个需要对注册者进行身份鉴别的任何领域,其编码范围上不封顶,容量可以是无限大的,同样适合作为物联网级应用的编码方案,因此适应性非常强,应用范围非常广泛。一种分层首拼号编码系统方法的出现,彻底解决了汉字因为书写复杂、同音字太多而很少或不推荐作为编码元素的问题,会彻底改变目前字母和数字编码方法不能承载对象信息而使编码就是编码、不容易被使用者记忆的尴尬局面,一种分层首拼号编码系统方法必将给我国汉字的繁荣舔砖加瓦,必将使我国汉字在全球全世界信息化的环境里更加强大。
- 还没有人留言评论。精彩留言会获得点赞!