辨识良率损失的根本原因的系统与方法与流程
本发明是有关于一种辨识良率损失的根本原因的系统与方法,且特别是有关于一种具有可靠度指标的辨识良率损失的根本原因的系统与方法,此可靠度指标是用以评估所辨识出的根本原因的可靠度。
背景技术:
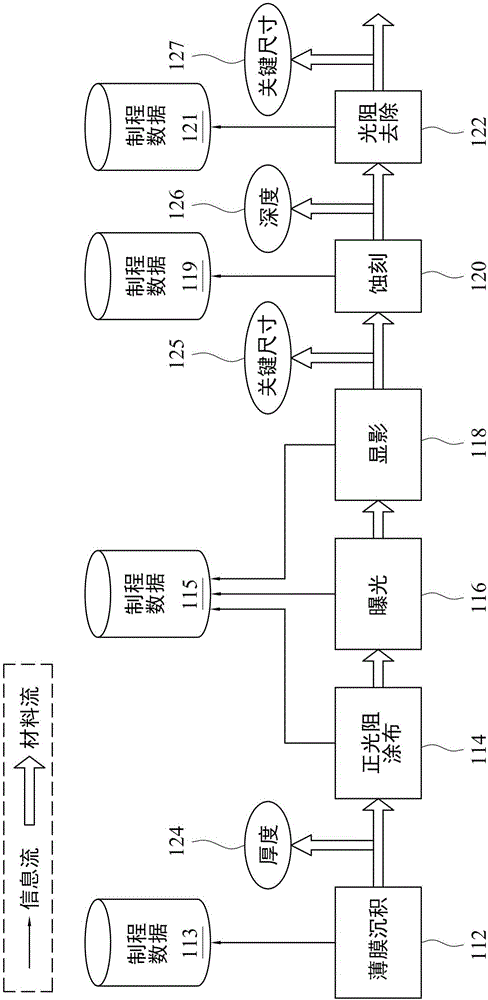
:产品良率会直接影响生产成本。所有的制造者无不寻求在发展和大量生产阶段中迅速地提高产品良率。换言之,当良率损失发生时,必须在研发和大量生产阶段中快速地找出引起此良率损失的根本原因。当遭遇到良率损失时,已知的良率提升方法是收集所有生产相关数据来进行大数据分析,以找出造成良率损失的根本原因并改正这些根本原因。然而,生产相关数据常常是数量庞大且复杂的,因此非常难以从生产相关数据中寻找良率损失的根本原因。随着半导体及薄膜晶体管液晶显示器(TFT-LCD)制造技术的进步,其制程变得愈来愈复杂。因此,如何维持这些复杂的制程的可行的良率便成为一必要的议题。良率管理系统的目标是在提升良率。然而,在研发和产量上升阶段中,工件数量少,使得良率管理系统难以在所有生产机台中找出缺陷的根本原因。因此,如何在有限数量的工件样本情况下于数量众多生产机台中,找出造成良率损失的不良制程机台的关键参数,便成为众所关心的议题。这种挑战即所谓的高维度变数选取(HighDimensionalVariableSelection)问题,其亦标示为p>>n的问题,其中“p”代表半导体及TFT-LCD制程中的制程机台的解释制程相关参数的数量,而另一方面,“n”是半导体及TFT-LCD制程中的成品(被处理的工件)的采样数目。技术实现要素:本发明的一目的是在提供一种可于短时间辨识出良率损失的根本原因的系统与方法。本发明的又一目的是在提供一种信赖指标(RIk),以评估搜寻结果的可靠程度。根据本发明上述目的,提出一种辨识良率损失的根本原因的方法。在此方法中,首先提供一生产线,此生产线包含多个制程站(Stages),每一个制程站包含多个制程机台,这些制程机台分别属于多个制程机台型式,每一个制程机台包含至少一个制程装置,每一制程装置具有多个制程参数,这些制程参数是配置以处理多个工件其中一个工件。然后,根据多个生产路径分别处理工件,每一个生产路径指出在这些制程站中的这些制程机台的这些制程装置其中一个预设装置,用以处理这些工件其中一个工件。接着,对被对应的预设装置处理后的每一个工件进行量测,以获得对应至这些工件的多组线上量测值。然后,对通过生产线后的每一个工件进行至少一个良率测试,以获得分别对应至这些工件的多组最终检查值。接着,根据这些组最终检查值决定是否遭遇一良率测试失败。然后,当遭遇到良率测试失败时,进行一第一阶段,此第一阶段包含一第一根本原因寻找步骤。在第一根本原因寻找步骤中,首先基于一第一演算法来建立一第一搜寻模型,其中此第一演算法为三阶段正交贪婪演算法(TriplePhaseOrthogonalgreedyalgorithm;TPOGA)、最小绝对压缩挑选机制(LeastAbsoluteShrinkageandSelectionOperator;LASSO)演算法、或提高样本使用率的回归树(Sample-EfficientRegressionTrees;SERT)演算法。接着,通过输入这些工件的这些组最终检查值、这些工件的这些组线上量测值和这些工件的这些生产路径至上述的第一搜寻模型中,以从在这些制程站的这些制程机台的这些制程装置中辨识出可能会造成良率测试失败的至少一个第一关键装置。在一些实施例中,在第一阶段中,基于一第二演算法来建立一第二搜寻模型,其中第二演算法与第一演算法不相同,第二演算法为三阶段正交贪婪演算法、最小绝对压缩挑选机制演算法、或提高样本使用率的回归树演算法。接着,通过输入这些工件的这些组最终检查值、这些工件的这些组线上量测值和这些工件的这些生产路径至第二搜寻模型中,以从在这些制程站的此制程机台的这些制程装置中辨识出可能会造成良率测试失败的至少一个第二关键装置。然后,对第一关键装置进行排名与评分,并对第二关键装置进行排名与评分。接着,比较第一关键装置和第二关键装置间的排名的相似度,以获得一第一信心指标,来评估第一关键装置和第二关键装置的辨识结果的可靠程度。在一些实施例中,在第一阶段后,进行一第二阶段,第二阶段包含一第二根本原因寻找步骤,在第二根本原因寻找步骤中,自至少一个第一关键装置选择一个第一关键装置,其中此被选到的第一关键装置是属于这些制程机台型式中的一关键制程机台型式。接着,通过输入这些工件的这些组最终检查值、和在全部的这些制程站上属于此关键制程机台型式的这些制程机台的这些制程装置的全部这些制程参数的数值至第一搜寻模型中,以辨识出可能会造成良率测试失败的多个第一关键制程参数。在一些实施例中,在第二阶段中,通过输入这些工件的这些组最终检查值、和在全部的这些制程站上属于此关键制程机台型式的这些制程机台的这些制程装置的全部这些制程参数的数值至第二搜寻模型中,以辨识出可能会造成良率测试失败的多个第二关键制程参数。接着,对这些第一关键制程参数进行排名与评分,并对这些第二关键制程参数进行排名与评分。然后,比较这些第一关键制程参数和这些第二关键制程参数间的排名的相似度,以获得一第二信心指标,来评估第一关键制程参数和第二关键制程参数的辨识结果的可靠程度。在一些实施例中,对被对应的预设装置处理后的每一个工件进行量测的步骤还包含:对每一个工件进行虚拟量测。在一些实施例中,最小绝对压缩挑选机制演算法包含一自动调整惩罚系数(λ)值的方法。根据本发明上述目的,提出另一种辨识良率损失的根本原因的方法,其中此良率损失是发生在一生产线上,此生产线包含多个制程站,每一个制程站包含至少一个制程机台,此至少一个制程机台属于至少一个制程机台型式其中一者,每一个制程机台包含至少一个制程装置,每一个制程装置具有多个制程参数,这些制程参数是配置以处理多个工件中的一工件。此辨识良率损失的根本原因的方法包含:获得多个生产路径,每一个生产路径指出在这些制程站中的这些制程机台的这些制程装置中的一预设装置,用以处理这些工件中的一工件;接收这些工件的多组线上量测值,其中这些组线上量测值是通过对被预设装置处理后的这些工件进行量测来获得;接收对应至这些工件的多组最终检查值,其中这些组最终检查值是通过对通过此生产线后的每一个工件进行至少一良率测试来获得;根据这些组最终检查值决定是否遭遇一良率测试失败;当遭遇到良率测试失败时,进行一第一阶段,第一阶段包含一第一根本原因寻找步骤。第一根本原因寻找步骤包含:基于一第一演算法来建立一第一搜寻模型,其中此第一演算法为三阶段正交贪婪演算法、最小绝对压缩挑选机制演算法、或提高样本使用率的回归树演算法;以及通过输入这些工件的这些组最终检查值、这些工件的这些组线上量测值和这些工件的这些生产路径至第一搜寻模型中,以从在这些制程站的这些制程机台的这些制程装置中辨识出可能会造成良率测试失败的至少一个第一关键装置。在一些实施例中,在第一阶段后,进行一第二阶段,第二阶段包含一第二根本原因寻找步骤。第二根本原因寻找步骤包含:选择此至少一个第一关键装置的一个第一关键装置,其中此被选到的第一关键装置是属于这些制程机台型式的一关键制程机台型式;以及通过输入这些工件的这些组最终检查值、和在全部的这些制程站上属于此关键制程机台型式的这些制程机台的这些制程装置的全部这些制程参数的数值至第一搜寻模型中,以辨识出可能会造成良率测试失败的多个第一关键制程参数。根据本发明上述目的,提出一种辨识良率损失的根本原因的系统,其中此良率损失是发生在一生产线上,此生产线包含多个制程站,每一个制程站包含至少一个制程机台,此至少一个制程机台属于至少一个制程机台型式中一制程机台型式,每一个制程机台包含至少一个制程装置,每一个制程装置具有多个制程参数,这些制程参数是配置以处理多个工件中的一工件。此辨识良率损失的根本原因的系统包含:记忆体和处理器。此记忆体储存有一生产信息和对应至这些工件的多组最终检查值。此生产信息包含多个生产路径、这些工件的这些制程参数的数值、和这些工件的多组线上量测值,其中每一个生产路径指出在这些制程站中的这些制程机台的这些制程装置中的一预设装置,用以处理这些工件中的一工件,这些组线上量测值是通过对被预设装置处理后的这些工件进行量测来获得,这些组最终检查值是通过对通过生产线后的每一个工件进行至少一个良率测试来获得。处理器是配置以根据这些组最终检查值决定是否遭遇一良率测试失败;当遭遇到良率测试失败时,进行一第一阶段,第一阶段包含一第一根本原因寻找步骤。第一根本原因寻找步骤包含:基于一第一演算法来建立一第一搜寻模型,其中此第一演算法为三阶段正交贪婪演算法、最小绝对压缩挑选机制演算法、或提高样本使用率的回归树演算法;以及通过输入这些工件的这些组最终检查值、这些工件的这些组线上量测值和这些工件的这些生产路径至第一搜寻模型中,以从在这些制程站的这些制程机台的这些制程装置中辨识出可能会造成良率测试失败的至少一个第一关键装置。在一些实施例中,其中在第一阶段后,上述的处理器是配置以进行一第二阶段,第二阶段包含一第二根本原因寻找步骤,第二根本原因寻找步骤包含:选择此至少一第一关键装置的一第一关键装置,其此被选到的第一关键装置是属于这些制程机台型式的一关键制程机台型式;以及通过输入这些工件的这些组最终检查值、和在全部的这些制程站上属于此关键制程机台型式的这些制程机台的这些制程装置的全部这些制程参数的数值至第一搜寻模型中,以辨识出可能会造成良率测试失败的多个第一关键制程参数。在一些实施例中,其中上述的第二阶段还包含:通过输入这些工件的这些组最终检查值、和在全部的这些制程站上属于此关键制程机台型式的这些制程机台的这些制程装置的全部这些制程参数的数值至第二搜寻模型中,以辨识出可能会造成良率测试失败的多个第二关键制程参数;对这些第一关键制程参数进行排名与评分;对这些第二关键制程参数进行排名与评分;以及比较这些第一关键制程参数和这些第二关键制程参数间的排名的相似度,以获得一第二信心指标,来评估这些第一关键制程参数和这些第二关键制程参数的辨识结果的可靠程度。因此,应用本发明实施例,可于短时间辨识出生产线上的良率损失的根本原因,并可有效地评估搜寻结果的可靠程度。附图说明为了更完整了解实施例及其优点,现参照结合所附附图所做的下列描述,其中图1A为绘示根据本发明一些实施例的生产线的示意图;图1B为绘示根据本发明一些实施例在制程站上的例示制程机台型式的示意图;图1C为绘示根据本发明一些实施例的例示制程机台的示意图;图2为绘示根据本发明一些实施例的辨识良率损失的根本原因的系统示意图;图3为绘示根据本发明一些实施例的自动调整惩罚系数(λ)值的方法的流程示意图;以及图4为绘示根据本发明一些实施例的辨识良率损失的根本原因的方法流程示意图。具体实施方式以下仔细讨论本发明的实施例。然而,可以理解的是,实施例提供许多可应用的发明概念,其可实施于各式各样的特定内容中。所讨论的特定实施例仅供说明,并非用以限定本发明的范围。请参照图1A至图1C,图1A为绘示根据本发明一些实施例的一生产线100的示意图,其中以TFT制程为例子;图1B为绘示根据本发明一些实施例在制程站上的例示制程机台型式的示意图,其中以“栅极层”为例子;图1C为绘示根据本发明一些实施例的例示制程机台的示意图,其中以沉积机台为例子。本发明实施例是针对辨识引起发生在生产线100上的良率损失的根本原因,生产线100包含多个制程站110、130、140、150和160,每一个制程站110、130、140、150和160包含一或多个制程机台(未绘示),制程机台分别属于一或多个制程机台型式112、114、116、118、120和122。举例而言,如图1B所示,每一个制程站110、130、140、150和160包含具有制程机台型式112、114、116、118、120和/或122的制程机台。每一个制程机台包含至少一个制程装置。例如:每一个制程机台包含至制程装置112a、112b、112c、112d、112e和112f。例如:在TFT-LCD厂中,生产线100可被设置来进行TFT制程,而制程站110(站I)、130(站II)、140(站III)、150(站IV)和160(站V)可为“栅极层”、“半导体层”、“数据层”、“保护层”、和“氧化铟锡(ITO)层”。“栅极层”(制程站110)包含用以进行所谓的显影制程(PhotoEngravingProcess;PEP)的制程机台,这些制程机台分别属于如薄膜沉积(制程机台型式112)、正光阻涂布(制程机台型式114)、曝光(制程机台型式116)、显影(制程机台型式118)、蚀刻(制程机台型式120)和光阻去除(制程机台型式122)等制程机台型式。每一个制程机台包含至制程装置112a、112b、112c、112d、112e和112f。在生产时,每一个工件逐一通过制程站110、130、140、150和160,最后并受到最终测试(良率测试),以获得分别对应至这些工件的多组最终检查值。然后,这些组最终检查值被来决定是否遭遇到良率测试失败。良率测试可能遭遇型1至型10的良率损失,这些良率损失是由各种缺陷所造成,而这些缺陷是由电性测试失败、粉尘污染等所引起。在每一个制程站110、130、140、150和160上,每一个工件逐一被制程机台型式112、114、116、118、120和122的制程机台所处理,而每一个工件只在每一个制程机台的一个制程装置中被处理。当每一个工件在制程机台型式112、114、116、118、120或122的制程机台的一预定制程装置中被处理后,对此工件进行量测,以获得分别对应至工件的多组线上(In-line)量测值,其中对此工件所进行的量测方式可为虚拟量测或由量测机台所进行的实际量测,如图1B所示的线上量测值124(厚度)、125(关键尺寸)、126(深度)和127(关键尺寸)。当每一个工件在一个制程装置中被处理时,使用例如感应器来收集制程装置的多个制程参数的数值,如图1B所示的制程数据113、115、119和121。请参照图2,图2为绘示根据本发明一些实施例的辨识良率损失的根本原因的系统200的示意图。系统200包含记忆体202和处理器206。处理器206可包含任何型式的处理器、微处理器、或可编译并执行指令的场效型可编程逻辑阵列(FieldProgrammableGateArray;FPGA)。处理器206可包含单一装置(例如单核心)或一组装置(例如多核心)。记忆体202可包含可储存供处理器206执行的信息和指令的随机存取记忆体(RandomAccessMemory;RAM)或其它型式的动态储存装置。数据库可用以储存生产信息204、缺陷(D)和多组最终检查值(Y),其稍后将被载入至记忆体202中,以供处理器206执行。记忆体202储存有生产信息204、缺陷(D)、和对应至在生产线100(如图1A)中被处理的工件的最终检查值(Y)。生产信息包含多个生产路径(XR)、处理工件的制程参数(XP)的数值、和工件的多组线上量测值(y),其中每一个生产路径指出在制程站中的制程机台的制程装置中的一个预设装置,用以处理一工件,如图1A至图1C所示的“在制程站110上制程机台型式112的制程机台的制程装置112a”。这些组线上量测值(y)的获得是透过对被对应的预设装置处理后的工件进行量测,而这些组最终检查值(Y)的获得是透过对通过生产线后的每一个工件进行至少一个良率测试。缺陷(D)可能会发在任何制程站中,故亦输入来进行分析。然后,被处理过的缺陷(D)可依据缺陷(D)的本质加入至生产信息204或最终检查值(Y)。根本原因寻找步骤240的输出是三阶段正交贪婪演算法(TPOGA)242的输出KSO、最小绝对压缩挑选机制(LASSO)演算法244的输出KSL和其伴随的信赖指标RIk。在一些实施例中,提高样本使用率的回归树(SERT)演算法可用以取代TPOGA242或LASSO244。值得注意的是,根本原因寻找步骤240使用两种不同的演算法,如TPOGA/LASSO、TPOGA/SERT、或LASSO/SERT。以下说明TPOGA、LASSO和SERT。贪婪演算法是一种逐步回归法(StepwiseRegressionMethod),其考虑到所有引起良率损失的参数(X)和最终检查值(Y)间的关系。在本发明实施例中,X包含与所有生产有关的变数:XR、XP、和y;而Y代表最终检查结果(值)。在此可使用纯贪婪演算法(Puregreedyalgorithm;PGA)和正交贪婪演算法来解决高维度回归问题。然而,在高维度线性回归中,正交贪婪演算法优于纯贪婪演算法。在本发明实施例中,将正交贪婪演算法、高维信息准则(highdimensionalinformationcriterion;HDIC)和修剪(Trimming)的程序结合成所谓的三阶段正交贪婪演算法(TPOGA)。本发明实施例所使用的TPOGA的细节可参考C.-K.Ing和T.L.Lai的论文(“Astepwiseregressionmethodandconsistentmodelselectionforhigh-dimensionalsparselinearmodels”,StatisticaSinica,vol.21,pp.1473-1513,2011),本发明的实施例引用此C.-K.Ing和T.L.Lai的论文的相关规定(Incorporatedbyreference),其中Ing和Lai揭示终止条件和HDIC,以沿着具有适当选取准则的最小值的OGA路径进行选取。与逐步回归不同,LASSO是一种收缩(Shrinkage)方法,其令系数的绝对值总和小于一常数,使残值平方和最小化。由于此常数的本质,LASSO倾向于产生一些刚好为0的系数,因而提供可解释(解释力较强)的模型。LASSO与通常的逐步回归间的重大差异是:透过LASSO可同时处理所有的独立变数,但逐步回归无法时处理所有的独立变数。本发明实施例所使用的LASSO的细节可参考R.Tibshirani的论文(“RegressionshrinkageandselectionviatheLASSO",J.RoyalStatisticalSoc.B,vol.58,no.1,pp.267-288,1996”)和TrevorHastie、RobertTibshirani与JeromeFriedman的论文(“Theelementsofstatisticallearning:datamining,inference,andprediction”,Springer,NewYork,2009”),本发明的实施例引用此R.Tibshirani的论文及TrevorHastie、RobertTibshirani与JeromeFriedman的论文的相关规定(Incorporatedbyreference)。为了减少设定惩罚系数(λ)值的困惑并获得适当结果,本发明实施例的LASSO演算法包含一自动调整惩罚系数(λ)值的方法。请参照图3,其为绘示根据本发明一些实施例的自动调整惩罚系数(λ)值的方法的流程示意图。如图3所示,在步骤310中,将惩罚系数(λ)的初始值设为5或任何合适值。在步骤320中,执行LASSO。在步骤330中,选定重要变数的适当的目标数量(Target#KV,例如:10),然后检查重要变数的数量(#KV)是否等于Target#KV。在本发明实施例中,重要变数为引起良率损失的制程站或制程参数。当步骤330的结果为否时,进行步骤340以重新计算惩罚系数(λ)。Target#KV是用来避免捡到太多不需要的变数。在步骤340中,定义Lowerbound为惩罚系数(λ)的下限。Lowerbound是设为0(因为λ≧0)。若#KV<Target#KV,则λnew=(λold+Lowerbound)/2。另一方面,若#KV>Target#KV,则λnew=λold+(λold+Lowerbound)/2,并重新指定Lowerbound=λold。然后,回到步骤320。当步骤330的结果为是时,进行步骤350。在步骤350中,依据重要性由大至小对重要变数(KeyVariables;KV)进行排序。然后,进行步骤360,以输出排序后的重要变数为结果。SERT结合回归分析中的向前选取(ForwardSelection)和回归树(RegressionTree)的方法。相较于如分类与回归树演算法(ClassificationAndRegressionTree;CART)的已知决策树,SERT可处理在所谓的高维度变数选取(p>>n)问题中的组合效应。本发明实施例所使用的SERT的细节可参考A.Chen和A.Hong的论文(“Sample-efficientregressiontrees(SERT)forsemiconductoryieldLossAnalysis”,IEEETransactionsonSemiconductorManufacturing,vol.23,no.3,August2010),本发明的实施例引用此A.Chen和A.Hong的论文的相关规定(Incorporatedbyreference)。如图2所示,在进行根本原因寻找步骤240前,需要进行数据前处理步骤210、220和230,以确认所有输入:生产信息(XR、XP和y)、缺陷(D)和最终检查(Y)的品质。以下说明这些输入的特性。XR必须被离散化(Discretized)为1或0,其指出工件是否有通过此制程站。XP包含机台的制程参数(如电压、压力、温度等)的数据,其需被中心化(Centralized)。至于缺陷(D),不同的公司有不同的缺陷定义,因此在执行数据前处理和数据捡查前必须与领域专家讨论。最终检查(Y)代表良率测试结果,其需被中心化。XR的数据品质评估演算法(标示为)评估下列四个事实:1)虽然一个制程站可包含多个同样型式的制程机台,但此制程站只使用其中一个制程机台;若一个生产线应通过三个同样制程机台型式的制程机台,则此生产线具有三个制程站,此三个制程机台分别位于此三个制程站上;2)若一个制程机台被使用于不同的生产线上,则在不同生产线上的同样装置会被视为一个不同的制程站;3)对通过制程机台的一工件而言只有两种可能:通过(“1”)或不通过(“0”);4)一工件不能通过不属于其制程站的制程机台。类似地,XP和y的数据品质评估演算法分别标示为和Y的数据品质评估演算法标示为DQIY。和采用类似于美国专利前案第8095484B2号所使用的制程数据品质评估方法,而DQIY亦应用类似于美国专利前案第8095484B2号所使用的量测数据品质评估方法。本发明的实施例引用此美国专利前案第8095484B2号的相关规定(Incorporatedbyreference)。处理器206是配置以根据最终检查值来决定是否遭遇一良率测试失败,并在遭遇到良率测试失败时,进行根本原因寻找步骤240。在一些实施例中,分别以不同的演算法(如TPOGA242和LASSO244)进行两次根本原因寻找步骤240,借以进行步骤250来计算一信心指标(RIk),此信心指标(RIk)的计算是通过比较基于TPOGA242和LASSO244的结果间的排名的相似度。信心指标(RIk)是用来评估基于TPOGA242和LASSO244的辨识结果的可靠程度。通过比较基于TPOGA242和LASSO244的结果并考虑到重叠与权重,重新计算RIk并设定RIk至0-1之间。以RIkT=0.7为门槛值,若RIk大于RIkT,则代表获得优良的结果;否则,需重新检查辨识结果。稍后说明计算信心指标(RIk)的步骤250。本发明实施例提供一种双阶段处理过程,以辨识生产线100上的良率损失的根本原因。在第一阶段中,辨识出可能会造成良率损失的制程机台与其所属的制程站。在第二阶段中,辨识出在第一阶段所发现的制程站中可能会造成良率损失的制程参数。在每一个阶段中,可使用两个不同的演算法来产生信心指标(RIk),以评估本发明的搜寻结果的可靠程度。请参照图1A、图1B、图1C和图4,图4为绘示根据本发明一些实施例的辨识良率损失的根本原因的方法流程示意图。首先,进行步骤400,以根据最终检查值来决定是否遭遇一良率测试失败。当遭遇到良率测试失败时,进行一第一阶段402。在第一阶段402中,进行第一根本原因寻找步骤410,以辨识出那一个制程机台最可能会引起良率测试失败(良率损失)。在第一根本原因寻找步骤410中,首先基于第一演算法来建立第一搜寻模型,其中第一演算法为三阶段正交贪婪演算法(TPOGA)、最小绝对压缩挑选机制(LASSO)演算法、或提高样本使用率的回归树(SERT)演算法,例如:图2所示的TPOGA242。然后,输入一组第一数据40至第一搜寻模型中,以从制程站110、130、140、150和160上的制程机台的制程装置112a-112f中辨识出可能会造成良率测试失败的至少一个第一关键装置(例如:在制程站110上属于制程机台型式112的制程机台的制程装置112a)。此组第一数据40工件的最终检查值(Y)、工件的线上量测值(y)和工件的生产路径(XR)所组成。第一搜寻模型(TPOGA)的结果KSO的一个例子是列示于表1,其中列示出TPOGA所找到的最可能会引起良率损失的前10名制程机台(第一关键装置),“制程机台型式”简称为“机台型式”,“制程装置”简称为“装置”。选序由TPOGA所获得的第一关键装置1站4:CVD:Eq7ChB(制程站150:机台型式112:装置112b)2站2:CVD:EqAChA(制程站130:机台型式112:装置112a)3站4:CVD:Eq7ChC(制程站150:机台型式112:装置112c)4站4:CVD:Eq7ChD(制程站150:机台型式112:装置112d)5站2:CVD:EqAChB(制程站130:机台型式112:装置112b)6站4:CVD:Eq7ChE(制程站150:机台型式112:装置112e)7站2:CVD:EqAChC(制程站130:机台型式112:装置112c)8站1:CVD:Eq1ChA(制程站120:机台型式112:装置112a)9站4:CVD:Eq7ChA(制程站150:机台型式112:device112a)10站2:CVD:EqAChD(制程站130:机台型式112:device112d)表1在表1中,引起良率损失的装置的可能性是由选序1至选序10依序减少。如表1所示,制程站150(站4)上机台型式112的机台(Eq7)的制程装置112b(CVD)为选序1,其最可能会引起良率损失。在第一根本原因寻找步骤410完成后,可选择性地进行第一信赖指标(RIk)步骤420,以评估基于第一演算法(例如TPOGA)的第一根本原因寻找步骤410的搜寻结果的可靠程度。在第一信赖指标(RIk)步骤420中,首先基于第二演算法来建立第一搜寻模型。第二演算法与步骤410所使用的第一演算法不同,其中为第二演算法三阶段正交贪婪演算法(TPOGA)、最小绝对压缩挑选机制(LASSO)演算法、或提高样本使用率的回归树(SERT)演算法,例如:第一演算法为图2所示的TPOGA242,第二演算法为图2所示的LASSO244,其中LASSO244为包含一自动调整惩罚系数(λ)值方法的LASSO演算法,即ALASSO。然后,输入上述的第一数据40至第二搜寻模型中,以从制程站110、130、140、150和160上的制程机台的制程装置112a-112f中辨识出可能会造成良率测试失败的至少一个第二关键装置(例如:在制程站110上属于制程机台型式112的制程机台的制程装置112a)。第二搜寻模型(ALASSO)的结果KSL的一个例子是列示于表2,其中列示出ALASSO所找到的最可能会引起良率损失的前10名制程机台(第二关键装置),“制程机台型式”简称为“机台型式”,“制程装置”简称为“装置”。选序由ALASSO所获得的第二关键装置1站4:CVD:Eq7ChB(制程站150:机台型式112:装置112b)2站2:CVD:EqAChA(制程站130:机台型式112:装置112a)3站4:CVD:Eq7ChC(制程站150:机台型式112:装置112c)4站1:CVD:Eq1ChD(制程站110:机台型式112:装置112d)5站1:CVD:Eq1ChE(制程站110:机台型式112:装置112e)6站2:CVD:EqAChB(制程站130:机台型式112:装置112b)7站4:CVD:Eq7ChA(制程站150:机台型式112:装置112a)8站4:CVD:Eq7ChE(制程站150:机台型式112:装置112e)9站2:CVD:EqAChE(制程站130:机台型式112:device112e)10站2:CVD:EqAChD(制程站130:机台型式112:device112d)表2接着,对表1所列示的第一关键装置和表2所列示的第二关键装置进行排名与评分。因为较早被选到的关键装置较重要,TPOGA和ALASSO所找到的关键装置的顺序是重要的,故权重的指定不仅是根据顺序亦根据80/20法则,以确保较高的分数给决定性的少数。结果是,最终分数为其中OSl为原始分数,FSl为最终分数,而l为=1、2、…、10的选序。本发明实施例并不限于上述的80/20法则,其他的评分方法亦可被应用至本发明实施例。在进行公式(1)的计算后,第一关键装置和第二关键装置的最终分数的一个例子是列示于表3和表4。选序(l)由TPOGA所获得的第一关键装置最终分数(FSOl)1站4:CVD:Eq7ChB0.8*(1.0/2.7)=0.2962站2:CVD:EqAChA0.8*(0.9/2.7)=0.2673站4:CVD:Eq7ChC0.8*(0.8/2.7)=0.2374站4:CVD:Eq7ChD0.2*(0.7/2.8)=0.0505站2:CVD:EqAChB0.2*(0.6/2.8)=0.0436站4:CVD:Eq7ChE0.2*(0.5/2.8)=0.0367站2:CVD:EqAChC0.2*(0.4/2.8)=0.0298站1:CVD:Eq1ChA0.2*(0.3/2.8)=0.0219站4:CVD:Eq7ChA0.2*(0.2/2.8)=0.01410站2:CVD:EqAChD0.2*(0.1/2.8)=0.007表3表4然后,比较第一关键装置和第二关键装置间的排名(选序)的相似度,以获得一第一信心指标(RIk),来评估第一关键装置和第二关键装置的辨识结果的可靠程度。以下说明计算RIk的经验法则。若某一关键装置已被TPOGA和ALASSO以相同的循序选序选到,则此关键装置的分数被算入。若某一关键装置已被TPOGA和ALASSO以不同的循序选序选到,则此关键装置的分数亦被算入。若TPOGA和ALASSO选到不同的关键装置而没有重叠,则这些关键装置的分数不被算入。因此,搜寻结果的RIk是被公式(2)所计算。若Oi=Lj(2)其中基于表3和表4的RIk结果是0.932,其大于一门槛值RIkT(例如:0.7)。门槛值RIkT可依实际需要而有所不同。此表示TPOGA和ALASSO的搜寻结果几乎相同,因此其搜寻结果是可靠的。如表3和表4所示,第一最关键的装置(Top1Device)是保护层(站)上薄膜沉积制程的机台7的反应室B(站4:CVD:Eq7ChB),而第二最关键的装置(Top2Device)是半导体层(站)上薄膜沉积制程的机台A的反应室A(站2:CVD:EqAChA)。与工厂测试数据做比较,在28个工件中,8个具有第2型良率损失的工件样本中有3个是被上述的第一最关键的装置所处理,而8个具有第2型良率损失的工件样本中另有3个是被上述的第二最关键的装置所处理。因此,第一根本原因寻找步骤410的结果与工厂测试数据相符。在步骤410或步骤420后,进行第二阶段404。在第二阶段404中,进行第二根本原因寻找步骤430,以辨识出那些制程参数可能会引起良率损失。在步骤430中,首先自第一关键装置中选择一个关键装置,或自第二关键装置中选择一个关键装置,其中此关键装置属于制程机台型式的一关键制程机台型式。然后,输入一组第二数据42至上述的第一搜寻模型中,以辨识出可能会引起良率测试失败的多个第一关键制程参数,其中此组第二数据42是由工件的最终检查值(Y)、和在全部制程站上属于关键制程机台型式的制程机台的制程装置的全部制程参数(XP)的数值所组成。以下选择第二最关键的装置(站2:CVD:EqAChA)来举例说明。第二最关键的装置的制程数据包含有27个制程参数(XP)。在对第二最关键的装置所属的相同制程机台型式的制程机台进行使用第一搜寻模型的分析后,找到第一关键制程参数“控制电压”、“电流”和“直流电压”为造成良率损失的根本原因。在第二根本原因寻找步骤430完成后,可选择性地进行第二信赖指标(RIk)步骤440,以评估第二根本原因寻找步骤430的搜寻结果的可靠程度。在第二信赖指标(RIk)步骤440中,输入上述的第二数据42至第二搜寻模型中,以辨识出可能会造成良率测试失败的多个第二关键制程参数。在对第二最关键的装置所属的相同制程机台型式的制程机台进行使用第二搜寻模型的分析后,找到第二关键制程参数“控制电压”、“电流”和“流速”为造成良率损失的根本原因。接着,比较第一关键制程参数和第二关键制程参数间的排名的相似度,以获得一第二信心指标(RIk),来评估第一关键制程参数和第二关键制程参数的辨识结果的可靠程度。例如:关键制程参数的第二信心指标(RIk)为0.867(>0.7)。因此,搜寻结果中第一最关键的参数(Top1parameter)为“控制电压”。接着,在步骤450中,发出一通知至相关部门,以修正问题并持持续改善。可理解的是,本发明的量测抽样方法为以上所述的实施步骤,本发明的内储用于量测抽样的计算机程序产品,是用以完成如上述的量测抽样的方法。上述实施例所说明的各实施步骤的次序可依实际需要而调动、结合或省略。上述实施例可利用计算机程序产品来实现,其可包含储存有多个指令的机器可读取媒体,这些指令可编程(programming)计算机来进行上述实施例中的步骤。机器可读取媒体可为但不限定于软盘、光盘、只读光盘、磁光盘、只读记忆体、随机存取记忆体、可抹除可编程只读记忆体(EPROM)、电子可抹除可编程只读记忆体(EEPROM)、光卡(opticalcard)或磁卡、快闪记忆体、或任何适于储存电子指令的机器可读取媒体。再者,本发明的实施例也可做为计算机程序产品来下载,其可通过使用通讯连接(例如网路连线之类的连接)的数据信号来从远程计算机转移本发明的计算机程序产品至请求计算机。亦可注意的是,本发明亦可描述于一制造系统的语境中。虽然本发明可建置在半导体制作中,但本发明并不限于半导体制作,亦可应用至其他制造工业。制造系统是配置以制造工件或产品,工件或产品包含但不受限于微处理器、记忆体装置、数字信号处理器、专门应用的电路(ASICs)或其他类似装置。本发明亦可应用至除半导体装置外的其他工件或产品,如车辆轮框、螺丝。制造系统包含一或多个处理工具,其可用以形成一或多个产品或产品的一部分,在工件(例如:晶圆)上或中。发明本领域具有通常技艺者应可知,处理工具可为任何数目和任何型式,包含有微影机台、沉积机台、蚀刻机台、研磨机台、退火机台、工具机和类似工具。在实施例中,制造系统亦包含散射仪、椭圆偏光仪、扫描式电子显微镜和类似仪器。由上述本发明实施方式可知,通过双阶段处理过程来寻找生产线的良率损失的根本原因,可于短时间从数量庞大的可能原因中辨识出根本原因。在每一个阶段中,可使用信赖指标(RIk)来评估搜寻结果的可靠程度。虽然本发明已以实施方式揭露如上,然其并非用以限定本发明,任何熟悉此技艺者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰,因此本发明的保护范围当视所附的权利要求书所界定的范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1