基于BP_Adaboost模型的信用卡用户违约的预测方法及系统与流程
本发明涉及一种预测方法及系统,特别是涉及一种基于BP_Adaboost模型的信用卡用户违约的预测方法及系统。
背景技术:
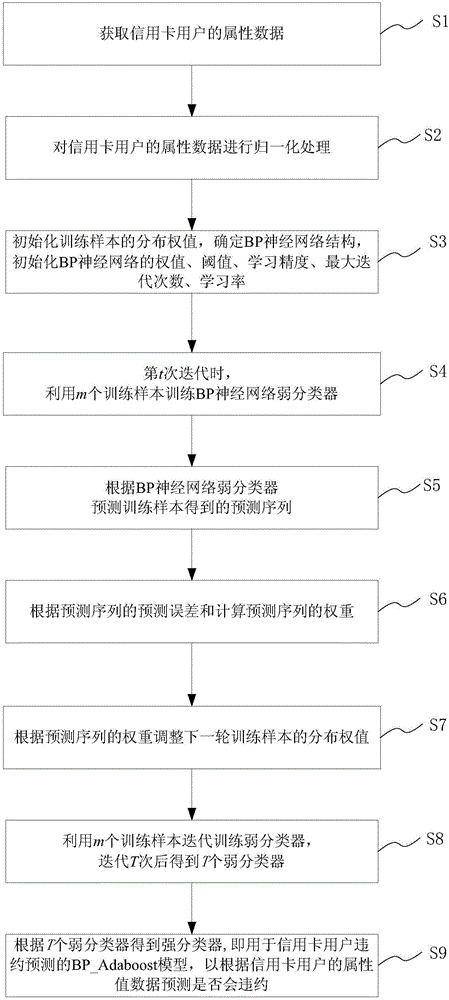
:随着金融业、银行业的发展,信用卡的使用也越来越广泛,给消费者的生活带来了很多便利。然而,信用卡的不安全因素也暴露无遗,例如,很多信用卡发行银行为了增加市场份额,超额发行现金和信用卡给不合格的申请者。同时,大多数的信用卡持有者不考虑其偿还能力,在消费上过度使用信用卡,积累了大量的信用卡债务,给发卡银行造成了巨大的损失。信用卡违约风险是由持卡人做出部分或全部支付的承诺时潜在的支付失败驱动的,它在持卡人在还款期限内出现资金紧张或不愿意偿还时发生。在一个健全的财务系统中,风险管理是在下游,而风险预测是在上游。风险预测的主要目的是利用企业绩效或者个人客户的信用风险,来降低风险和不确定性,因而具有很大的现实意义和价值。目前,对于违约风险,银行往往是利用传统的“评分系统”或者所谓“专家评分”来确定申请者风险水平。具体地,对信用卡持有人的信息数据进行评分,对不同的属性如年龄、职业、学历、收入及其在外部征信系统中的信用历史记录信息,根据其在违约预测方面的重要程度不同,予以不同的分值,以评分结果来预测持卡人在未来一定时期内用卡发生违约拖欠的概率。这种传统的评分方法,因为人的参与程度很大,所以具有很大的随意性和不稳定性。数据挖掘作为一种发现驱动型的知识发现技术,主要针对非常大型的数据进行研究和分析,采用自动或半自动的程序找出先前未知的、有趣的、可理解的隐含信息。利用数据挖掘方法,银行可以方便地部署一个预测模型,快速而有效地分析大量信用卡持有者的违约状况,已成为信用卡分析的重要工具。为了降低信用评价中的主观因素影响和反映信用的动态变化,判别分析、逻辑回归、分类树和神经网络法等方法逐渐被应用到信用评价领域,对信用卡用户的违约行为进行预测。判别分析(Discriminantanalysis,DA)又称分辨法,是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。判别分析的基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标,据此即可预测某一客户样本属于“好”客户还是违约用户。逻辑回归(LogisticregressionLR)可以被看作是线性回归模型的一种特例。该方法能产生一个简单的分类概率公式,判断样本属于各个类别的概率,但其缺点在于不能很好的处理非线性问题以及解释变量之间的交互性影响。分类树方法(ClassificationTrees,CTs)是一种非参数统计方法,利用这种方法建立的信用卡违约预测模型并不是生成一个线性的评分表,其基本思想是按照某个特征变量的取值将客户总体分成两个子组,使得在不同组之间客户的违约概率差距尽量地大,而同一组内客户的违约概率尽量一致,然后再对这些子组进行而划分,达到一定的要求前,一直不断的重复这一过程,最后终止。整个过程可以用一个树状结构来表示,按照一定的规则,将每个根节点划分为“好”客户或“违约”客户。人工神经网络具备其他很多数据挖掘方法不具备的优势,因其非线性假设、泛化能力和映射能力等,在很多领域都得到了应用。其中BP(BackPropagation,反向传播)神经网络的应用最为广泛。BP网络是1986年由Rinehart和McClelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,它具有强大并行处理机制,高度自学习、自适应能力。而且BP神经网络算法非常的灵活,因为其内部的很多参数都是可以调节的。BP神经网络算法的主要设计思想是:首先输入信号通过隐藏层和输出层节点的处理计算,得到网络的实际输出,随后将其与期望得到的输出相比较,并计算实际输出与期望输出的误差;然后将误差作为修改权值的依据反向传播至输入层。这一过程中,计算输出层、隐藏层的权值、阈值增益,并更新权值、阈值,反复这一过程,直到实际输出与期望输出的误差达到预先设定的误差收敛标准或者达到最高迭代次数,从而获得最终的网络权值,构建信用卡违约预测模型,对样本进行预测。上述方法在信用卡违约预测方面,都能实现一定的准确率,但都忽略了信用卡数据的不均衡性,也就是违约客户的样本与诚实客户的样本数目相差太大的问题。Boosting是一种提高任意给定学习算法准确度的方法,其思想起源于Valiant提出的PAC(ProbablyApproximatelyCorrect)学习模型。1995年,Freund和Schapire改进了Boosting算法,提出了AdaBoost(AdaptiveBoosting)算法,Adaboost算法的核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。因此,Adaboost算法对不平衡数据集有着很好的鲁棒性,同时可以加强分类效果,进一步提高神经网络的泛化能力。该算法效率和Freund于1991年提出的Boosting算法几乎相同,但不需要任何关于弱学习器的先验知识,因而更容易应用到实际问题当中。使用Adaboost分类器可以排除一些不必要的训练数据特征,并将重点放在关键的训练数据上面。在产生单个的基分类器时可用相同的分类算法,也可用不同的分类算法。这些算法一般是不稳定的弱分类算法,如BP算法。因此,如何结合BP算法和Adaboosting算法来对信用卡用户进行违约预测成为一个极具前景的课题。技术实现要素:鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于BP_Adaboost模型的信用卡用户违约的预测方法及系统,基于BP算法和Adaboosting算法,根据银行信用卡用户的历史信用信息进行数据分析、训练,建立BP_AdaBoost模型,从而实现对新的信用卡用户是否会违约的预测。为实现上述目的及其他相关目的,本发明提供一种基于BP_Adaboost模型的信用卡用户违约的预测方法,包括以下步骤:获取信用卡用户的属性数据,所述信用卡用户的属性为信用卡用户的信用评价指标;对信用卡用户的属性数据进行归一化处理,并将归一化后的每个用户的属性数据作为一个样本,将所有样本分为训练样本集和测试样本集;初始化训练样本的分布权值D1(i)=1/m,m为训练样本总数,i=1,2...m表示训练样本序号,根据训练样本输入、输出维数确定BP神经网络结构,初始化BP神经网络的权值、阈值、学习精度、最大迭代次数、学习率;第t次迭代时,利用m个训练样本训练BP神经网络弱分类器ft;根据BP神经网络弱分类器ft预测训练样本得到的预测序列gt,计算预测误差和其中i为gt(xi)≠yi时所对应的训练样本序号,xi为m个训练样本中第i个样本点;gt(xi)为BP神经网络弱分类器ft对样本点xi的预测分类结果;yi为BP神经网络弱分类器ft对样本点xi的期望分类结果;根据预测序列的预测误差和et计算预测序列的权重根据预测序列的权重at调整下一轮训练样本的分布权值为i=1,2...m,其中Bt是归一化因子;利用m个训练样本迭代训练BP神经网络弱分类器,迭代T次后得到T个BP神经网络弱分类器;T为自定义参数;根据T个弱分类器得到强分类器即用于信用卡用户违约预测的BP_Adaboost模型,以根据信用卡用户的属性数据预测是否会违约。于本发明一实施例中,所述信用卡用户的属性包括个人信贷额度、性别、教育程度、婚姻状况、年龄、近几个月的偿还记录、近几个月的账单金额和近几个月的实际还款金额。于本发明一实施例中,对信用卡用户的属性数据进行归一化处理时,采用如下公式:其中i=1,2,3,…m;j=1,2,3,…n;m为样本总数,n为属性个数;xij'表示归一化后第i个样本的第j个属性值,xij表示第i个样本的第j个属性值;max(j)表示m个样本中第j个属性的最大值,max(i)表示m个样本中第i个样本的最大值;min(j)表示m个样本中第j个属性的最小值,min(i)表示m个样本中第i个样本的最小值。于本发明一实施例中,还包括利用测试样本,检测所述用于信用卡用户违约预测的BP_Adaboost模型的性能。于本发明一实施例中,所述最大迭代次数为50次,T取值为10。同时,本发明还提供一种基于BP_Adaboost模型的信用卡用户违约的预测系统,包括获取模块、归一化模块、初始化模块、训练模块、预测误差和计算模块、权重计算模块、分布权值计算模块、迭代模块和预测模块;所述获取模块用于获取信用卡用户的属性数据,所述信用卡用户的属性为信用卡用户的信用评价指标;所述归一化模块用于对信用卡用户的属性数据进行归一化处理,并将归一化后的每个用户的属性数据作为一个样本,将所有样本分为训练样本集和测试样本集;所述初始化模块用于初始化训练样本的分布权值D1(i)=1/m,m为训练样本总数,i=1,2...m表示训练样本序号,根据训练样本输入、输出维数确定BP神经网络结构,初始化BP神经网络的权值、阈值、学习精度、最大迭代次数、学习率;所述训练模块用于在第t次迭代时,利用m个训练样本训练BP神经网络弱分类器ft;所述预测误差和计算模块用于根据BP神经网络弱分类器ft预测训练样本得到的预测序列gt,计算预测误差和其中i为gt(xi)≠yi时所对应的训练样本序号,xi为m个训练样本中第i个样本点;gt(xi)为BP神经网络弱分类器ft对样本点xi的预测分类结果;yi为BP神经网络弱分类器ft对样本点xi的期望分类结果;所述权重计算模块用于根据预测序列的预测误差和et计算预测序列的权重所述分布权值计算模块用于根据预测序列的权重at调整下一轮训练样本的分布权值为其中Bt是归一化因子;所述迭代模块用于利用m个训练样本迭代训练BP神经网络弱分类器,迭代T次后得到T个BP神经网络弱分类器;T为自定义参数;所述预测模块用于根据T个弱分类器得到强分类器即用于信用卡用户违约预测的BP_Adaboost模型,以根据信用卡用户的属性数据预测是否会违约。于本发明一实施例中,所述信用卡用户的属性包括个人信贷额度、性别、教育程度、婚姻状况、年龄、近几个月的偿还记录、近几个月的账单金额和近几个月的实际还款金额。于本发明一实施例中,所述归一化模块对信用卡用户的属性数据进行归一化处理时,采用如下公式:其中i=1,2,3,…m;j=1,2,3,…n;m为样本总数,n为属性个数;xij'表示归一化后第i个样本的第j个属性值,xij表示第i个样本的第j个属性值;max(j)表示m个样本中第j个属性的最大值,max(i)表示m个样本中第i个样本的最大值;min(j)表示m个样本中第j个属性的最小值,min(i)表示m个样本中第i个样本的最小值。于本发明一实施例中,还包括检测模块,用于利用测试样本,检测所述用于信用卡用户违约预测的BP_Adaboost模型的性能。于本发明一实施例中,所述最大迭代次数为50次,T取值为10。如上所述,本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法及系统,具有以下有益效果:(1)基于BP算法和Adaboosting算法,根据银行信用卡用户的历史信用信息进行数据分析、训练,建立BP_AdaBoost模型,从而根据新的信用卡用户的相关信用指标,对其是否违约进行预测与判定;(2)节省了银行人员的大量决策时间、并可辅助其做出最佳决策,从而有效地规避相关风险;(3)BP_Adaboost模型对不平衡数据集有很好的处理能力,进一步提高神经网络的泛化能力,提升了信用卡用户违约预测的准确度。附图说明图1显示为单隐藏层BP神经网络模型的结构示意图;图2显示为本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法的流程图;图3显示为本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法的一个实施例中实验结果的ROC曲线示意图;图4显示为本发明的基于BP_Adaboost模型的信用卡用户违约的预测系统的结构示意图。元件标号说明1获取模块2归一化模块3初始化模块4训练模块5预测误差和计算模块6权重计算模块7分布权值计算模块8迭代模块9预测模块具体实施方式以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。如图1所示,BP神经网络由输入层(I)、隐层(H)和输出层(O)组成。其中,X、Z分别表示网络的输入、输出,每一神经元用一个节点表示。BP算法由信息的正向传递与误差的反向传播组成。信息的正向传递过程中,输入信息从输入层经隐含层逐层计算传向输出层,每一层神经元的状态只影响下一层神经元的状态。如果在输出层没有得到期望输出,则计算输出层的误差变化值,然后转向反向传播,通过网络将误差信号沿原来的连接通路反传回来修改各神经元的权值直至达到期望输出。神经网络理论已经证明BP神经网络具有强大的非线性映射能力和泛化功能,任一连续函数或映射均可采用三层网络加以实现。BP学习算法的具体过程如下:a)确定BP神经网络的架构,即确定输入层节点的个数、输出层节点的个数,以及隐藏层的层数和每层的节点个数。其中,输入层节点的个数由样本属性的维度决定。输出层节点的个数由样本分类个数决定。隐藏层的层数和每层的节点个数由用户自定义。如图2中隐藏层数目为1,为单隐层。1989年RobertHecht-Nielsen证明了对于任何闭区间内的一个连续函数都可以用一个隐含层的BP网络来逼近,这就是万能逼近定理。所以一个三层的BP神经网络就可以完成任意的m维到n维的映射。其中,隐藏层节点数是影响神经网络性能的重要参数之一。隐藏层节点数少,那么网络则不能充分反映输入节点与输出节点之间的复杂函数关系;但隐藏层节点数过多时,又会出现过拟合现象。通过经验公式可以确定隐藏层节点数目。其中h为隐藏层节点数目,m为输入层节点数目,n为输出层节点数目,a为1-10之间的调节常数。经过多次实验结果表明:当隐藏层节点数为9时,BP神经网络的性能较好。b)对BP神经网络中的参数进行初始化。权值wij表示前一层节点和后一层节点之间的权值,初始为[-1,1]的随机值。阈值θj用来改变节点的活性,初始为[0,1]随机值,前层节点至后层节点之间通过权值系数相连接。c)正向传递设节点i和节点j间的权值为wij,节点j的阀值为bj,每个节点的输出值为xj,而每个节点的输出值是根据上层所有节点的输出值、当前节点与上一层所有节点的权值和当前节点的阀值还有激活函数来实现的。节点的输出值的计算方法如下:隐藏层和输出层的输入表示为其中,Oi是上一层的单元i的输出;θj表示单元j的阈值。神经元的输出是经由激活函数计算得到的,激活函数一般使用simoid函数。故输出表示为故正向传递的过程比较简单,按照上述公式计算即可。在BP神经网络中,输入层节点没有阀值。d)逆向反馈BP神经网络的输出层的误差公式为Errj=Oj(1-Oj)(Tj-Oj)。其中,Oj是节点j的实际输出,而Tj是节点j基于给定训练样本的已知类标号的真正输出。隐藏层的每个节点的误差公式为Errj=Oj(1-Oj)∑kErrk·wkj。其中,wkj是由下一较高层中节点k到节点j的连接权值,而Errk是节点k的误差。在使误差不断减小的原则下,将输出层和隐藏层的误差公式依次展开至隐藏层和输入层,应使权值的调整量与误差的负梯度成正比。网络中每个权值、阈值的增量分别为Δwij=(l)ErrjOj和Δθj=(l)Errj,则分别更新权值、阈值为wij=wij+Δwij和θj=θj+Δθj。其中,l代表学习率,增量公式表示学习率乘以后面两个参数。学习率也是BP网络训练中的一个重要参数,学习率过小,则收敛过慢;学习率过大,则可能修正过头,导致振荡甚至发散。经过多次实验,当BP神经网络的学习率设置为0.00004时,样本预测的正确率最高,少数类的F值最大。至此完成一次了对权值、阈值的修正,在不满足算法终止条件,即算法误差达到预设精度或学习次数达到设定的最大次数之前,不断的进行正向与反向传播。因此,BP神经网络的学习训练过程如下:(1)初始化BP神经网络,对网络参数及各权值系数、阈值进行赋值,设定学习精度、最大迭代次数、学习率等。(2)向前传播,输入训练样本,计算输出层的实际值,并与期望值相比较,计算出网络的输出误差。(3)依据误差反向传播规则,调整隐藏层之间以及隐藏层与输入层之间的权值系数、节点的阈值。(4)重复步骤(2)和(3),直至预测误差满足预设学习精度或学习次数达到设定的最大迭代次数。本发明将BP算法与Adboost算法结合,即通过BP_Adaboost模型预测信用卡用户是否违约。参照图2,本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法包括以下步骤:步骤S1、获取信用卡用户的属性数据,其中信用卡用户的属性为信用卡用户的信用评价指标。具体地,信用卡用户的信用评价指标构成信用卡用户的评价指标体系。为了尽量准确地对信用卡违约状况进行预测,该评价指标体系要全面、真实的反映信用卡持有者的信用状况。其中,每个信用评价指标作为信用卡用户的一个属性。在本发明中,信用卡用户的属性包括个人信贷额度、性别、教育程度、婚姻状况、年龄、近几个月的偿还记录、近几个月的账单金额和近几个月的实际还款金额等23项。其中,优选为近6个月的偿还记录、近6个月的账单金额和近6个月的实际还款金额。具体地,可以从网址http://archive.ics.uci.edu/ml/下载信用卡用户的属性数据。步骤S2、对信用卡用户的属性数据进行归一化处理,并将归一化后的每个用户的属性数据作为一个样本,将所有样本分为训练样本集和测试样本集。由于某些属性值如个人信贷额度、账单金额等的数值差别太大,影响分类效果,故需要对属性数据进行[-1,1]的归一化处理。具体地,对信用卡用户的属性数据进行归一化处理时,采用如下公式:其中i=1,2,3,…m;j=1,2,3,…n;m为样本总数,n为属性个数;xij'表示归一化后第i个样本的第j个属性值,xij表示第i个样本的第j个属性值;max(j)表示m个样本中第j个属性的最大值,max(i)表示m个样本中第i个样本的最大值;min(j)表示m个样本中第j个属性的最小值,min(i)表示m个样本中第i个样本的最小值。经过上述归一化处理,每个属性值都限制在[-1,1]之间。步骤S3、初始化训练样本的分布权值D1(i)=1/m,m为训练样本总数,i=1,2...m表示训练样本序号,根据训练样本输入、输出维数确定BP神经网络结构,初始化BP神经网络的权值、阈值、学习精度、最大迭代次数、学习率。优选地,最大迭代次数为50。在本发明中,每个样本的输入为23维,分别表示每个信用评价指标;输出为1维,表示个人违约状况预测结果。步骤S4、第t次迭代时,利用m个训练样本训练BP神经网络弱分类器ft。步骤S5、根据BP神经网络弱分类器ft预测训练样本得到的预测序列gt,计算预测误差和其中i为gt(xi)≠yi时所对应的训练样本序号,xi为m个训练样本中第i个样本点;gt(xi)为BP神经网络弱分类器ft对样本点xi的预测分类结果;yi为BP神经网络弱分类器ft对样本点xi的期望分类结果。步骤S6、根据预测序列的预测误差和et计算预测序列的权重步骤S7、根据预测序列的权重at调整下一轮训练样本的分布权值为其中Bt是归一化因子,目的是在权重比例不变的情况下使分布权值和为1。步骤S8、利用m个训练样本迭代训练BP神经网络弱分类器,迭代T次后得到T个BP神经网络弱分类器;T为自定义参数。优选地,本发明中T设置为10。步骤S9、根据T个弱分类器得到强分类器即用于信用卡用户违约预测的BP_Adaboost模型,以根据信用卡用户的属性数据预测是否会违约。优选地,在训练基于神经网络为弱分类器的Adaboost数学模型后,还包括输入测试样本集中的样本,检测该用于信用卡用户违约预测的BP_Adaboost模型的性能。具体地,通过与其他模型F值、ROC的对比实验来检测预测模型。当有新的银行信用卡用户数据时,将数据进行归一化处理后,输入用于信用卡用户违约预测的BP_Adaboost模型,即可得到这部分信用卡用户的违约预测结果,预测客户未来的违约情况。下面结合具体实施例来进一步阐述本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法。利用台湾某银行的信用卡交易数据为研究对象,共30000条记录,其中6636条违约记录,23364条诚实记录,每条记录包括23个解释变量,1个反映变量(违约与否)。信用卡用户的属性数据如表1所示。表1、信用卡用户的属性数据表该实施例中训练样本集和测试样本集的分布情况如表2所示。表2、信用卡用户的样本集组成样本集样本总数训练样本测试样本下个月违约663653701266下个月不违约23364186304734在该实施例中,于BP_Adaboost模型的信用卡用户违约的预测方法包括以下步骤:1)通过观察样本属性值可知,样本中某些属性,如信贷额度、账单金额等,数值差别太大,影响分类效果,故先对其进行[-1,1]的归一化处理。2)建立基于BP神经网络为弱分类器的Adaboost数学模型,得到用于信用卡用户违约预测的BP_Adaboost模型。如上所述,共有30000组客户信用状况数据,每组数据的输入为23维,分别代表表1中列出的前23个指标;输出为1维,代表个人违约状况预测结果。从中随机选取24000组数据作为训练数据,6000组数据作为测试数据。3)输入6000个测试样本得到测试样本的分类结果,验证所得用于信用卡用户违约预测的BP_Adaboost模型的性能。实验结果的受试者工作特征曲线(RreceiverOperatingCharacteristiccurve,ROC)如图3所示。参照图4,本发明的基于BP_Adaboost模型的信用卡用户违约的预测系统包括获取模块1、归一化模块2、初始化模块3、训练模块4、预测误差和计算模块5、权重计算模块6、分布权值计算模块7、迭代模块8和预测模块9。获取模块1用于获取信用卡用户的属性数据,其中信用卡用户的属性为信用卡用户的信用评价指标。具体地,信用卡用户的信用评价指标构成信用卡用户的评价指标体系。为了尽量准确地对信用卡违约状况进行预测,该评价指标体系要全面、真实的反映信用卡持有者的信用状况。其中,每个信用评价指标作为信用卡用户的一个属性。在本发明中,信用卡用户的属性包括个人信贷额度、性别、教育程度、婚姻状况、年龄、近几个月的偿还记录、近几个月的账单金额和近几个月的实际还款金额等23项。其中,优选为近6个月的偿还记录、近6个月的账单金额和近6个月的实际还款金额。具体地,可以从网址http://archive.ics.uci.edu/ml/下载信用卡用户的属性数据。归一化模块2与获取模块1相连,用于对信用卡用户的属性数据进行归一化处理,并将归一化后的每个用户的属性数据作为一个样本,将所有样本分为训练样本集和测试样本集。由于某些属性值如个人信贷额度、账单金额等的数值差别太大,影响分类效果,故需要对属性数据进行[-1,1]的归一化处理。具体地,对信用卡用户的属性数据进行归一化处理时,采用如下公式:其中i=1,2,3,…m;j=1,2,3,…n;m为样本总数,n为属性个数;xij'表示归一化后第i个样本的第j个属性值,xij表示第i个样本的第j个属性值;max(j)表示m个样本中第j个属性的最大值,max(i)表示m个样本中第i个样本的最大值;min(j)表示m个样本中第j个属性的最小值,min(i)表示m个样本中第i个样本的最小值。经过上述归一化处理,每个属性值都限制在[-1,1]之间。初始化模块3与归一化模块2相连,用于初始化训练样本的分布权值D1(i)=1/m,m为训练样本总数,i=1,2...m表示训练样本序号,根据训练样本输入、输出维数确定BP神经网络结构,初始化BP神经网络的权值、阈值、学习精度、最大迭代次数、学习率。优选地,最大迭代次数为50。在本发明中,每个样本的输入为23维,分别表示每个信用评价指标;输出为1维,表示个人违约状况预测结果。训练模块4与归一化模块2和初始化模块3相连,用于在第t次迭代时,利用m个训练样本训练BP神经网络弱分类器ft。预测误差和计算模块5与训练模块4相连,用于根据BP神经网络弱分类器ft预测训练样本得到的预测序列gt,计算预测误差和其中i为gt(xi)≠yi时所对应的训练样本序号,xi为m个训练样本中第i个样本点;gt(xi)为BP神经网络弱分类器ft对样本点xi的预测分类结果;yi为BP神经网络弱分类器ft对样本点xi的期望分类结果。权重计算模块6与预测误差和计算模块5相连,用于根据预测序列的预测误差和et计算预测序列的权重分布权值计算模块7与权重计算模块6相连,用于根据预测序列的权重at调整下一轮训练样本的分布权值为其中Bt是归一化因子,目的是在权重比例不变的情况下使分布权值和为1。迭代模块8与训练模块4、预测误差和计算模块5、权重计算模块6和分布权值计算模块7相连,用于利用m个训练样本迭代训练BP神经网络弱分类器,迭代T次后得到T个BP神经网络弱分类器;T为自定义参数。优选地,本发明中T设置为10。预测模块9与迭代模块8相连,用于根据T个弱分类器得到强分类器即用于信用卡用户违约预测的BP_Adaboost模型,以根据信用卡用户的属性数据预测是否会违约。优选地,还包括检测模块,用于在训练基于神经网络为弱分类器的Adaboost数学模型后,输入测试样本集中的样本,检测该用于信用卡用户违约预测的BP_Adaboost模型的性能。具体地,通过与其他模型F值、ROC的对比实验来检测预测模型。当有新的银行信用卡用户数据时,将数据进行归一化处理后,输入用于信用卡用户违约预测的BP_Adaboost模型,即可得到这部分信用卡用户的违约预测结果,预测客户未来的违约情况。综上所述,本发明的基于BP_Adaboost模型的信用卡用户违约的预测方法及系统基于BP算法和Adaboosting算法,根据银行信用卡用户的历史信用信息进行数据分析、训练,建立BP_AdaBoost模型,从而根据新的信用卡用户的相关信用指标,对其是否违约进行预测与判定;节省了银行人员的大量决策时间、并可辅助其做出最佳决策,从而有效地规避相关风险;BP_Adaboost模型对不平衡数据集有很好的处理能力,进一步提高神经网络的泛化能力,提升了信用卡用户违约预测的准确度。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属
技术领域:
中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1