一种基于混合现实技术实现陪伴的方法及装置与流程
本发明涉及混合现实技术领域,特别是涉及一种基于混合现实技术实现陪伴的方法及装置。
背景技术:
随着虚拟现实、增强现实技术的日趋成熟,用户既可以在用计算机构建的虚拟世界中有身临其境的感觉,也可以将虚拟内容叠加到现实世界中,但无论是虚拟现实技术还是增强现实技术,都无法满足用户和虚拟内容进行交互的要求,于是混合现实技术应运而生,它在虚拟世界、现实世界和用户之间搭建了一个交互反馈的回路,使用户可以和虚拟世界进行交互,提升用户体验的真实感。
技术实现要素:
本发明提供一种基于混合现实技术实现陪伴的方法及装置,能够提高交互效率和效果。
本发明采用的一个技术方案是:提供一种基于混合现实技术实现陪伴的方法,该方法包括:
接收用户召唤人物的召唤指令;
响应所述指令进而呼唤出所述人物,所述人物是对现实人的虚拟化对象,当被呼唤后模拟现实人的动作神态;
接收所述用户对所述人物的交互指令;
在数据库中匹配所述交互指令进而得到所述人物的对应行为数据;
以所述行为数据更新所述人物的呈现。
其中,所述虚拟化对象采用以下方法获得:
采集所述虚拟化对象外形数据;
输入所述外形数据进而模拟仿真生成所述虚拟化对象。
其中,所述数据库采用以下方法获得:
采集所述虚拟化对象行为、反应数据;
分析所述行为、反应数据进而得到所述虚拟化对象对应行为反应的所述数据库。
其中,所述以所述行为数据更新所述人物的呈现具体采用激光全息投影技术以所述行为数据更新所述人物的呈现。
其中,所述接收所述用户的指令,包括:
采集所述用户的声音和/或行为和/或表情数据;
识别所述声音和/或行为和/或表情数据进而得到所述指令。
本发明提供的另外一种技术方案是:提供一种基于混合现实技术实现陪伴的装置,包括:
接收模块,用于接收用户召唤人物的召唤指令及交互指令;
处理模块,用于当接收到所述召唤指令后,去匹配所述召唤人物对应的虚拟模型,以及当接收到所述用户的交互指令后,去匹配所述交互指令对应的所述人物的对应行为数据。
呈现模块,用于呈现所述虚拟模型,并以所述行为、反应数据更新所述人物的呈现。
其中,所述装置还包括:
模型建立模块,用于生成所述人物的虚拟模型,包括:
第一数据收集单元,用于采集所述人物的外形数据;
模型建立单元,用于输入所述外形数据进而模拟仿真生成所述虚拟化对象。
其中,所述装置还包括:
数据库模块,用于建立所述的数据库,包括:
第二数据收集单元,用于采集所述虚拟化对象行为、反应数据;
数据库单元,用于分析所述行为、反应数据进而得到所述虚拟化对象对应行为反应的所述数据库。
其中,所述的呈现模块具体用于采用激光全息投影技术以所述行为数据更新所述人物的呈现。
其中,所述的接收模块,包括:
采集单元,用于采集所述用户的声音和/或行为和/或表情数据;
识别单元,用于识别所述声音和/或行为和/或表情数据进而得到所述的召唤指令及交互指令。
本发明的有益效果是:通过事先建立现实人的虚拟模型和收集用户与所述现实人的日常行为数据,当所述用户需要人陪伴时,通过召唤指令,呼出所述虚拟模型,并调用日常行为数据让所述虚拟模型和所述用户进行交互,实现了现实与虚拟的交互,可有效提高交互效率及效果。
附图说明
图1是本发明基于混合现实技术实现陪伴的方法一实施例的流程示意图;
图2是图1中步骤S11的具体流程示意图;
图3是图1中步骤S12中所述虚拟化对象建立的流程示意图;
图4是图1中步骤S13的具体流程示意图;
图5是图1中步骤S14中所述数据库建立的流程示意图;
图6是本发明基于混合现实技术实现陪伴的装置一实施例的结构示意图;
图7是本发明基于混合现实技术实现陪伴的系统一实施例的结构示意图。
具体实施方式
参阅图1,图1是本发明基于混合现实技术实现陪伴的方法一实施例的流程示意图,包括以下步骤:
S11:接收用户召唤人物的召唤指令。
当用户在日常生活中需要有人陪伴时,戴上智能可穿戴设备,发出声音和/或行为和/或表情,所述智能可穿戴设备接收所述声音和/或行为和/或表情,得出所述用户的召唤人物的召唤指令。其中,所述智能可穿戴设备可包括但不限于可戴式虚拟头盔。同时为了更加清楚地采集到所述声音,所述智能穿戴设备可以采用降噪措施抑制环境的声音。
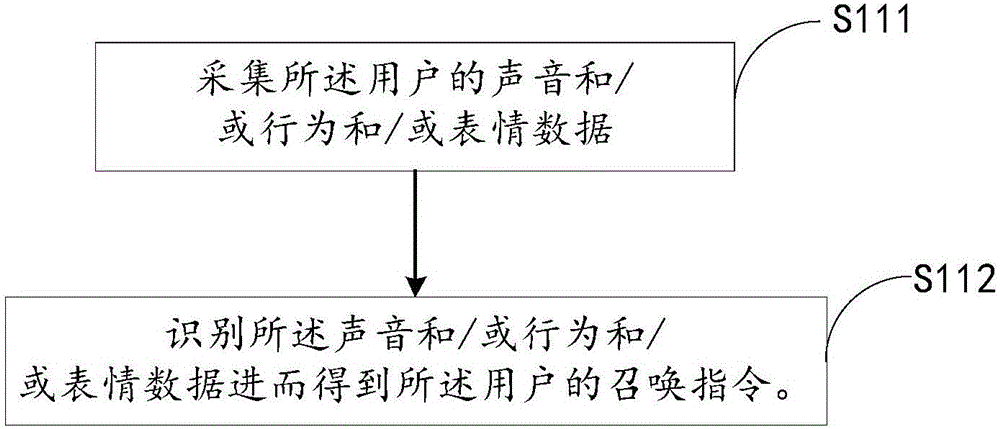
参阅图2,步骤S11具体可包括:
S111:采集所述用户的声音和/或行为和/或表情数据。
当所述用户带穿上所述设备,第一次发出声音数据时,所述智能设备通过传声器如麦克风采集所述声音,同时为了更加准确地得到所述召唤指令,当在采集所述用户的声音数据时,还可以通过视频采集器如摄像头采集所述用户发出的行为和/或表情数据。
S112:识别所述声音和/或行为和/或表情数据进而得到所述用户的召唤指令。
当采集到所述声音后,通过语音识别技术识别出所述声音,得出所述召唤指令。具体地,当采集到声音后,运用语音识别技术对所述声音内容进行识别,提取出字或词等关键特征数据,如称呼名词,基于所述关键特征数据,得出所述用户包含召唤对象的召唤指令,同时如果在采集声音数据的同时,还采集到所述用户的行为和/或表情后,运用图像提取技术,提取所述行为和/或表情中的关键行为和/或表情,如招手动作、哭泣的表情,结合所述声音及所述行为和/或表情数据能够更加准确地得到所述的召唤指令。
S12:响应所述指令进而呼唤出所述人物,所述人物是对现实人的虚拟化对象,当被呼唤后模拟显示人的动作神态。
当所述智能可穿戴设备识别出所述召唤指令后,召唤出所述指令中对应的人物。其中,所述人物是对现实人的虚拟化对象,是一个基于现实人身高、体重、三围、骨骼以及面貌等参数建立的虚拟模型,当被呼唤出来后,能够模仿现实人的动作神态,并呈现在所述用户眼前,所述人物通过所述可智能穿戴设备采用激光全息投影技术呈现。
所述与指令中人物对应的虚拟化对象事先通过服务器进行建立。参阅图3,所述虚拟化对象建立的步骤可包括:
S121:采集所述虚拟化对象外形数据。
当需要建立现实人的虚拟化对象时,通过采集传感器采集所述现实人的身高、体重、三围、骨骼等参数,同时通过图像采集装置采集所述现实人的真实面貌。
S122:输入所述外形数据进而模拟仿真生成所述虚拟化对象。
当采集到所述数据后,所述采集传感器及所述图像采集装置将所述数据传输带服务器,同时还上传所述现实人的身份信息。所述服务器基于所述身高、体重、三围以及骨骼等参数建立所述现实人的3D模型,再利用人脸识别技术仿真生成所述现实人的真实面貌,根据所述的3D模型和所述的真实面貌,建立所述虚拟化对象,同时所述服务器对所述身份信息及对应的虚拟化对象进行保存。
在其他实例中,所述虚拟化对象也可以通过计算机软件进行建立。
S13:接收所述用户对所述人物的交互指令。
当所述虚拟化对象被召唤后,所述可智能穿戴设备继续采集识别所述用户的声音和/或行为和/或表情数据,得到所述用户的交互指令。
参阅图4,步骤S13具体可包括:
S131:采集所述用户的声音和/或行为和/或表情数据。
当所述虚拟化对象被召唤出来后,所述可穿戴智能设备继续通过传声器和/或视频采集器采集所述用户发出的声音和/或行为和/或表情数据,此步骤与所述步骤S111内容相同或类似,不再赘述。
S132:识别所述声音和/或行为和/或表情数据进而得到所述用户的交互指令。
当采集到所述声音后,通过语音识别技术识别出所述声音,得出所述召唤指令。具体地,当采集到声音后,运用语音识别技术对所述声音内容进行识别,提取出字或词等关键特征数据,如动作词,基于所述关键特征数据,得出所述用户的交互信息,同时如果在采集声音数据的同时,还采集到所述用户的行为和/或表情后,运用图像提取技术,提取所述行为和/或表情中的关键行为和/或表情,如肢体动作、面部的喜怒哀乐,结合所述声音及所述行为和/或表情数据能够更加真实准备地得到所述用户想要传达的信息,得出所述交互指令。
S14:在数据库中匹配所述交互指令进而得到所述人物的对应行为数据。
当识别所述用户的交互指令后,在所述服务器的数据库中查找匹配相同或最相似的交互指令,并读取所述交互指令对应的所述虚拟化对象的行为数据。参阅图5,所述数据库的建立包括以下步骤:
S141:采集所述用户和所述虚拟化对象之间的行为、反应数据。
在日常生活中通过传声器及视频采集器采集所述用户和所述虚拟化对象的之间的互动数据,包括采集所述用户做出的行为以及所述虚拟化对象对所述行为作出的反应。所述的行为反应既包括语言也包括动作。所述传声器包括但不限于麦克风,所述采集器包括但不限于摄像头,所述采集器的具体数量和位置不作限定,但是捕获的范围尽量能够包括所述用户和所述虚拟化对象活动的范围。
S142:分析所述行为、反应数据进而得到所述的数据库
采集到所述用户和所述虚拟化对象之间的行为、反应数据后,将所述数据上传至所述服务器。所述服务器运用大数据的挖掘,对所述数据进行分析:将所述用户的行为分析统计生成指令信息,并统计出所述虚拟化对象对所述行为作出的语言和动作的反应,并将所述指令信息及所述反应之间的关系进行保存形成所述数据库。
所述采集行为、反应数据在日常生活中不断进行的,因此所述数据库中的指令信息、行为反应数据是在不断更新存储的。
S15:以所述行为数据更新所述人物的呈现。
当读取到对应所述虚拟化对象的行为反应数据后,以所述数据更新所述人物的呈现,让所述人物做出所述对应的行为反应,所述行为包括动作及语言。其中语言可以通过扬声器如听筒等设备发出,动作的呈现则采用激光全息投影技术通过所述可穿戴智能设备的呈现在所述用户眼前。
参阅图6,图6是本发明基于混合现实技术实现陪伴的装置一实施例的结构示意图,包括:
接收模块21,用于接收用户召唤人物的召唤和交互指令,包括:
采集单元211,用于采集所述用户的声音和/或行为和/或表情数据。
当所述用户需要有人陪伴时,穿上智能可穿戴设备后,发出声音和/或行为和/或表情数据后,采集单元211对所述数据进行采集。所述采集单元211可包括传声器和/或视频采集器。具体地,当所述用户发出声音后,所述传声器对所述声音数据进行采集,或当为了更加准确地的到所述用户的指令,在采集所述声音数据的同时,还可以通过视频采集器对所述行为和/或表情数据进行采集。同时为了更加清楚地采集到所述声音数据,接收单元211可以采用降噪措施尽量抑制环境的噪声。所述传声器可为但不限于麦克风,所述视频采集装置可为但不限于摄像头,且对于所述视频采集器安装的位置不作限定,但是捕获的范围必须包括所述用户的上身部位。
第一识别单元212,用于当采集单元211第一次采集到所述用户的声音和/或行为和/或表情数据后,运用声音识别和/或图像识别技术得到声音指令和/或行为指令,基于所述指令,进而得到所述用户召唤人物的召唤指令。
第二识别单元213,用于当召唤出所述虚拟化对象后,对继续采集得到的声音和/或行为和/或表情数据,运用声音识别和/或图像识别技术得到所述用户的交互指令。
处理模块24,用于当接收到召唤指令后,去匹配与所述召唤指令对应的所述虚拟化模型,以及当接收到所述用户的交互指令后,去匹配与所述交互指令对应的所述人物的对应行为数据。
呈现模块25,用于当匹配到所述虚拟化模型后,运用激光全息投影技术通过所述可穿戴智能设备呈现出所述虚拟化对象,以及当匹配到所述人物的对应行为数据后,运用激光全息投影技术通过所述可穿戴智能设备以所述行为数据更新所述人物的呈现,让所述人物做出所述对应的行为反应,其中所述的行为反应既包括语言也包括动作。
同时,所述装置还包括:模型建立模块24,用于建立所述人物的虚拟模型,包括:
第一数据收集单元241,包括采集传感器和图像采集器,用于采集所述人物的身高、体重、三围、骨骼等参数及真实面貌。
模型建立单元242,用于在服务器中基于所述身高、体重、三围、骨骼等参数,建立所述人物的3D模型,以及运用人脸识别技术,生成所述人物的真实面貌,从而建立所述现实人的虚拟化模型。
数据库模块25,用于建立所述的数据库,包括:
第二数据收集单元251,包括传声器如麦克风及视频采集器如摄像头,用于在日常生活中通过传声器及视频采集器收集所述用户和所述虚拟化对象的之间的互动数据,包括采集所述用户做出的行为以及所述虚拟化对象对所述行为作出的反应。
数据库单元252,用于在所述服务器中运用大数据的挖掘对所述数据进行分析:将所述用户的行为分析统计生成指令信息,并统计出所述虚拟化对象对所述行为作出的语言和动作的反应,并将所述指令信息及所述反应之间的关系进行保存形成所述数据库。
所述第二数据采集单元251收集行为、反应数据在日常生活中不断进行的,因此所述数据库单元251中的指令信息、行为反应数据是在不断更新存储的。
参阅图7,图7是本发明基于混合现实技术实现陪伴的系统一实施例的结构示意图。该系统包括终端设备以及服务器,终端设备可以执行上述方法中的步骤,相关内容请参见上述方法中的详细说明,在此不再赘述。
本实施例中,该终端包括:处理器31、与处理器31耦接的第一传感器32、通信电路33以及虚拟现实呈现装置34。
第一传感器32采集信息,以供处理器31获取用户召唤人物的召唤指令;
处理器31响应指令进而呼唤出人物,控制所述虚拟现实呈现装置呈现人物,所述人物是对现实人的虚拟化对象,当被呼唤后模拟现实人的动作神态;
第一传感器32继续采集信息,以供处理器31接收用户对人物的交互指令;
处理器31通过通信电路33将交互指令发给服务器36,以在服务器的数据库中匹配交互指令进而得到人物的对应行为数据;
进一步,包括第二传感器35,在日常生活中收集用户和虚拟化人物之间的语言互动数据,以及在日常生活中记录所述用户和所述虚拟化人物之间的行为、反应数据,拍摄所述现实人的真实外形,传给服务器36。
第一传感器、第二传感器可以是传声器、视频采集器和/或图像采集器。
服务器36运用大数据分析统计语言、行为、反应数据,生成数据库,并根据所拍摄的现实人的真实外形,生成所述现实人对应的虚拟模型,并对数据库和虚拟模型进行保存。
以上方案,通过事先建立虚拟化对象的虚拟模型及用户和所述虚拟化对象在日常生活中的语言、行为、反应的数据库,当所述用户发出指令需要有人陪伴时,呼出所述虚拟化对象的虚拟模型,并以所述数据库中的语言、行为、反应数据更新所述虚拟化模型的呈现,让用户和虚拟世界进行交互,能够有效提高交互效果和效率。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!