人脸识别方法及装置与流程
本发明涉及人脸识别技术领域,特别是涉及一种人脸识别方法及装置。
背景技术:
人脸识别是一种基于人的脸部特征信息进行身份识别的生物识别技术。,其是通过摄像机或摄像装置采集含有人脸的图像或视频流,并自动在图像中定位和跟踪人脸,进而对定位到的人脸进行识别。目前,人脸识别由于在安全和快捷方面的优势,已被广泛应用于上班打卡、安全支付及安全认证等领域。
在实际的人脸识别使用场景中,通常使用摄像头获得连续视频帧,然后依据这些连续的视频帧进行人脸特征提取和验证识别。例如使用的摄像头的帧率是17帧每秒,实际拍摄某人的时间为5秒,那么实际拿到的人脸图片为17*5=85张。现有技术方案有两种处理方法:
其一、从85张人脸图片中找到一张角度最“正”的人脸,以此代表此人此次采集的85张人脸图片。这种方案中只选取一张正脸照,丢弃了实际场景下大量宝贵的信息,没有充分地利用视频中的人脸信息,人脸识别准确率不高;
其二、将85张人脸图片全部作为有效人脸图片,提取85张人脸图片的特征,并将所有提出的特征作为验证比对的依据。这种方案计算量太大,而且由于人脸视频帧与帧之间的相似性很大,逐帧计算会有大量的冗余,一方面会大大的增加计算量,另一方面也不利于最终的识别结果。
上述两种处理方法均不能解决同时提高人脸识别的准确率和效率的问题。
技术实现要素:
鉴于上述状况,有必要针对现有技术中不能同时提高人脸识别准确率和人效率的问题,提供一种人脸识别方法及装置。
本发明提供了一种人脸识别方法,包括:
采集人脸的两段视频,并确定每一段所述视频的每一个视频帧中的人脸的三维姿态坐标,所述三维姿态坐标为所述视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度;
根据所述三维姿态坐标将两段所述视频的视频帧分别进行聚类,并在每一类所述视频帧中选取一个视频帧作为关键视频帧;
计算两段所述视频的所述关键视频帧之间的人脸特征的距离,并根据所述人脸特征的距离确定两个所述视频中的人脸是否为同一人。
上述人脸识别方法,其中,所述预设的三维姿态坐标轴为:以人脸处于正视的姿态下,脖子所在的方向为z轴、两个耳朵所在的方向为y轴、鼻尖与z轴垂直的方向为x轴;
所述确定每一段所述视频的每一个视频帧中的人脸的三维姿态坐标的步骤包括:
检测每一段所述视频的每一个视频帧中人脸的关键点;
根据所述关键点的坐标确定每一个所述视频帧中的人脸的三维姿态坐标。
上述人脸识别方法,其中,所述在每一类所述视频帧中选取一个视频帧作为关键视频帧的步骤包括:
确定每一类所述视频帧中由所述三维姿态坐标所形成的区域的中心位置;
将每一类所述视频帧中最靠近所述中心位置的所述三维姿态坐标所对应的视频帧作为关键视频帧。
上述人脸识别方法,其中,所述计算两段所述视频的所述关键视频帧之间的人脸特征的距离的步骤包括:
分别提取两段所述视频的所述关键视频帧的人脸特征,所述人脸特征可通过下述公式提取:
其中,表示第一段所述视频的第i个关键视频帧,k1表示第一个视频中关键视频帧的数量;表示第二段所述视频的第j个关键视频帧,k2表示第二段所述视频的关键视频帧的数量;f为人脸特征提取函数;和分别表示第一段视频和第二段视频中的关键视频帧的人脸特征;
计算其中一段所述视频的每一个所述关键视频帧分别与另一段所述视频的每一个所述关键视频帧的人脸特征的距离。
上述人脸识别方法,其中,所述根据所述人脸特征的距离确定所述两段视频中的人脸是否为同一人的步骤包括:
将计算的所述人脸特征的距离中数值最大的一个与预设的距离阈值进行比较;
当所述数值最大的人脸特征的距离大于所述距离阈值时,确定两个所述视频中的人脸不为同一个人。
本发明还提供了一种人脸识别装置,包括:
采集模块,用于采集人脸的两段视频;
第一确定模块,用于确定每一段所述视频的每一个视频帧中的人脸的三维姿态坐标,所述三维姿态坐标为所述视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度;
聚类模块,用于根据所述三维姿态坐标将两段所述视频的视频帧分别进行聚类,并在每一类视频帧中选取一个视频帧作为关键视频帧;
计算模块,用于计算两段所述视频的所述关键视频帧之间的人脸特征的距离,并根据所述人脸特征的距离确定两个所述视频中的人脸是否为同一人。
上述人脸识别装置,其中,所述预设的三维姿态坐标轴为:以人脸处于正视的姿态下,脖子所在的方向为z轴、两个耳朵所在的方向为y轴、鼻尖与z轴垂直的方向为x轴;
所述第一确定模块包括:
关键点检测模块,检测每一段所述视频中每一个视频帧中人脸的关键点;
确定子模块,用于根据所述关键点的坐标确定每一个所述视频帧中的人脸的三维姿态坐标。
上述人脸识别装置,其中,所述聚类模块包括:
第二确定模块,用于确定每一类所述视频帧中由所述三维姿态坐标所形成的区域的中心位置;
选取模块,用于将每一类所述视频帧中最靠近所述中心位置的所述三维姿态坐标所对应的视频帧作为关键视频帧。
上述人脸识别装置,其中,所述计算模块包括:
提取模块,用于分别提取两段所述视频的所述关键视频帧的人脸特征,所述人脸特征可通过下述公式提取:
其中,表示第一段所述视频的第i个关键视频帧,k1表示第一个视频中关键视频帧的数量;表示第二段所述视频的第j个关键视频帧,k2表示第二段所述视频的关键视频帧的数量;f为人脸特征提取函数;和分别表示第一段视频和第二段视频中的关键视频帧的人脸特征;
计算子模块,用于计算其中一段所述视频的每一个所述关键视频帧分别与另一段所述视频的每一个所述关键视频帧的人脸特征的距离。
上述人脸识别装置,其中,所述计算模块还包括:
比较模块,用于将计算的所述人脸特征的距离中数值最大的一个与预设的距离阈值进行比较;
第三确定模块,用于当所述数值最大的人脸特征的距离大于所述距离阈值时,确定两个所述视频中的人脸不为同一个人。
本发明通过计算每个视频帧的三维姿态坐标,并根据三维姿态坐标将每段视频的视频帧进行聚类,选取关键视频帧,再进行人脸特征距离计算,既保证人脸识别的准确性,又减少了计算量,提高了人脸识别效率。
附图说明
图1为本发明第一实施例中的人脸识别的方法流程图;
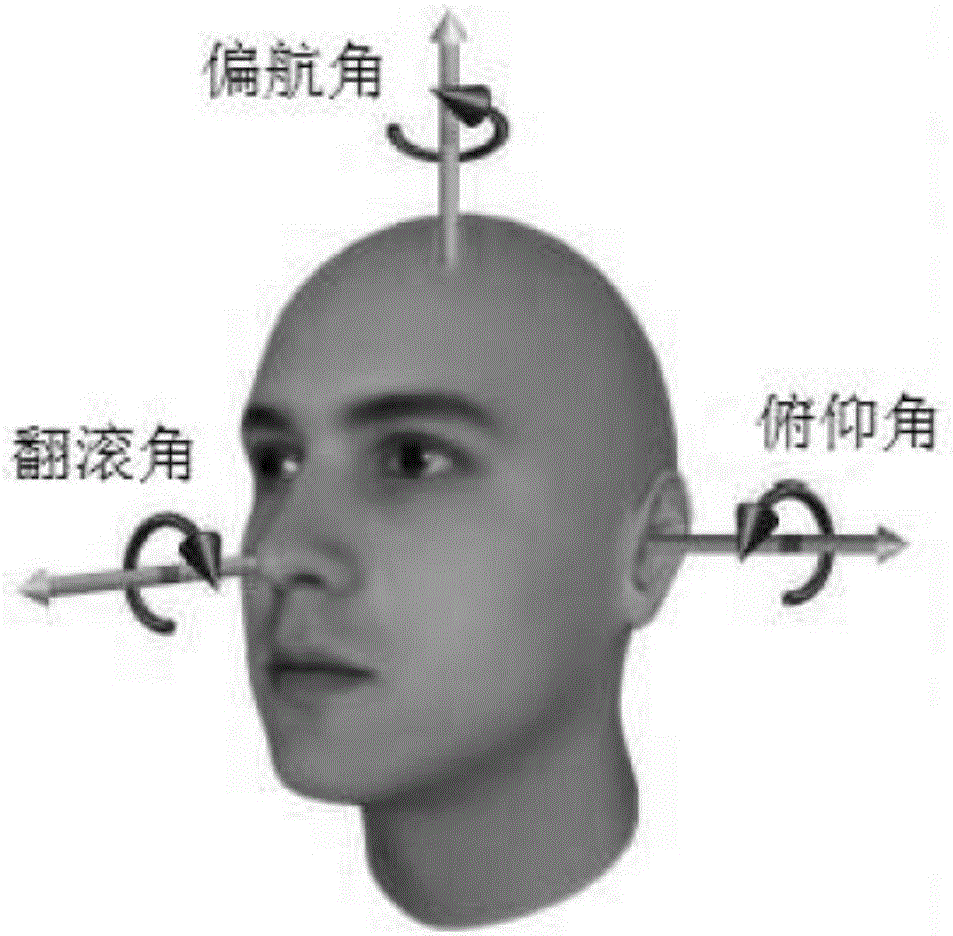
图2为本发明实施例中三维姿态坐标轴的示意图;
图3为本发明第二实施例中的人脸识别的方法流程图;
图4为采集的人脸的视频帧;
图5为采集的视频帧中的人脸的关键点的示意图;
图6为视频帧聚类的结果示意图;
图7为本发明第三实施例中的人脸识别装置的结构框图;
图8为图7中第一确定模块的结构框图;
图9为图7中聚类模块的结构框图;
图10为图7中计算模块的结构框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
参照下面的描述和附图,将清楚本发明的实施例的这些和其他方面。在这些描述和附图中,具体公开了本发明的实施例中的一些特定实施方式,来表示实施本发明的实施例的原理的一些方式,但是应当理解,本发明的实施例的范围不受此限制。相反,本发明的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
请参阅图1,为本发明第一实施例中的人脸识别方法的流程图,包括步骤S11~S14。
步骤S11,采集人脸的两段视频,检测每一段所述视频的每一个视频帧中的人脸的关键点。视频帧中的人脸的关键点至少包括眉毛、眼睛、鼻子、嘴巴和耳朵,可采用现有技术中任意一种关键点检测的方法,在此不加以限制。
步骤S12,根据所述关键点的坐标确定每一个所述视频帧中的人脸的三维姿态坐标。所述三维姿态坐标为所述视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度。
进一步的,所述预设的三维姿态坐标轴为,以人脸处于正视的姿态下,脖子所在的方向为z轴、两个耳朵所在的方向为y轴、鼻尖与z轴垂直的方向为x轴。
每一个视频帧中的人脸具有一个三维姿态,即相对于镜头的位置,如正视、低头、左偏、右偏等。如图2所示,预设一个人脸模型,并定义该人脸模型中的三维姿态坐标轴,计算两个视频帧中的人脸相对于该三维姿态坐标轴的三维姿态坐标,即偏航角(yaw)、俯仰角(pitch)和翻滚角(roll)。
当人脸处于正视姿态时,关键点,如眉毛、眼睛、鼻子、嘴巴和耳朵,相对于该预设的三维姿态坐标轴分别存在标准的三维姿态坐标。检测到当前的视频帧中的人脸的关键点的坐标,即得到平面二维坐标(u,v),根据坐标转换将其转换为世界坐标(X,Y,Z)。
摄像头拍摄的人体的三维视图,是通过透视变换将三维空间中的点投影到图像平面,形成二维平面的图像。投影公式如下:
s·m'=A·[R|t]·M'或
其中,(u,v)是计算得到的人脸关键点坐标,(X,Y,Z)是关键点的世界坐标,(fy,cx,cy)是相机内参,[R|t]为转-平移矩阵。[R|t]被称作外参数矩阵,它用来描述相机相对于一个固定场景的运动,或者相反,物体围绕相机的的刚性运动。也就是[R|t]将点(X Y,Z)的坐标变换到某个坐标系,这个坐标系相对于摄像机来说是固定不变的。通过公式投影公式可以计算出旋转矩阵:
三维姿态坐标表示为:yaw=∠(x,x'),pitch=∠(y,y'),roll=∠(z,z'),其中,∠(x,x')表示向量x和x'的夹角,∠(y,y')表示向量y和y'的夹角,∠(z,z')表示z向量和z'的夹角。其中,
x=[1,0,0]T;y=[0,1,0]T;z=[0,0,1]T;根据旋转矩阵可确定视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度,即三维姿态坐标。
步骤S13,根据所述三维姿态坐标将两段所述视频的视频帧分别进行聚类,并在每一类视频帧中选取一个视频帧作为关键视频帧。
步骤S14,计算两段视频的关键视频帧之间的人脸特征的距离,并根据所述人脸特征的距离确定两个所述视频中的人脸是否为同一人。
摄像头拍摄的视频由连续的视频帧组成,有很多视频帧中的人脸的三维姿态基本相同,若处理每一个视频帧则增加不必要的计算工作,造成大量的冗余。上述步骤中,将每一类相似的三维姿态进行聚成一类,在每一类中选取一个视频帧作为关键视频帧,即作为计算的样本。既保留了原来视频中的人脸姿态信息的分布,也大大提高了人脸特征的距离的计算效率。
本实施例通过计算每个视频帧的三维姿态坐标,并根据三维姿态坐标将每段视频的视频帧进行聚类,选取关键视频帧,再进行人脸特征距离计算,既保证人脸识别的准确性,又减少了计算量,提高了人脸识别效率。
请参阅图3,为本发明第二实施例中的人脸识别方法,包括步骤S21~S30。
步骤S21,采集人脸的两段视频,并对每一段视频进行人脸检测。采集的每一段视频包括多个视频帧,视频帧如附图4所示,使用人脸检测算法可以得到如图4中所示的矩形框区域。
步骤S22,检测每一段所述视频的每一个视频帧中的人脸的关键点。如图5所示,所述关键点例如为眉毛、眼睛、鼻子、嘴巴和耳朵。
步骤S23,根据所述关键点的坐标确定每一个所述视频帧中的人脸的三维姿态坐标。所述三维姿态坐标为所述视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度。本实施例中所述三维姿态坐标的计算方法如第一实施例中的相同,在此不再赘述。
步骤S24,根据所述三维姿态坐标分别对每一段所述视频的视频帧进行聚类。
上述步骤中,通过聚类算法将所述三维姿态坐标进行聚类,从而将所述三维姿态坐标对应的视频帧进行聚类,所述聚类算法可以采用KMeans算法,公式如下:
其中,x表示三维姿态坐标[yaw,pitch,roll],Si表示属于第i个类别的三维姿态样本点的集合,μi表示第i个三维姿态样本点的类中心,k表示聚类的类别数目。
步骤S25,确定每一类所述视频帧中由所述人脸的三维姿态坐标所形成的区域的中心位置。
步骤S26,将每一类所述视频帧中最靠近所述中心位置的所述三维姿态坐标所对应的视频帧作为关键视频帧。
如图6所示,将一个具有85个视频帧的视频通过聚类计算将其分为3类,每一类选取1个关键视频帧。这3个关键视频帧分别代表整个视频中的三个姿态类别的同时,彼此之间差异也非常的大。确定每个聚类中最靠近中心点的三维姿态坐标,如附图6中方框区域所示,并将确定的三维姿态坐标所对应的视频帧作为关键视频帧。
从图6中可以看出,将一段采集到的人脸视频中的85帧视频经过关键视频帧提取之后获得足以表达整个视频信息的3个关键视频帧。将每段视频的视频帧进行聚类降低了视频文件中的信息冗余,但保留了人脸识别过程中非常重要的姿态信息的多样性,保留了原来视频中的人脸姿态信息的分布,同时大大降低了在特征提取过程中对时间和空间的要求,可以使时间和空间性能获得85/3>28倍的提升。
S27,分别提取两段视频的关键视频帧的人脸特征。两段视频的关键视频帧的人脸特征可通过下述公式提取:
其中表示第一段视频的第i个关键视频帧图像,k1表示第一个视频中共选取了k1个关键视频帧;表示第二段视频的第j个关键视频帧,k2表示第二段视频共选取了k2个关键视频帧;f为人脸图像特征提取函数;和分别表示第一段视频和第二段视频中的关键视频帧的人脸特征。
步骤S28,计算其中一段视频的每一个所述关键视频帧分别与另一段视频的每一个所述关键视频帧的人脸特征的距离。两个视频帧的人脸特征的距离可通过如下公式表示:
其中,是人脸特征之间的距离度量函数。
本实施例中可通过欧氏距离如下述公式所示:
计算的距离越大表示两个视频帧中的人脸的相似度越小,距离越小则表示相似度越大。
可以理解的,除欧氏距离之外,马氏距离、余弦距离、贝叶斯距离等都是可以考虑的度量方法。
步骤S29,将计算的所述人脸特征的距离中数值最大的一个人脸特征的距离与预设的距离阈值进行比较。
步骤S30,当所述数值最大的人脸特征的距离大于所述距离阈值时,确定两个所述视频中的人脸不为同一个人。
如第一段视频和第二段视频通过聚类算法分别得到3个关键视频帧,计算第一段视频的每一个关键视频帧与第二段视频中的每一个关键视频帧的人脸特征的距离,即得到9个人脸特征的距离,选取9个人脸特征的距离最大的一个与距离阈值进行比较。
本实施例中,通过聚类算法对每段视频中的多个视频帧进行聚类,每一类人脸的姿态选取一个关键视频帧,降低了视频文件中的信息冗余,但保留了人脸识别过程中非常重要的姿态信息,在保证人脸识别的准确性的同时,提高了人脸识别的效率。
需要说明书的是,两段视频中的关键视频帧的数量根据实际聚类计算中得到,可能相同也可能不同。
请参阅图7至图10,为本发明第三实施例中的人脸识别装置。如图7所示,所述人脸识别装置包括:采集模块31、第一确定模块32、聚类模块33和计算模块34。
所述采集模块31用于采集人脸的两段视频。
所述第一确定模块32用于确定每一段所述视频的每一个视频帧中的人脸的三维姿态坐标,所述三维姿态坐标为所述视频帧中的人脸相对于预设的三维姿态坐标轴旋转的三个角度。
其中,所述预设的三维姿态坐标轴为:以人脸处于正视的姿态下,脖子所在的方向为z轴、两个耳朵所在的方向为y轴、鼻尖与z轴垂直的方向为x轴。
如图8所示,进一步的,所述第一确定模块32包括:
关键点检测模块321,检测所述视频中每一个视频帧中人脸的关键点;
确定子模块322用于根据所述关键点的坐标确定每一个所述视频帧中的人脸的三维姿态坐标。
所述聚类模块33用于根据所述三维姿态坐标将两段所述视频的视频帧分别进行聚类,并在每一类视频帧中选取一个视频帧作为关键视频帧。
如图9所示,进一步的,所述聚类模块33包括:
第二确定模块331,用于确定每一类所述视频帧中由所述三维姿态坐标所形成的区域的中心位置;
选取模块332,用于将每一类所述视频帧中最靠近所述中心位置的所述三维姿态坐标所对应的视频帧作为关键视频帧。
所述计算模块34用于计算两段所述视频的所述关键视频帧之间的人脸特征的距离,并根据所述人脸特征的距离确定两个所述视频中的人脸是否为同一人。
如图10所示,进一步的,所述计算模块34包括:
提取模块341,用于分别提取两段所述视频的所述关键视频帧的人脸特征,所述人脸特征可通过下述公式提取:
其中,表示第一段所述视频的第i个关键视频帧,k1表示第一个视频中关键视频帧的数量;表示第二段所述视频的第j个关键视频帧,k2表示第二段所述视频的关键视频帧的数量;f为人脸特征提取函数;和分别表示第一段视频和第二段视频中的关键视频帧的人脸特征;
计算子模块342,用于计算其中一段所述视频的每一个所述关键视频帧分别与另一段所述视频的每一个所述关键视频帧的人脸特征的距离;
比较模块343,用于将计算的所述人脸特征的距离中数值最大的一个与预设的距离阈值进行比较;
第三确定模块344,用于当所述数值最大的人脸特征的距离大于所述距离阈值时,确定两个所述视频中的人脸不为同一个人。
本实施例中,通过聚类算法对每段视频中的多个视频帧进行聚类,每一类人脸的姿态选取一个关键视频帧,降低了视频文件中的信息冗余,但保留了人脸识别过程中非常重要的姿态信息,在保证人脸识别的准确性的同时,提高了人脸识别的效率。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!