一种获取热点事件的方法及装置与流程
本发明实施例涉及大数据分析的技术领域,尤其涉及一种获取热点事件的方法及装置。
背景技术:
网络热点事件,是指发生在互联网领域的、受到广大网民关注的事件。网络热点事件发现通常对采集到的海量数据进行聚类分析,聚类分析方式如下:取得大规模的文本;对文本进行预处理;对文本进行聚类分析;聚类结果排序;输出结果。对于网络热点事件来说,不同新闻报道的角度不同,内容可能会有较大差异,采用传统的聚类方法准确率不高,无法准确反映网络上的热点事件。
技术实现要素:
本发明实施例的目的在于提出一种获取热点事件的方法及装置,旨在解决如何提高聚类方法准确率的问题。
为达此目的,本发明实施例采用以下技术方案:
第一方面,一种获取热点事件的方法,所述方法包括:
对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;
获取每一个文本中的关键句;
提取所述关键句中的关键短语;
根据预设算法计算所述关键短语中的相似度;
将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;
将得分高的类别作为网络热点事件输出。
优选地,所述获取每一个文本中的关键句,包括:
通过TF-IDF算法或者基于位置的算法获取每一个文本中的关键词。
优选地,所述提取所述关键句中的关键短语,包括:
通过对关键句进行句法分析,提取其中的短语作为关键短语,所述短语包括名词短语或者动词短语。
优选地,所述根据预设算法计算所述关键短语中的相似度,包括:
通过编辑距离、余弦相似度的方法计算两个关键短语的浅层相似度;和/或,
通过深度学习算法训练预设语义模型,并根据所述预设语义模型计算两个关键短语的深层相似度;和/或,
根据所述浅层相似度和所述深层相似度线性结合的方式计算所述关键短语中的联合相似度。
优选地,所述将相似度大于阈值的关键短语聚为一类,并对聚类结果打分,包括:
将联合相似度大于阈值的关键短语聚为一类,并根据所述关键词短语的数量、关键短语的类型对聚类结果打分。
第二方面,一种获取热点事件的装置,所述装置包括:
预处理模块,用于对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;
获取模块,用于获取每一个文本中的关键句;
提取模块,用于提取所述关键句中的关键短语;
计算模块,用于根据预设算法计算所述关键短语中的相似度;
评分模块,用于将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;
输出模块,用于将得分高的类别作为网络热点事件输出。
优选地,所述获取模块,具体用于:
通过TF-IDF算法或者基于位置的算法获取每一个文本中的关键词。
优选地,所述提取模块,具体用于:
通过对关键句进行句法分析,提取其中的短语作为关键短语,所述短语包括名词短语或者动词短语。
优选地,所述计算模块,具体用于:
通过编辑距离、余弦相似度的方法计算两个关键短语的浅层相似度;和/或,
通过深度学习算法训练预设语义模型,并根据所述预设语义模型计算两个关键短语的深层相似度;和/或,
根据所述浅层相似度和所述深层相似度线性结合的方式计算所述关键短语中的联合相似度。
优选地,所述评分模块,具体用于:
将联合相似度大于阈值的关键短语聚为一类,并根据所述关键词短语的数量、关键短语的类型对聚类结果打分。
本发明实施例提供的一种获取热点事件的方法及装置,对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;获取每一个文本中的关键句;提取所述关键句中的关键短语;根据预设算法计算所述关键短语中的相似度;将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;将得分高的类别作为网络热点事件输出。从而能够将同一事件的不同报道通过深层相似度聚合到一块,实现网络热点事件的及时、准确发现。
附图说明
图1是本发明实施例提供的一种获取热点事件的方法的流程示意图;
图2是本发明实施例提供的一种获取热点事件的装置的功能模块示意图。
具体实施方式
下面结合附图和实施例对本发明实施例作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明实施例,而非对本发明实施例的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明实施例相关的部分而非全部结构。
参考图1,图1是本发明实施例提供的一种获取热点事件的方法的流程示意图。
如图1所示,所述获取热点事件的方法包括:
步骤101,对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;
具体的,文本数据可以使用爬虫从互联网抓取,或者从数据库中读取。对取得的文本数据进行预处理。预处理包括提取文本的正文、去除无关链接、中文分词、分段、分句等。
步骤102,获取每一个文本中的关键句;
优选地,所述获取每一个文本中的关键句,包括:
通过TF-IDF(term frequency–inverse document frequency)算法或者基于位置的算法获取每一个文本中的关键词。
步骤103,提取所述关键句中的关键短语;
优选地,所述提取所述关键句中的关键短语,包括:
通过对关键句进行句法分析,提取其中的短语作为关键短语,所述短语包括名词短语或者动词短语。
步骤104,根据预设算法计算所述关键短语中的相似度;
具体的,计算相似度可以为:计算关键短语之间的浅层相似度;计算关键短语之间的深层相似度;计算关键短语之间的联合相似度。
优选地,所述根据预设算法计算所述关键短语中的相似度,包括:
通过编辑距离、余弦相似度的方法计算两个关键短语的浅层相似度;和/或,
通过深度学习算法训练预设语义模型,并根据所述预设语义模型计算两个关键短语的深层相似度;和/或,
根据所述浅层相似度和所述深层相似度线性结合的方式计算所述关键短语中的联合相似度。
具体的,计算关键短语的浅层相似度。通过编辑距离、余弦相似度等方法计算两个关键短语的相似度。浅层相似度将关键短语作为字符串处理,不考虑语义,因此准确度较低;
计算关键短语的深层相似度。通过深度学习算法训练一个语义模型,如使用word2vec训练得到,之后计算两个关键短语的语义相似度,作为深层相似度。由于考虑了语义上的关系,深层相似度的准确程度较高。
计算关键短语的联合相似度。联合相似度采用浅层相似度和深层相似度线性结合的方式实现。
步骤105,将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;
优选地,所述将相似度大于阈值的关键短语聚为一类,并对聚类结果打分,包括:
将联合相似度大于阈值的关键短语聚为一类,并根据所述关键词短语的数量、关键短语的类型对聚类结果打分。
步骤106,将得分高的类别作为网络热点事件输出。
本发明实施例提供的一种获取热点事件的方法,对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;获取每一个文本中的关键句;提取所述关键句中的关键短语;根据预设算法计算所述关键短语中的相似度;将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;将得分高的类别作为网络热点事件输出。从而能够将同一事件的不同报道通过深层相似度聚合到一块,实现网络热点事件的及时、准确发现。
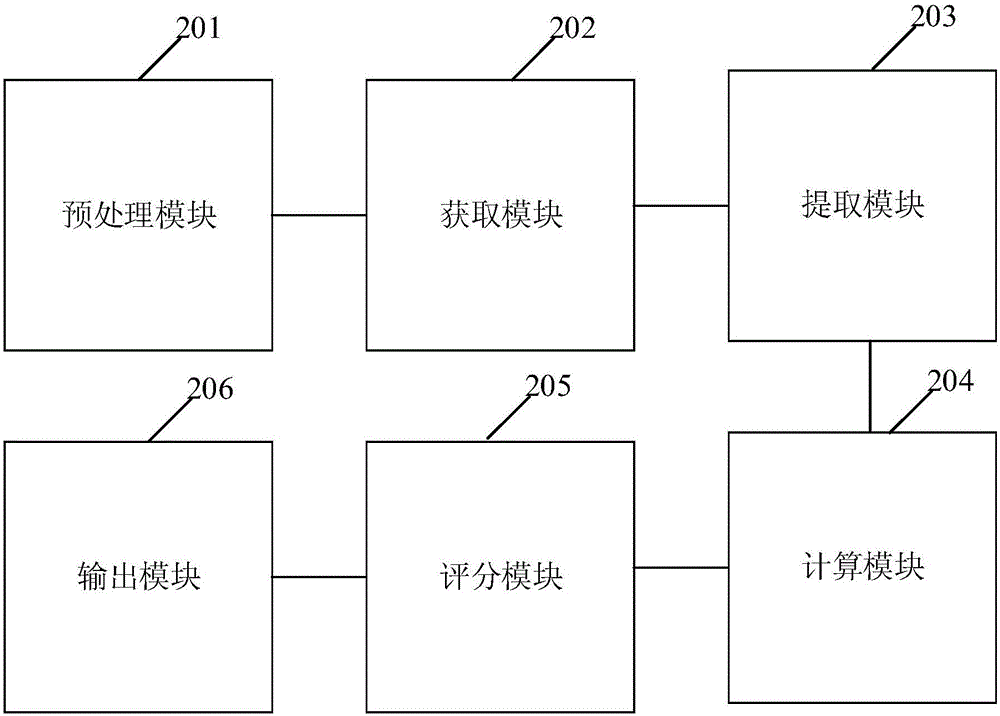
参考图2,图2是本发明实施例提供的一种获取热点事件的装置的功能模块示意图。
如图2所示,所述装置包括:
预处理模块201,用于对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;
获取模块202,用于获取每一个文本中的关键句;
优选地,所述获取模块202,具体用于:
通过TF-IDF算法或者基于位置的算法获取每一个文本中的关键词。
提取模块203,用于提取所述关键句中的关键短语;
优选地,所述提取模块203,具体用于:
通过对关键句进行句法分析,提取其中的短语作为关键短语,所述短语包括名词短语或者动词短语。
计算模块204,用于根据预设算法计算所述关键短语中的相似度;
优选地,所述计算模块204,具体用于:
通过编辑距离、余弦相似度的方法计算两个关键短语的浅层相似度;和/或,
通过深度学习算法训练预设语义模型,并根据所述预设语义模型计算两个关键短语的深层相似度;和/或,
根据所述浅层相似度和所述深层相似度线性结合的方式计算所述关键短语中的联合相似度。
评分模块205,用于将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;
优选地,所述评分模块205,具体用于:
将联合相似度大于阈值的关键短语聚为一类,并根据所述关键词短语的数量、关键短语的类型对聚类结果打分。
输出模块206,用于将得分高的类别作为网络热点事件输出。
本发明实施例提供的一种获取热点事件的装置,对待处理文本进行预处理,所述预处理包括清洗、分段、分句和分词;获取每一个文本中的关键句;提取所述关键句中的关键短语;根据预设算法计算所述关键短语中的相似度;将相似度大于阈值的关键短语聚为一类,并对聚类结果打分;将得分高的类别作为网络热点事件输出。从而能够将同一事件的不同报道通过深层相似度聚合到一块,实现网络热点事件的及时、准确发现。
以上结合具体实施例描述了本发明实施例的技术原理。这些描述只是为了解释本发明实施例的原理,而不能以任何方式解释为对本发明实施例保护范围的限制。基于此处的解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明实施例的其它具体实施方式,这些方式都将落入本发明实施例的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!