一种基于nginx日志的数据分析方法与流程
本发明涉及日志文件技术领域,尤其涉及一种基于nginx日志的数据分析方法。
背景技术:
现有产品一般基于ELK框架搭建一个简易的日志中心平台,但不能满足复杂业务的需求。在日志采集方面,往往新增一个文件采集就需要做定制化采集,无法做到通用化以及更新服务不间断;在数据报表展现方面,不能基于复杂维度进行分析。
技术实现要素:
本发明所要解决的技术问题是提供一种基于nginx日志的数据分析方法。
本发明解决上述技术问题的技术方案如下:
一种基于nginx日志的数据分析方法,适用于nginx日志,所述数据分析方法包括:
S1:通过flume模块采集nginx服务器中的日志文件,并将所述日志文件转移并保存到HDFS系统中;
S2:通过Hive数据库工具对所述HDFS系统中的数据进行mapreduce操作,将加工后的数据保存在中间表中;
S3:将所述中间表中的数据迁移到MySQL数据库的结果表中。
本发明的有益效果是:通过本技术方案可以实现通用化和更新服务不间断,对数据进行复杂维度分析。
在上述技术方案的基础上,本发明还可以做如下改进。
优选地,所述数据分析方法还包括:
S4:通过多维度日志分析图表展示所述结果表中的数据。
优选地,在所述步骤S1之前,所述数据分析方法还包括:
S5:根据不同业务对所述nginx服务器中的所有日志进行分类,得到不同目录的日志文件。
采用上述进一步方案的有益效果是:所述nginx服务器根据不同业务产生不同目录的日志文件。
优选地,所述flume模块包括source组件、channel组件和sink组件,所述步骤S1具体包括:
S11:通过所述source组件监听并采集所述nginx服务器中的日志文件,并根据反馈事件进行相应操作;
S12:通过所述channel组件对所述日志文件进行缓存;
S13:通过所述sink组件将缓存的所述日志文件转移并保存到所述HDFS系统中。
采用上述进一步方案的有益效果是:所述source组件基于多目录文件监听进行数据采集,所述channel组件基于内存的消息队列,提供应用解偶的同时也能减少磁盘IO开销,所述sink组件可以采用容灾机制防止单台服务器故障导致业务无法进行。
优选地,所述步骤S11中,采集所述nginx服务器中的日志文件的方法具体包括:
启动所述source组件,加载所述日志文件的路径;
通过正则表达式筛选出匹配所述路径的所述日志文件。
优选地,所述步骤S11中,监听所述日志文件,并根据反馈事件进行相应操作,所述反馈事件包括创建事件、修改事件和删除事件;启动所述source组件时默认调用创建事件。
采用上述进一步方案的有益效果是:对nginx日志进行文件监控,能够及时找到异常问题。
优选地,所述相应操作具体包括:
若所述反馈事件为创建事件,则根据文件名对所述日志文件进行正则匹配,对相匹配的所述日志文件创建监听线程;
若所述反馈事件为修改事件,则对所述日志文件的线程进行解析,并根据解析结果对所述日志文件进行更新,包括更新所述日志文件的文件大小、文件修改时间以及清空缓存文件;
若所述反馈事件为删除事件,则释放所述日志文件的线程所占用的资源,并回收该线程。
优选地,所述步骤S3中,当迁移过程中出现超过预定数据量的错误时,则进行数据回滚操作,否则继续进行迁移操作。
附图说明
图1为本发明的一种基于nginx日志的数据分析方法的流程示意图;
图2为本发明的一种基于nginx日志的数据分析方法的流程示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,一种基于nginx日志的数据分析方法,适用于nginx日志,数据分析方法包括:
S1:通过flume模块采集nginx服务器中的日志文件,并将日志文件转移并保存到HDFS系统中;
S2:通过Hive数据库工具对HDFS系统中的数据进行mapreduce操作,将加工后的数据保存在中间表中;
S3:将中间表中的数据迁移到MySQL数据库的结果表中;当迁移过程中出现超过预定数据量的错误时,则进行数据回滚操作,否则继续进行迁移操作。
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据,同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume包括两个版本Flume-og和Flume-ng。本技术方案采用的是Flume-ng。相比于Flume-og,Flume-ng最明显的改动就是取消了集中管理配置的Master和Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据由不同的工作线程处理。
Nginx(engine x)是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器,也是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好。Nginx可以在大多数Unix like OS上编译运行,并有Windows移植版。Nginx作为负载均衡服务器,既可以在内部直接支持Rails和PHP程序对外进行服务,也可以支持作为HTTP代理服务器对外进行服务。Nginx采用C进行编写,不论是系统资源开销还是CPU使用效率都比Perlbal要好很多。Nginx代码完全用C语言从头写成,已经移植到许多体系结构和操作系统,包括:Linux、FreeBSD、Solaris、Mac OS X、AIX以及Microsoft Windows。Nginx有自己的函数库,并且除了zlib、PCRE和OpenSSL之外,标准模块只使用系统C库函数。而且,如果不需要或者考虑到潜在的授权冲突,可以不使用这些第三方库。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
上述实施例中,通过flume模块(包括source组件、channel组件和sink组件)采集nginx服务器中的日志文件,并将日志文件转移并保存到HDFS分布式系统中,具体地,flume模块的source组件可以基于多目录文件监听进行采集日志文件,channel组件对source提供中的数据进行简单的缓存,sink组件取出channel中的数据,保存到相应的HDFS分布式文件系统中;通过基于Hadoop分布式文件系统的Hive数据库工具对HDFS分布式系统中的数据进行mapreduce操作,具体地,Hive数据库工具定义了简单的类SQL查询语言(称为HQL),它可以将SQL语句转换为MapReduce任务进行运行,可以存储、查询和分析分布式存储的大规模数据,将加工后的数据保存在中间表中;将中间表中的数据迁移到MySQL数据库的结果表中。
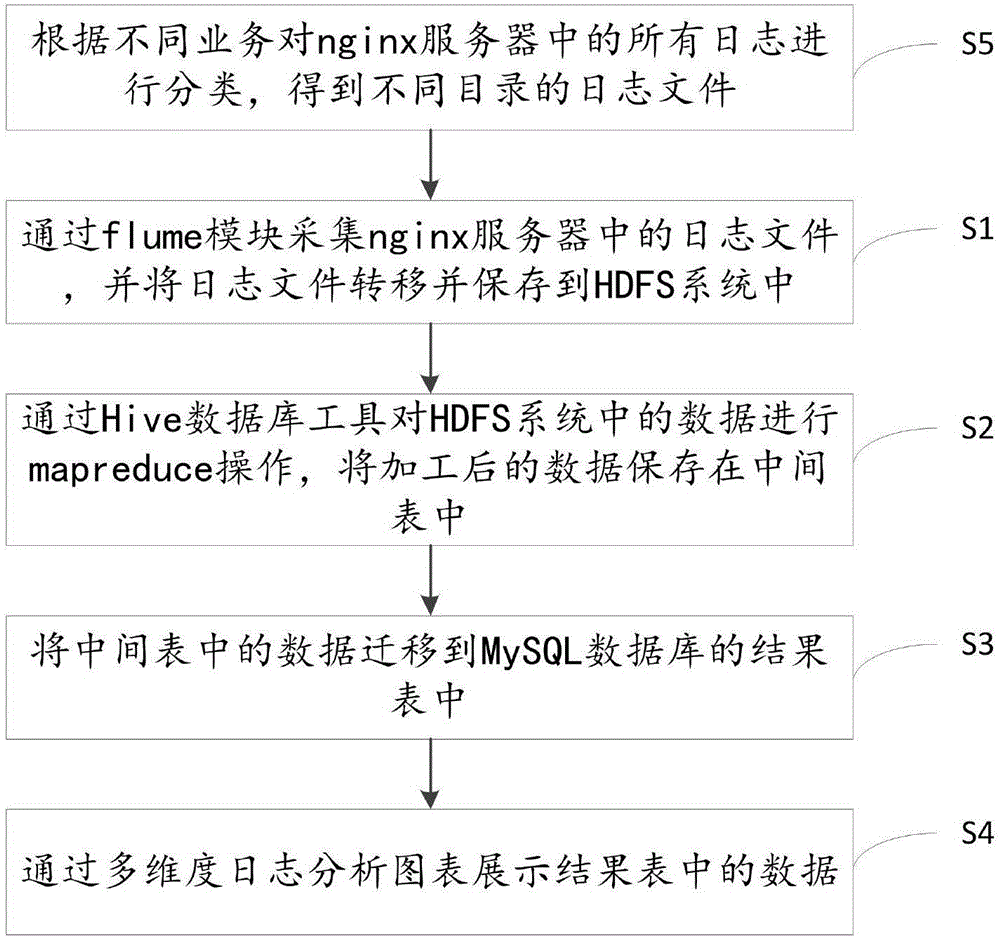
如图2所示,在步骤S3之后,还包括:
S4:通过多维度日志分析图表展示结果表中的数据。
如图2所示,在步骤S1之前,还包括:
S5:根据不同业务对nginx服务器中的所有日志进行分类,得到不同目录的日志文件。
上述实施例中,得到结果表以后,还可以通过多维度日志分析图表展示结果表中的数据;在进行日志文件采集之前,根据不同业务对nginx服务器中的所有日志进行分类,得到不同目录的日志文件,从而flume模块的source组件可以基于多目录文件监听进行采集日志文件。
Source组件完成对日志数据的收集,分成transtion和event打入到channel之中,Channel组件对source提供中的数据进行简单的缓存,Sink组件取出Channel中的数据,保存到相应的存储文件系统(比如HDFS分布式文件系统),数据库,或者提交到远程服务器。
通过source组件采集nginx服务器中的日志文件,首先,启动source组件,加载日志文件的路径,然后,通过正则表达式筛选出匹配路径的日志文件。
通过source组件监听日志文件,并根据反馈事件进行相应操作,反馈事件包括创建事件、修改事件和删除事件,启动source组件时默认调用创建事件。同时,source组件启动时还会新增一个旁路线程用来管理应用线程,每5秒钟触发一次检查管理,当发现其日志在5分钟内未做处理操作时,即该文件没有文件更新,认为此线程存在异常问题进行资源回收并重新创建该文件监听。
通过source组件监听日志文件,并根据反馈事件进行相应操作,相应操作具体包括:
若反馈事件为创建事件,则根据文件名对日志文件进行正则匹配,对相匹配的日志文件创建监听线程;
若反馈事件为修改事件,则对日志文件的线程进行解析,并根据解析结果对日志文件进行更新,包括更新日志文件的文件大小、文件修改时间以及清空缓存文件;
若反馈事件为删除事件,则释放日志文件的线程所占用的资源,并回收该线程。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!