一种基于大数据相关性分析的配电网供电可靠性预测方法与流程
本发明属于电力系统配电网
技术领域:
,具体涉及一种基于大数据相关性分析的配电网供电可靠性预测方法。
背景技术:
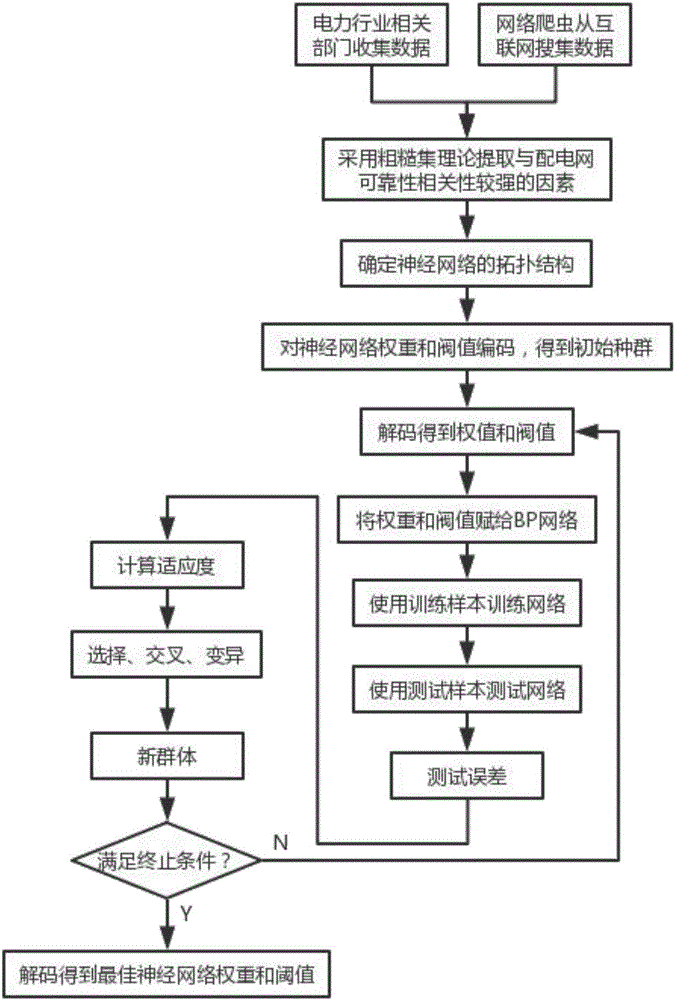
:供电可靠性是指供电系统对用户持续供电的能力。一旦出现供电中断,不仅会造成巨大的经济损失,也会严重影响人们的生活和社会的安定。据电力公司不完全的统计,80%的用户停电事故是由配电系统故障引起的,因此,准确快速的进行配电网可靠性评估十分重要。随着智能配电网信息化、自动化、互动化水平的提高以及与物联网的相互渗透与融合,电力企业量测体系内部积累了大量数据,如用户用电数据、调度运行数据、GIS数据等等,在量测体系之外,电力企业还积累了大量运营数据(参见图1),除却电力企业内部数据外还有许多潜在的外部数据源,分布式电源的大量接入以及电动汽车的快速发展,必将会为配电网的大数据资源池注入更多的数据流。在工程中,配电网供电可靠性评估常用的方法有解析法、模拟法和混合法,这些方法都是以准确的配电网结构和多年的元件可靠性指标历史数据为基础进行预测评估的,而面对如今愈加复杂的配网结构和不断增大的数据量,以上方法很难发挥作用。因此有必要寻求契合智能配电网数据特征的大数据应用技术。技术实现要素:本发明的目的是克服现有技术存在的传统供电可靠性评估方法无法适用于大数据处理的问题,提供一种准确、快速的基于大数据相关性分析的配电网供电可靠性预测方法。为实现以上目的,本发明的技术方案如下:一种基于大数据相关性分析的配电网供电可靠性预测方法,依次包括以下步骤:步骤1、收集电力企业的配电网大数据,该配电网大数据包括量测数据、运营数据以及外部数据;步骤2、采用粗糙集理论从收集到的配电网大数据中提取出与配网供电可靠性的相关性较强的条件因素;步骤3、利用提取出的条件因素搭建BP神经网络进行配网供电可靠性评估预测。所述步骤2依次包括以下步骤:步骤2-1、按照所有的条件属性和决策属性供电可靠率RS-3对所述配电网大数据进行分类,以形成知识库;步骤2-2、根据所有条件属性对所述知识库中的样本进行划分,得到整体的不可分辨关系U/R,同时,按照决策属性供电可靠率RS-3对知识库中的样本进行划分,得到一个不可分辨关系X,根据式1判断出全局U/R肯定属于供电可靠率RS-3的集合,这些集合的并集即为X的正域POS全局(X);步骤2-3、先按顺序依次判断删减某个条件属性后计算得到的POS删减(X)与POS全局(X)是否相等,若相等即判定删减的条件属性为非核心条件属性,不相等则判定其为核心条件属性,再将所有的核心条件属性放入集合Core中;步骤2-4、判断POSCore(X)=POS全局(X)是否成立,若成立,则得到的集合Core即为全局属性的最小属性约简集合,若不成立,则再计算每个非核心条件属性的重要性,按照重要性由大到小的顺序依次加入到集合Core中,直至POSCore(X)=POS全局(X)。所述步骤3依次包括以下步骤:步骤3-1、先根据提取出的条件因素的历史数据生成输入向量,并以其所对应的供电可靠率RS-3的历史数据作为输出向量,再根据式2将以上输入向量和输出向量进行归一化处理,使处理后的数据均匀分布在[-1,1]内,同时,将处理后的数据随机选取70%作为训练数据,剩余的30%作为测试数据;式中,x、y分别为输入向量、输出向量;步骤3-2、选用三层的BP神经网络,以提取出的条件因素的个数n作为神经网络的输入层神经元个数,隐含层神经元个数m取2n+1,预测值选用供电可靠率RS-3,即输出层神经元个数k为1,通过式3、4、5、6计算神经网络的预测输出与期望输出的误差,若该误差不满足精度要求,则从输出层反向传播该误差以调整连接权值和阈值,使神经网络的预测输出和期望输出的误差逐渐减小,直至满足精度要求;上式中,H为隐含层的输出,wij为输入层与隐含层的连接权值,aj为隐含层阈值,O为输出层的预测输出,wjk为隐含层与输出层的连接权值,bk为输出层阈值,zk为期望输出,e为输出层的预测输出与期望输出的误差;步骤3-3、在[-εinit,εinit]内随机取值来初始化BP神经网络的权重和阈值赋值,其中,n和m分别为输入层和输出层神经元个数;步骤3-4、将所述训练数据输入BP神经网络训练学习生成预测模型,所述测试数据则经过预测模型进行供电可靠率RS-3的预测,并与测试数据的实际供电可靠率RS-3进行对比分析,调整参数直至得出能满足要求精度的模型。所述步骤3-3中,初始化BP神经网络的权重和阈值赋值后,采用遗传算法优化出最佳的初始权重和阈值。所述步骤1中,电力企业的外部数据采用网络爬虫技术从互联网中搜集得到。与现有技术相比,本发明的有益效果为:1、本发明一种基于大数据相关性分析的配电网供电可靠性预测方法先采用粗糙集理论从搜集到的配电网大数据中提取出与配电网可靠性相关性较强的条件因素,去除冗余条件因素,避免其对后期神经网络的训练造成干扰,然后利用提取出的相关性较强的条件因素搭建BP神经网络进行配网供电可靠性评估预测,该法不仅能够实现配电网大数据的有效处理,而且利用BP神经网络良好的非线性函数逼近能力,可显著改善预测模型的精度和泛化能力。因此,本发明方法适用于配电网大数据的处理。2、本发明一种基于大数据相关性分析的配电网供电可靠性预测方法采用全局搜索能力较强的遗传算法来优化出BP神经网络的初始权重和阈值,可解决BP神经网络易陷入局部极小值的问题,提高供电可靠性预测的准确性。因此,本发明提高了预测的准确性。附图说明图1为配电网大数据的数据源。图2为本发明的总体流程图。具体实施方式下面结合具体实施方式对本发明作进一步详细的说明。参见图2,一种基于大数据相关性分析的配电网供电可靠性预测方法,依次包括以下步骤:步骤1、收集电力企业的配电网大数据,该配电网大数据包括量测数据、运营数据以及外部数据;步骤2、采用粗糙集理论从收集到的配电网大数据中提取出与配网供电可靠性的相关性较强的条件因素;步骤3、利用提取出的条件因素搭建BP神经网络进行配网供电可靠性评估预测。所述步骤2依次包括以下步骤:步骤2-1、按照所有的条件属性和决策属性供电可靠率RS-3对所述配电网大数据进行分类,以形成知识库;步骤2-2、根据所有条件属性对所述知识库中的样本进行划分,得到整体的不可分辨关系U/R,同时,按照决策属性供电可靠率RS-3对知识库中的样本进行划分,得到一个不可分辨关系X,根据式1判断出全局U/R肯定属于供电可靠率RS-3的集合,这些集合的并集即为X的正域POS全局(X);步骤2-3、先按顺序依次判断删减某个条件属性后计算得到的POS删减(X)与POS全局(X)是否相等,若相等即判定删减的条件属性为非核心条件属性,不相等则判定其为核心条件属性,再将所有的核心条件属性放入集合Core中;步骤2-4、判断POSCore(X)=POS全局(X)是否成立,若成立,则得到的集合Core即为全局属性的最小属性约简集合,若不成立,则再计算每个非核心条件属性的重要性,按照重要性由大到小的顺序依次加入到集合Core中,直至POSCore(X)=POS全局(X)。所述步骤3依次包括以下步骤:步骤3-1、先根据提取出的条件因素的历史数据生成输入向量,并以其所对应的供电可靠率RS-3的历史数据作为输出向量,再根据式2将以上输入向量和输出向量进行归一化处理,使处理后的数据均匀分布在[-1,1]内,同时,将处理后的数据随机选取70%作为训练数据,剩余的30%作为测试数据;式中,x、y分别为输入向量、输出向量;步骤3-2、选用三层的BP神经网络,以提取出的条件因素的个数n作为神经网络的输入层神经元个数,隐含层神经元个数m取2n+1,预测值选用供电可靠率RS-3,即输出层神经元个数k为1,通过式3、4、5、6计算神经网络的预测输出与期望输出的误差,若该误差不满足精度要求,则从输出层反向传播该误差以调整连接权值和阈值,使神经网络的预测输出和期望输出的误差逐渐减小,直至满足精度要求;上式中,H为隐含层的输出,wij为输入层与隐含层的连接权值,aj为隐含层阈值,O为输出层的预测输出,wjk为隐含层与输出层的连接权值,bk为输出层阈值,zk为期望输出,e为输出层的预测输出与期望输出的误差;步骤3-3、在[-εinit,εinit]内随机取值来初始化BP神经网络的权重和阈值赋值,其中,n和m分别为输入层和输出层神经元个数;步骤3-4、将所述训练数据输入BP神经网络训练学习生成预测模型,所述测试数据则经过预测模型进行供电可靠率RS-3的预测,并与测试数据的实际供电可靠率RS-3进行对比分析,调整参数直至得出能满足要求精度的模型。所述步骤3-3中,初始化BP神经网络的权重和阈值赋值后,采用遗传算法优化出最佳的初始权重和阈值。所述步骤1中,电力企业的外部数据采用网络爬虫技术从互联网中搜集得到。本发明的原理说明如下:由附图1中能够看出,电力企业的内部数据和外部数据量是非常巨大的,其中的条件因素是否与配电网供电可靠性存在关联不一定能通过经验判断,为此,本发明提出了一种基于大数据相关性分析的配电网供电可靠性预测方法,其利用粗糙集理论从收集到的配电网大数据中挖掘出与配电网可靠性相关性较强的条件因素,然后利用提取出的条件因素和地区配电网可靠性指标的历史统计数据,通过搭建好的GA-BP神经网络进行训练学习生成预测模型,实现对目标年的配电网供电可靠性准确、快速的评估,保证电网运行的安全性和可靠性。实施例1:参见图2,一种基于大数据相关性分析的配电网供电可靠性预测方法,依次按照以下步骤进行:1、从电力行业相关部门尽量多的收集电力企业相关量测数据和运营数据,并使用python语言、利用html5lib、beautifulSoup4等第三方库编写网络爬虫程序从互联网上搜集电力企业外部数据;2、将上述数据按照所有的条件属性和决策属性供电可靠率RS-3进行分类,形成知识库,具体见下表:3、根据所有条件属性对上述知识库中的样本进行划分,得到整体的不可分辨关系U/R,如按照气象预报系统中的湿度进行划分,得到的一个不可分辨关系U/湿度:{(1),(2,N),(N-2,N-1)},按照气象预报系统中的恶劣天气日数进行划分,得到的一个不可分辨关系U/恶劣天气日数:{(1,2),(N-2,N),(N-1)},同时,按照决策属性供电可靠率RS-3对知识库中的样本进行划分,得到一个不可分辨关系X:{(1,2),(N-2,N),(N-1)};根据式1判断出全局U/R肯定属于供电可靠率RS-3的集合,这些集合的并集(1,2,N-2,N-1,N)即为X的正域POS全局(X);4、先按顺序依次判断删减某个条件属性后计算得到的POS删减(X)与POS全局(X)是否相等,若相等即判定删减的条件属性为非核心条件属性,不相等则判定其为核心条件属性,如删减湿度属性后,U/(R删去湿度属性):{(1),(2),(N-2,N),(N-1)},则POS全局删去湿度(X)=(1,2,N-2,N-1,N)=POS全局(X),判定湿度属性为非核心条件属性,删减恶劣天气日数属性后,U/(R删去恶劣天气日数属性):{(1),(2,N),(N-2,N-1)},X:{(1,2),(N-2,N),(N-1)},则POS全局删去恶劣天气日数(X)=(N-1)≠POS全局(X),判定恶劣天气日数属性为核心条件属性,再将所有的核心条件属性放入集合Core中;5、判断POSCore(X)=POS全局(X)是否成立,若成立,则得到的集合Core即为全局属性的最小属性约简集合,若不成立,则再计算每个非核心条件属性的重要性,按照重要性由大到小的顺序依次加入到集合Core中,直至POSCore(X)=POS全局(X);6、先根据集合Core中的条件因素的历史数据生成输入向量,并以其所对应的供电可靠率RS-3的历史数据作为输出向量,再根据式2将以上输入向量和输出向量进行归一化处理,使处理后的数据均匀分布在[-1,1]内,同时,将处理后的数据随机选取70%作为训练数据,剩余的30%作为测试数据;式中,x、y分别为输入向量、输出向量;7、选用三层的BP神经网络,以提取出的条件因素的个数n作为神经网络的输入层神经元个数,隐含层神经元个数m取2n+1,预测值选用供电可靠率RS-3,即输出层神经元个数k为1,通过式3、4、5、6计算神经网络的预测输出与期望输出的误差,若该误差不满足精度要求,则从输出层反向传播该误差以调整连接权值和阈值,使神经网络的预测输出和期望输出的误差逐渐减小,直至满足精度要求;上式中,H为隐含层的输出,wij为输入层与隐含层的连接权值,aj为隐含层阈值,O为输出层的预测输出,wjk为隐含层与输出层的连接权值,bk为输出层阈值,zk为期望输出,e为输出层的预测输出与期望输出的误差;8、在小范围[-εinit,εinit]内随机取值来初始化BP神经网络的权重和阈值赋值,其中,n和m分别为输入层和输出层神经元个数;9、采用遗传算法优化出最佳的初始权重和阈值,此时,BP神经网络搭建完成,其中,遗传算法的参数设定参考下表:种群大小最大遗传代数交叉概率变异概率代沟401000.70.010.9510、将所述训练数据输入BP神经网络训练学习生成预测模型,所述测试数据则经过预测模型进行供电可靠率RS-3的预测,并与测试数据的实际供电可靠率RS-3进行对比分析,调整参数直至得出能满足要求精度的模型。为验证本发明方法的有效性,现分别收集2014年度、2015年度电力企业的配电网大数据,采用实施例1所述方法对各年度的配电网供电可靠性进行预测,结果如下:年份实际值预测值标准误差201499.955099.95480.0002201599.938099.93780.0002由以上结果可以看出,采用本实施例所述预测模型得到的预测值与实际值的标准误差仅为0.0002,本发明方法的准确度和精度均较高。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1