图数据发布的随机化隐私保护方法与流程
本发明涉及数据发布技术领域,具体涉及一种图数据发布的随机化隐私保护方法。
背景技术:
图数据可以用来描述物种之间的捕食关系,词与词之间的语义联系,计算机之间的网络联接,科研文章之间的引用关系,以及交通流量关系,甚至人类情感关系。当图数据中的实体结点涉及到人时,若直接发布数据或不当的共享给第三方,可能会产生隐私泄露问题。如攻击者如果知道被攻击对象有两个朋友,而发布数据中具有两个朋友的结点只有一个,则能够在发布的数据中重定位目标结点。因此需要在数据发布前对数据进行处理,以保护数据中用户的隐私不被泄露。
技术实现要素:
本发明所要解决的技术问题是现有数据发布存在隐私泄露的问题,提供一种图数据发布的随机化隐私保护方法。
为解决上述问题,本发明是通过以下技术方案实现的:
图数据发布的随机化隐私保护方法,包括如下步骤:
步骤1、设定扰动参数p,其中0<p<1;
步骤2、计算图数据中不存的边添加到图数据中的概率q,
式中,|E|为图数据中边的数目;N为完全图包含的边的数目,N=n*(n-1)/2,n为图数据中结点的个数;p为扰动参数;
步骤3、获得原始的图数据的邻接矩阵,并生成邻接矩阵的上三角矩阵;
步骤4、对于步骤2所得的上三角矩阵中的每条存在的边进行成功概率为p的伯努利实验,得到基于存在边扰动的上三角矩阵;
步骤5、对于步骤2所得到的上三角矩阵中的每条不存在的边进行成功概率为q的伯努利实验,得到基于不存在边扰动的上三角矩阵;
步骤6、将步骤4得到的基于存在边扰动的上三角矩阵和步骤5得到的基于不存在边扰动的上三角矩阵进行叠加融合,得到最终扰动的上三角矩阵;
步骤7、根据步骤6得到的最终扰动的上三角矩阵生成新的邻接矩阵,并由此获得匿名后的图数据。
在步骤1中,扰动参数p可以直接人为设定;也可以通过以下步骤自适应获得:
步骤1.1、设定隐私保护力度r和扰动参数变化的步长a,并初始化扰动参数p和临时变量priv;
步骤1.2、根据下式计算图数据的每个结点的隐私泄露风险,
式中,Risk(vi|di,p)表示度为di的结点在扰动参数p的条件下的隐私泄露风险;P(Z=di|di)表示度为di的结点在随机扰动后其度保持不变的概率;表示原来度不为di的结点在随机扰动后其度变为di的概率;
步骤1.3、选取临时变量priv和隐私泄露风险Risk(vi|di,p)中较小的值作为新的临时变量priv;
步骤1.4、如果新的临时变量priv大于隐私保护力度r,则输出当前扰动参数p;否则,将当前扰动参数p递增步长a,并返回步骤1.2。
步骤1.1中,扰动参数p的初始值等于步长a。
步骤1.1中,扰动参数p的初始值为0.05,临时变量priv的初始值为0,步长a为0.05。
步骤3中,上三角矩阵中的非零项同图数据中的存在条边一一对应;上三角矩阵中的零项同图数据中不存在的边一一对应。
与现有技术相比,本发明提供一种随机方式的数据扰动方法,经过本发明处理后的数据能够共享发布给不特定第三方,而不会侵犯数据所含用户的隐私信息。同时,经过本发明处理后的图数据还具有较好的概率分布特性,能够根据隐私保护力度要求灵活的调整相关参数。
附图说明
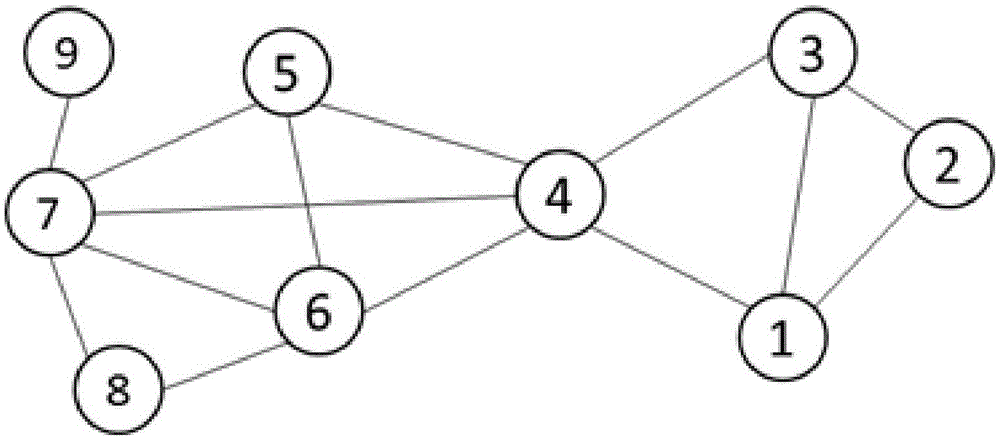
图1为原始图数据。
具体实施方式
本实施例以图1所示原始图络数据为例,对所提出的随机化的图数据发布隐私保护方法进行说明。
图1所示的原始图数据为简单无向图数据G=(V,E),其中V为参与网络的实体,E为实体间的关系。
在计算机中常用邻接矩阵存储和处理图数据。邻接矩阵A=[aij]是一个n×n的0-1矩阵,其中当结点vi和vj间有边时aij=1,否则aij=0。图1所示的原始图数据即图数据G对应的邻接矩阵A的矩阵表示为:
邻接矩阵A是一个对称矩阵,数据中的每条边对应矩阵的中两个对称非零项。为了实现本发明的随机扰动算法,引入上三角矩阵B。上三角矩阵B由邻接矩阵A采用截取对角线以上部分的方式生成,则上三角矩阵B的矩阵表示为:
上三角矩阵B中的非零项同图数据G中的存在条边一一对应。上三角矩阵B中的零项同图数据G中不存在的边一一对应。
一种图数据发布的随机化隐私保护方法,包括如下步骤:
步骤1、设定扰动参数p,其中0<p<1;
扰动参数p可以直接人为设定;也可以通过以下步骤自适应获得:
步骤1.1、设定隐私保护力度r和扰动参数变化的步长a,并初始化扰动参数p和临时变量priv;扰动参数p的初始值等于步长a。在本实施例中,扰动参数p的初始值为0.05,临时变量priv的初始值为0,步长a为0.05。
步骤1.2、根据下式计算图数据的每个结点的隐私泄露风险,
式中,Risk(vi|di,p)表示度为di的结点在扰动参数p的条件下的隐私泄露风险;P(Z=di|di)表示度为di的结点在随机扰动后其度保持不变的概率;表示原来度不为di的结点在随机扰动后其度变为di的概率。
步骤1.3、选取临时变量priv和隐私泄露风险Risk(vi|di,p)中较小的值作为新的临时变量priv。
步骤1.4、如果新的临时变量priv大于隐私保护力度r,则输出当前扰动参数p;否则,将当前扰动参数p递增步长a,并返回步骤1.2。
步骤2、计算图数据中不存的边添加到图数据中的概率q,
式中,|E|为图数据中边的数目;N为完全图包含的边的数目,N=n*(n-1)/2,n为图数据中结点的个数;p为扰动参数。
步骤3、获得原始的图数据的邻接矩阵,并生成邻接矩阵的上三角矩阵。
步骤4、对于步骤2所得的上三角矩阵中的每条存在的边进行成功概率为p的伯努利实验,得到基于存在边扰动的上三角矩阵。
步骤5、对于步骤2所得到的上三角矩阵中的每条不存在的边进行成功概率为q的伯努利实验,得到基于不存在边扰动的上三角矩阵。
步骤6、将步骤4得到的基于存在边扰动的上三角矩阵和步骤5得到的基于不存在边扰动的上三角矩阵进行叠加融合,得到最终扰动的上三角矩阵。
步骤7、根据步骤6得到的最终扰动的上三角矩阵生成新的邻接矩阵,并由此获得匿名后的图数据。
随机化的图数据发布隐私保护方法实现的伪代码如算法1如下所示:
输入:图数据G的邻接矩阵A,扰动参数p;
输出:匿名后的图G’对应的邻接矩阵A’。
算法第1行由输入数据的邻接矩阵A生成上三角矩阵B,此步骤保证数据中的边同矩阵B中的非零值一一对应。
算法第2行到第3行对矩阵B中的存在的边进行成功概率为p,0<p<1,的伯努利实验,即每次实验原来存在的边,有p的几率保持存在;同时记录实验结果用于生成返回值。
算法第4行采用公式:
计算q,其中0<q<1,N=|V|×(|V|-1)÷2;目的是为了使添加的边数的期望和删除的边数的期望相同。算法将采用成功率为q的伯努利实验对输入数据进行再次扰动。参数q为图数据中不存的边添加到数据中的概率。采用随机的方式删除了|E|*(1-p)条边,为了使发布的数据同原始数据边数的期望相同,所以要求添加的边数的期望(N-|E|)*q与之相等,可得q的表达式。E表示边的集合,||表示集合的势。
算法第5行到第6行对矩阵B中的不存在的边进行成功概率为q伯努利实验,即每次实验原来不存在的边有q的几率被添加进来。
第7行根据记录的实验结果准备返回数据。
算法第8行返回数据并退出当前过程。
攻击者根据背景知识对发布数据G’中的目标结点进行重识别攻击。本发明用符号P(B→V|G’)表示攻击者根据背景知识能够成功攻击的概率。为了满足本发明提出的隐私模型,要求此概率小于隐私保护力度r。假设攻击者知道目标结点vi的度信息,并根据此背景知识(用符号b表示)采用查询的方法在发布的数据G’中对目标结点v进行重识别攻击。其查询结果集合Cand(b)包含所有满足给定度信息的结点,表示为:
Cand(b)={v|v∈V,d’i=b}
其中,d’i为发布图数据G’中结点v’i的度。由于没有其它的背景信息,攻击者只能在Cand(b)中随机的选择一个作为目标结点,攻击成功的概率为1/|Cand(b)|。
以上分析是在算法运行后得到具体的G’后进行的。但是本发明的算法是随机的,每次的G’是不同的。为了计算攻击成功的概率,需要结合算法的扰动方式分析扰动后结点度的概率分布。
算法的第2-3行对图数据中每条存在的边e进行成功率为p的伯努利实验Brtnoulli(e,p),即有p的概率实验结束后e仍然保留,(1-p)的概率实验结束后e被删除。对度为di的结点vi,扰动后其度的分布符合二项分布,即
算法第5-6行对图数据中不存在的边e采用q的概率进行伯努利实验,即有q的概率添加边e到数据中。对度为di的结点vi,扰动后其度的分布为
用随机变量Z表示度为di的结点vi经过以上两步扰动后的结点的度分布概率
由于攻击者采用查询的方式进行攻击,扰动后结点vi的度d’i与di不同,则攻击者不能成功实施攻击,度相同则有可能成功实施攻击。首先计算扰动后结点vi的度不变的概率
计算攻击者能够成功攻击的概率还需要考虑其它结点带来的影响。也就是其它结点在扰动后度变为di带来的不确定性。本文用Risk(vi|di,p)表示攻击者采用度背景知识对目标结点vi进行攻击成功的概率,攻击者成功攻击的概率为:
依次计算每个结点的隐私泄露风险,选择最小的作为隐私保护力度r。以上的随机扰动数据发布隐私保护方法和隐私分析,给出了随机扰动参p和相应的隐私保护力度r间的关系。作为数据发布者更希望能够在给定r的情况下由程序自动选择p进行处理,此时由隐私保护力度r确定扰动参数p的伪代码如算法2如下所示:
输入:图数据G的邻接矩阵A,隐私保护力度r;
输出:扰动参数p。
算法的第1行设置扰动参数p=0.05,本实施例认为p=0.05对原始是个较小的扰动,所以从0.05开始搜索。
第2-7行采用步长为0.05的递增方式对p进行搜索。如果搜索到满足隐私保护力度r的扰动参数p,则在第6行返回;如果没有找到合适的参数就,则在第8行返回False。
第3-4计算当前扰动参数p的隐私保护力度。
第5-6行判断当前扰动参数p是否满足隐私保护力度。
综上所述,本发明可以采用如下2种方案:
方案1:当直接给出扰动参数p时,直接采用采用算法1对数据进行随机扰动;
方案2:当由用户提出的隐私要求(隐私保护力度r)时,先采用算法2计算扰动参数p;再采用算法1对数据进行随机化的扰动。
- 还没有人留言评论。精彩留言会获得点赞!