一种网络数据爬取方法和装置与流程
本发明实施例涉及互联网技术领域,具体涉及一种网络数据爬取方法和装置。
背景技术:
随着科技的发展,互联网技术在人们的生活中使用的越来越多,人们可以利用互联网的搜索引擎浏览不同网站的数据,这就需要搜索引擎能够爬取到不同网站的数据,搜索引擎主要通过网络爬虫进行爬取数据。网络爬虫是搜索引擎抓取系统的重要组成部分,爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。
现有技术中,网络爬虫一般会驻留在服务器上,通过给定的URL(Uniform Resource Locator,统一资源定位符),利用HTTP(HyperText Transfer Protocol,超文本传输协议)等标准协议读取相应文档,获取相应的数据。由于网站会通过Robots协议即网络爬虫排除标准协议(Robots Exclusion Protocol)告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。Robots协议的本质是网站和搜索引擎爬虫的沟通方式,用来指导搜索引擎更好地抓取网站内容,而不是作为搜索引擎之间互相限制和不正当竞争的工具。因此,网站可以通过建立反爬虫机制限制网络爬虫爬取网站的全部或部分数据,或导致许多正常爬取的数据爬取失败。
技术实现要素:
针对现有技术中的缺陷,本发明实施例提供本发明实施例提供了一种网络数据爬取方法和装置。
一方面,本发明实施例提供本发明实施例提供了一种网络数据爬取方法,包括:
通过网页测试工具打开浏览器,并打开待爬取数据的网站;
根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;
分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
另一方面,本发明实施例提供一种网络数据爬取装置,包括:
浏览器打开单元,用于通过网页测试工具打开浏览器,并打开待爬取数据的网站;
页面信息获取单元,用于根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;
目标数据获取单元,用于分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
本发明实施例提供的网络数据爬取方法和装置,通过控制浏览器对待爬取数据的网站进行浏览,并采用网页测试工具即selenium模拟用户浏览网站,可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中网络数据爬取方法流程示意图;
图2为本发明实施例中网络数据爬取装置的结构示意图;
图3为本发明实施例中又一网络数据爬取装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明实施例中网络数据爬取方法流程示意图,如图1所示,本发明实施例提供的网络数据爬取方法包括:
S1、通过网页测试工具打开浏览器,并打开待爬取数据的网站;
具体地,本发明实施例提供的网络数据爬取装置,可以通过网页测试工具以下简称selenium打开浏览器,输入URL后可以打开对应的待爬取数据的网站。如若需要爬取网站A中的数据,则通过selenium打开对应的浏览器如IE浏览器,并输入网站A的URL,即可打开网站A。
S2、根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;
具体地,通过selenium打开对应的网站后,根据预先设置的目标数据网页结构,通过selenium模拟用户浏览网站,依次打开网站上目标数据网页结构对应的网页,再根据目标数据标签获取目标数据标签对应的所有网页的页面信息。
S3、分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
具体地,分别对获取的目标数据标签对应的页面信息进行分析,获取目标数据标签对应的的目标数据。需要说明的是,可以获取到目标数据标签对应的一页网页的页面信息后,即对该页面信息进行分析,获取目标数据标签对应的目标数据,也可以将目标数据标签对应的所有网页的页面信息都获取到后,再分别分析每一页网页的页面信息,获取标数据标签对应的目标数据,本发明实施例不作具体限定。
例如:用户需要爬取网站A的B品牌电饭煲的数据,即目标数据标签为B品牌电饭煲。通过selenium打开浏览器后,输入网站A的URL,打开网站A。预设设置好目标数据网页结构为家用电器-B品牌-电饭煲。通过selenium可以模拟用户浏览网站A,依次点击网站A中的家用电器对应的栏目、B品牌对应的栏目和电饭煲对应的栏目,获取到目标数据标签即B品牌电饭煲对应的所有网页的页面信息。因为网页上可能还有其他的数据,通过对获取到的页面信息的分析,获取目标数据标签即B品牌电饭煲对应的目标数据。
本发明实施例提供的网络数据爬取方法,通过控制浏览器对待爬取数据的网站进行浏览,并采用selenium模拟用户浏览网站,可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。
在上述实施例的基础上,所述通过所述网页测试工具模拟用户浏览所述网站,包括:
通过所述网页测试工具模拟点击页面跳转按钮、模拟页面下拉条的滚动和模拟栏目的点击操作,实现模拟用户浏览所述网站。
具体地,在通过selenium模拟用户浏览网站时,可以通过selenium控制浏览器获取到网站上的页面跳转按钮、页面下拉条以及网站上对应的栏目块,模拟对应的点击操作,具体可以模拟点击页面跳转按钮、模拟页面下拉条的滚动和模拟栏目的点击操作,实现模拟用户浏览网站。如:可以模拟用户点击页面跳转按钮进行翻页,即点击上一页或下一页按钮,模拟用户将网页的下拉条下拉,还可以模拟用户点击网页上的某个栏目如家用电器栏目等,以实现智能模拟人为操作。
本发明实施例提供的网络数据爬取方法,通过模拟用户浏览网站时的具体操作,很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。本发明实施例提供的网络数据爬取方法,无需考虑网站反爬机制及动态呈现的方式,针对所有http协议的网站,无需采用正则匹配html标签,都可以通过浏览器模拟用户浏览网站的方式,获取到目标数据标签对应的网页的页面信息,在对获取到的页面信息进行分析,即可获得目标数据标签对应的目标数据。克服了传统的数据爬取无法针对多个网站,每个网站的爬取均需要以网站的特点、反爬机制及动态数据呈现的方式定制爬虫程序编写的困难。
在上述实施例的基础上,所述获取所述网站上目标数据标签对应的所有网页的页面信息,包括:
根据所述目标数据网页结构,打开对应的网页,获取所述目标数据标签对应的所有网页的页面信息,若判断获知所述网页不是所述目标数据标签对应的最后一页网页,则模拟所述点击页面跳转按钮,点击下一页,获取下一页网页的页面信息。
具体地,当通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,获取目标数据标签对应的网页的页面信息。判断当前网页是否是目标数据标签对应的最后一页网页,若不是最后一页,则控制浏览器获取页面跳转按钮,并模拟点击操作,点击下一页,获取下一页的页面信息。若当前网页是目标数据标签对应的最后一页网页,则退出。可以在打开一页网页获取到该网页的页面信息后,即对该网页的页面信息进行分析,获取目标数据标签对应的目标数据。
例如:用户需要爬取网站A的B品牌电饭煲的数据,即目标数据标签为B品牌电饭煲。通过selenium打开浏览器后,输入网站A的URL,打开网站A。预设设置好目标数据网页结构为家用电器-B品牌-电饭煲。通过selenium可以模拟用户浏览网站A,依次点击网站A中的家用电器对应的栏目、B品牌对应的栏目和电饭煲对应的栏目,最后获得B品牌电饭煲对应的网页。若B品牌电饭煲对应的网页有3页,则首先打开的是第一页网页,获取到第一页网页的页面信息后,对该页面信息进行分析,获取B品牌电饭煲对应的目标数据。判断获知第一页网页不是最后一页,则通过selenium模拟点击该网页中的下一页按钮,页面跳转到第二页网页,同样的获取第二页网页的页面信息后,对该页面信息进行分析,获取B品牌电饭煲对应的目标数据。判断获知第二页网页不是最后一页网页,则通过selenium模拟点击该网页中的下一页按钮,页面跳转到第三页网页,同样的获取第三页网页的页面信息后,对该页面信息进行分析,获取B品牌电饭煲对应的目标数据。最后判断第三页网页中没有下一页按钮,即第三页网页是B品牌电饭煲对应的最后一页网页,则退出,B品牌电饭煲的目标数据的抓取结束。
本发明实施例提供的网络数据爬取方法,通过模拟用户浏览网站时的具体操作,一页页的打开目标数据标签对应的所有网页,获取网页对应的页面信息,并通过判断打开的当前网页是否是最后一页网页,实施是否点击下一页的页面跳转按钮,实现翻页的功能,智能真实的模拟用户浏览网站的具体操作。可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。不需要有经验的网络爬虫工程师对网站进行分析,只需定义好目标数据的标签层次即目标数据的网页结构,即可实现获取目标数据标签对应的网页的页面信息,不需要安装大型软件,不需要复杂的操作,操作简单,节约了网络数据爬取的人力物力成本及时间成本。
在上述实施例的基础上,所述方法还包括:预先设置在每一页网页的停留时间。
具体地,在通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,可以根据预先设置的在每一页网页的停留时间,控制浏览器在当前网页进行停留一定的时间,以获取目标数据标签对应的网页的页面信息,并对该页面信息进行分析,获取目标数据标签对应的目标数据。
本发明实施例提供的网络数据爬取方法,通过预先设置浏览网站的网页时,在每一页网页的停留时间,以获取每一页目标数据标签对应的网页的页面信息,并获取页面信息中目标数据标签对应的目标数据,使得爬取的网络数据更加完整和准确。
在上述实施例的基础上,所述方法还包括:若判断获知所述网页出现异常,则模拟刷新页面操作。
具体地,在通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,若判断获知打开的当前网页出现异常如:网页内容为空或网页网址出现错误等,则可以通过selenium控制浏览器模拟刷新页面操作,实现网页的页面刷新,使得网页页面恢复正常。当然判断网页出现异常,还可以是其他异常方式,本发明实施例不作具体限定。
此外,本发明实施例还可以采用虚拟显示器,用来在爬虫服务器即本发明实施例中的网络数据爬取装置上运行浏览器,实现爬取目标网站在浏览器上加载。
本发明实施例提供的网络数据爬取方法,通过模拟用户浏览网站时的具体操作,打开目标数据标签对应的所有网页,获取网页对应的页面信息,并通过判断打开的当前网页是否是最后一页网页,实施是否点击下一页的页面跳转按钮,实现翻页的功能,并能够在判断网页出现异常后,模拟刷新网页页面操作,智能真实的模拟用户浏览网站的具体操作。可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率和网络数据爬取的完整性。同时,操作简单,节约了网络数据爬取的人力物力成本及时间成本。
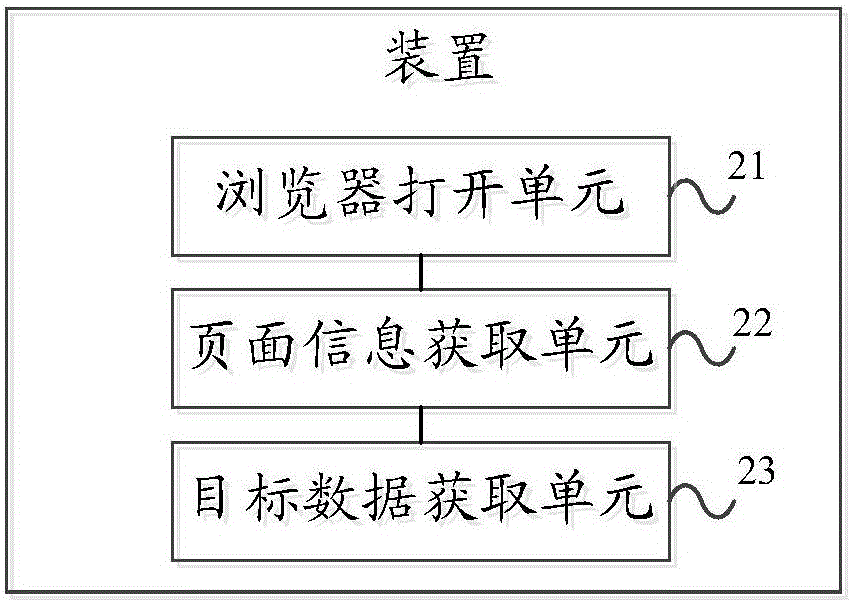
图2为本发明实施例中网络数据爬取装置的结构示意图,如图2所示,本发明实施例提供的网络数据爬取装置包括:浏览器打开单元21、页面信息获取单元22和目标数据获取单元23,其中:
浏览器打开单元21用于通过网页测试工具打开浏览器,并打开待爬取数据的网站;页面信息获取单元22用于根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;目标数据获取单元23用于分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
具体地,本发明实施例提供的网络数据爬取装置中的浏览器打开单元21,可以通过网页测试工具以下简称selenium打开浏览器,输入URL后可以打开对应的待爬取数据的网站。如若需要爬取网站A中的数据,则通过selenium打开对应的浏览器如IE浏览器,并输入网站A的URL,即可打开网站A。页面信息获取单元22根据预先设置的目标数据网页结构,通过selenium模拟用户浏览网站,依次打开网站上目标数据网页结构对应的网页,再根据目标数据标签获取目标数据标签对应的所有网页的页面信息。目标数据获取单元23分别对获取的目标数据标签对应的页面信息进行分析,获取目标数据标签对应的的目标数据。需要说明的是,可以获取到目标数据标签对应的一页网页的页面信息,即对该页面信息进行分析,获取目标数据标签对应的目标数据,也可以将目标数据标签对应的所有网页的页面信息都获取到后,再分别分析每一页网页的页面信息,获取标数据标签对应的目标数据,本发明实施例不作具体限定。
本发明实施例提供的网络数据爬取装置,通过控制浏览器对待爬取数据的网站进行浏览,并采用selenium模拟用户浏览网站,可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。
在上述是实施例的基础上,,所述页面信息获取单元具体用于:通过所述网页测试工具模拟点击页面跳转按钮、模拟页面下拉条的滚动和模拟栏目的点击操作,实现模拟用户浏览所述网站。
具体地,页面信息获取单元在通过selenium模拟用户浏览网站时,可以控制浏览器获取到网站上的页面跳转按钮、页面下拉条以及网站上对应的栏目块,模拟对应的点击操作,具体可以模拟点击页面跳转按钮、模拟页面下拉条的滚动和模拟栏目的点击操作,实现模拟用户浏览网站。如:可以模拟用户点击页面跳转按钮进行翻页,即点击上一页或下一页按钮,模拟用户将网页的下拉条下拉,还可以模拟用户点击网页上的某个栏目如家用电器栏目等,以实现智能模拟人为操作。
本发明实施例提供的网络数据爬取装置,通过模拟用户浏览网站时的具体操作,很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。本发明实施例提供的网络数据爬取方法,无需考虑网站反爬机制及动态呈现的方式,针对所有http协议的网站,无需采用正则匹配html标签,都可以通过浏览器模拟用户浏览网站的方式,获取到目标数据标签对应的网页的页面信息,在对获取到的页面信息进行分析,即可获得目标数据标签对应的目标数据。克服了传统的数据爬取无法针对多个网站,每个网站的爬取均需要以网站的特点、反爬机制及动态数据呈现的方式定制爬虫程序编写的困难。
在上述实施例的基础上,所述页面信息获取单元具体用于:根据所述目标数据网页结构,打开对应的网页,获取所述目标数据标签对应的所有网页的页面信息,若判断获知所述网页不是所述目标数据标签对应的最后一页网页,则模拟所述点击页面跳转按钮,点击下一页,获取下一页网页的页面信息。
具体地,页面信息获取单元通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,获取目标数据标签对应的网页的页面信息。判断当前网页是否是目标数据标签对应的最后一页网页,若不是最后一页,则控制浏览器获取页面跳转按钮,并模拟点击操作,点击下一页,获取下一页的页面信息。若当前网页是目标数据标签对应的最后一页网页,则退出。可以在打开一页网页获取到该网页的页面信息后,即对该网页的页面信息进行分析,获取目标数据标签对应的目标数据。
本发明实施例提供的网络数据爬取装置,通过模拟用户浏览网站时的具体操作,一页页的打开目标数据标签对应的所有网页,获取网页对应的页面信息,并通过判断打开的当前网页是否是最后一页网页,实施是否点击下一页的页面跳转按钮,实现翻页的功能,智能真实的模拟用户浏览网站的具体操作。可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率。不需要有经验的网络爬虫工程师对网站进行分析,只需定义好目标数据的标签层次即目标数据的网页结构,即可实现获取目标数据标签对应的网页的页面信息,不需要安装大型软件,不需要复杂的操作,操作简单,节约了网络数据爬取的人力物力成本及时间成本。
在上述实施例的基础上,所述页面信息获取单元具体用于:预先设置在每一页网页的停留时间。
具体地,页面信息获取单元在通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,可以根据预先设置的在每一页网页的停留时间,控制浏览器在当前网页进行停留一定的时间,以获取目标数据标签对应的网页的页面信息,并对该页面信息进行分析,获取目标数据标签对应的目标数据。
本发明实施例提供的网络数据爬取装置,通过预先设置浏览网站的网页时,在每一页网页的停留时间,以获取每一页目标数据标签对应的网页的页面信息,并获取页面信息中目标数据标签对应的目标数据,使得爬取的网络数据更加完整和准确。
在上述实施例的基础上,所述页面信息获取单元具体用于:若判断获知所述网页出现异常,则模拟刷新页面操作。
具体地,页面信息获取单元在通过selenium模拟用户浏览网站时,根据预先设置的目标数据网页结构,打开对应的网页,若判断获知打开的当前网页出现异常如:网页内容为空或网页网址出现错误等,则可以通过selenium控制浏览器模拟刷新页面操作,实现网页的页面刷新,使得网页页面恢复正常。
本发明提供的装置用于执行上述方法,其具体的实施方式与方法的实施方式一致,此处不再赘述。
本发明实施例提供的网络数据爬取方法,通过模拟用户浏览网站时的具体操作,一页页的打开目标数据标签对应的所有网页,获取网页对应的页面信息,并通过判断打开的当前网页是否是最后一页网页,实施是否点击下一页的页面跳转按钮,实现翻页的功能,并能够在判断网页出现异常后,模拟刷新网页页面操作,智能真实的模拟用户浏览网站的具体操作。可以很好的避免因网站反爬机制造成数据爬取失败的问题,提高了网络数据爬取的成功率和网络数据爬取的完整性。同时,操作简单,节约了网络数据爬取的人力物力成本及时间成本。
图3为本发明实施例中又一网络数据爬取装置的结构示意图,如图3所示,所述装置可以包括:处理器(processor)901、存储器(memory)32和通信总线33,其中,处理器31,存储器32通过通信总线33完成相互间的通信。处理器31可以调用存储器32中的逻辑指令,以执行如下方法:通过网页测试工具打开浏览器,并打开待爬取数据的网站;根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
此外,上述的存储器902中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明实施例提供一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的方法,例如包括:通过网页测试工具打开浏览器,并打开待爬取数据的网站;根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
本发明实施例提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所提供的方法,例如包括:通过网页测试工具打开浏览器,并打开待爬取数据的网站;根据预先设置的目标数据网页结构,通过所述网页测试工具模拟用户浏览所述网站,获取所述网站上目标数据标签对应的所有网页的页面信息;分别对获取到的所述页面信息进行分析,根据所述目标数据标签获取对应的目标数据。
以上所描述的装置以及系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
- 还没有人留言评论。精彩留言会获得点赞!