基于滑动窗口T‑S模糊神经网络模型的铁水硅含量预测方法与流程
本发明属于工业过程监控、建模和仿真领域,特别涉及一种改进型EMD-Elman神经网络预测铁水硅含量的方法。
背景技术:
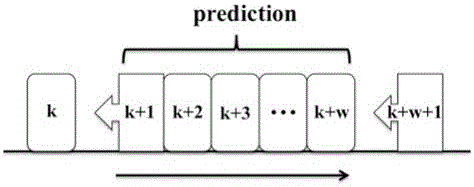
:高炉内复杂的传质传热、多相反应和密闭性,使得高炉具有复杂的时变、动态、非线性、强惯性和多尺度的特性,让高炉中的炼铁过程成为最复杂的工业生产过程之一。高炉内的高温高压、强腐蚀、强干扰的环境,使得我们很难直接测得炉内的热状况。但是,铁水中硅含量和炉温呈线性相关,可以反映铁水的品质,人们通常用铁水中硅含量的大小来表示炉温的高低。硅含量过高代表炉温过高,会消耗额外的燃料,并且会降低铁的产量;而硅含量低表示炉内温度较低,可能引发冻缸等事故。因此,为了高炉的稳定顺行,人们需要将炉温控制在一定的合理范围内,硅含量的预测就显得尤为重要。高炉内硅的变化主要由以下三个反应构成:1/2CO+O2=1/2CO2SiO2+CO=SiO(g)+CO2SiO(g)+C=Si+CO通过阿伦尼乌斯方程可知,温度和浓度对化学反应速率有很大的影响,在硅的相关反应中,可以看出温度、氧气浓度和一氧化碳浓度对铁水硅含量的影响最大。因此,有的学者通过动力学和热力学来建立了铁水硅含量预测的机理模型,他们关注反应过程中的热量和质量守恒。但是,因为高炉内复杂的传质传热、相变化和化学反应,使得机理建模很少能够准确的预测硅的含量。如今,检测手段的发展使得我们可以测得大量的数据,而电脑技术的迅猛发展使得我们可以在短时间内进行大量的运算,这些技术进步使得基于数据驱动的建模变得更加容易,也成为主流的建模方法。已经存在的基于数据驱动的模型有神经网络、线性回归、混沌和支持向量机模型等,它们在某些方面都有自己各自的长处。例如,Jiang提出的混沌粒子群优化算法能够很好地预测制药工业中连续反应釜中的温度。但是,这些模型都是建立在确定的数据集上,不适用于工业在线预测。T-S模糊神经网络拥有很强的自适应能力,能够自动更新模型结构参数,并能修正模糊子集的隶属度函数,可以很好地用来预测控制炼铁过程中的铁水硅含量。通过结合滑动窗口模型,模型能够随时更新训练样本集,进而更新T-S模糊神经网络的参数和系数。滑动窗口T-S模糊神经网络能够很好地适应炼铁过程的动态、非线性和强惯性的特点,在铁水硅含量的预测上表现出很好的性能。技术实现要素:针对现有硅含量预测模型的不足之处,提出了一种基于滑动窗口T-S模糊神经网络的铁水硅含量预测方法。该方法选用滑动窗口模型和T-S模糊神经网络模型建模,并选取11个主要参数作为模型的输入,将硅含量作为模型的输出。该方法具有较高的命中率和较小的均方误差,能够为高炉的操作人员提供准确的预测,帮助他们提前操作高炉,使高炉稳定顺行。该方法由以下步骤组成:步骤一:选取T-S模糊神经网络模型,并组合滑动窗口模型,用于硅含量的预测。步骤二:通过实际经验和互信息计算选取11个参数作为模型的输入,硅含量作为输出。步骤三:将模型初始化后,用归一化的训练样本训练模型,将训练好的模型用于硅含量的预测。步骤一所述的T-S模糊神经网络的结构如下:T-S模糊神经网络由四层构成,分别是输入层、模糊化层、模糊规则计算层和输出层。其中输入是模糊的,而输出是确定的,这表示输出是输入的线性组合。T-S模糊神经网络的定义如下:其中是模糊子集,yi是模糊规则的计算输出。⑴模糊化层是基于概率密度函数μ,其定义如下:式中xj是输入变量,和是概率密度函数的中心和宽度,k是输入参数的维度,n是模糊子集的数量。⑵模糊规则计算层由下式构成:⑶输出层由下式计算得到:步骤一所述的T-S模糊神经网络的学习算法如下:⑴误差计算:其中yd是实际值,yc是预测值,e是两者之差。⑵系数修正:式中是T-S模糊神经网络的系数,而α是其学习率。⑶参数修正:步骤一所述的滑动窗口模型原理如下:滑动窗口模型是建立在一种假设上,即当前的输出依赖于当前的输入,而输入输出之间的映射规则可以通过历史数据得到。根据这个假设,我们预先设定一定量的训练集样本,然后不断地更新样本数据并舍弃最早的数据点。随着窗口的滑动,T-S模糊神经网络会不断更新其结构参数并给出最新的预测值。步骤二所述的输入变量的选取过程如下:互信息是检验变量相关性的一种重要方法,Kraskov提出了一种k-NN方法可以很方便的用来计算互信息,具体步骤如下所述:式中k是一开始给定的近邻的个数,ψ是Digamma函数可以表示为:ψ(x)=Γ(x)-1dΓ(x)/dx它服从以下迭代关系:ψ(x+1)=ψ(x)+1/xΨ(1)=-C,C=0.5772156...为了得到nx和ny,需要计算样本zi和zj之间的距离di,j:di,j=||zi-zj||:di,j1≤di,j2≤di,j3...||zi-zj||=max{||xi-xj||,||yi-yj||}当ε(i)=max{εx(i),εy(i)},ε(i)/2被当作zi和k阶近邻的距离。显然,nx(i)是到xi距离小于ε(i)/2的点的个数,ny(i)是到yi距离小于ε(i)/2的点的个数。通过现场操作工程师的实际经验建议,我们选取了11个变量作为模型的输入,它们分别是顶压、炉顶温度、透气性、喷煤、富氧率、全塔压差、热风压力、热风温度、热风流量、空气湿度和前一炉硅含量。步骤三所述的归一化方法如下:本发明具有以下优点:1、针对炼铁过程中高炉的时变、动态、非线性、强惯性和多尺度的特性,选用了具有很强自适应性的T-S模糊神经网络,它具有很强的学习能力,能够找出输入输出之间的潜在联系。此外,通过添加滑动窗口,模型能够很好地跟踪铁水硅含量的变化趋势,提高了预测的精度。2、通过操作经验和互信息计算,选用了顶压、炉顶温度、透气性、喷煤、富氧率、全塔压差、热风压力、热风温度、热风流量、空气湿度和前一炉硅含量等对当前硅含量影响最大的11个参数作为模型的输入变量,能够充分利用机理建模和数据驱动建模的各自优点。附图说明图1是T-S模糊神经网络的结构示意图,图2是滑动窗口的示意图,图3是1000炉的铁水硅含量,图4是本方法对铁水硅含量的预测结果。具体实施方式本发明提出了一种基于滑动窗口T-S模糊神经网络的铁水硅含量预测方法,该方法由以下步骤组成:步骤一:选取T-S模糊神经网络模型(如图1),并组合滑动窗口模型(如图2),用于硅含量的预测。步骤二:通过实际经验和互信息计算选取11个参数作为模型的输入,硅含量作为输出。步骤三:将模型初始化后,用归一化的训练样本训练模型,将训练好的模型用于硅含量的预测(如图4)。步骤一所述的T-S模糊神经网络的结构如下:T-S模糊神经网络由四层构成,分别是输入层、模糊化层、模糊规则计算层和输出层。其中输入是模糊的,而输出是确定的,这表示输出是输入的线性组合。T-S模糊神经网络的定义如下:其中是模糊子集,yi是模糊规则的计算输出。⑴模糊化层是基于概率密度函数μ,其定义如下:式中xj是输入变量,和是概率密度函数的中心和宽度,k是输入参数的维度,n是模糊子集的数量。⑵模糊规则计算层由下式构成:⑶输出层由下式计算得到:步骤一所述的T-S模糊神经网络的学习算法如下:⑴误差计算:其中yd是实际值,yc是预测值,e是两者之差。⑵系数修正:式中是T-S模糊神经网络的系数,而α是其学习率。⑶参数修正:步骤一所述的滑动窗口模型原理如下:滑动窗口模型是建立在一种假设上,即当前的输出依赖于当前的输入,而输入输出之间的映射规则可以通过历史数据得到。根据这个假设,我们预先设定一定量的训练集样本,然后不断地更新样本数据并舍弃最早的数据点。随着窗口的滑动,T-S模糊神经网络会不断更新其结构参数并给出最新的预测值。步骤二所述的输入变量的选取过程如下:互信息是检验变量相关性的一种重要方法,Kraskov提出了一种k-NN方法可以很方便的用来计算互信息,具体步骤如下所述:式中k是一开始给定的近邻的个数,ψ是Digamma函数可以表示为:ψ(x)=Γ(x)-1dΓ(x)/dx它服从以下迭代关系:ψ(x+1)=ψ(x)+1/xΨ(1)=-C,C=0.5772156...为了得到nx和ny,需要计算样本zi和zj之间的距离di,j:di,j=||zi-zj||:di,j1≤di,j2≤di,j3...||zi-zj||=max{||xi-xj||,||yi-yj||}当ε(i)=max{εx(i),εy(i)},ε(i)/2被当作zi和k阶近邻的距离。显然,nx(i)是到xi距离小于ε(i)/2的点的个数,ny(i)是到yi距离小于ε(i)/2的点的个数。步骤三所述的归一化方法如下:实施例在钢铁生产过程,高炉炼铁都是极其重要好的环节,其消耗的能耗占整个流程的70%,因此高炉的稳定顺行是整个生产过程安全高效运行的保障。因为高炉内的环境极其恶劣,高温高压强腐蚀,使得常规的测量手段很难实施,操作人员很难知晓高炉内的实际热状况,出铁时,铁水损失大量热量也不能反应实际炉温。人们通常利用铁水硅含量来反应炉内的实际状况,因而铁水硅含量的预测就显得极其重要,准确的预测不仅能帮助操作人员合理的调节操作参数,还能指导高炉稳定顺行。我们通过研究柳钢2号高炉的1000组数据(图3所示),验证提出的模型的准确性。下面,我们结合具体过程对实施步骤进行详细的阐述:步骤一:选取T-S模糊神经网络模型,并组合滑动窗口模型,用于硅含量的预测。步骤二:通过实际经验和互信息计算选取11个参数作为模型的输入,硅含量作为输出。步骤三:将模型初始化后,用归一化的训练样本训练模型,将训练好的模型用于硅含量的预测。通过现场操作工程师的实际经验建议,我们选取了11个变量作为模型的输入,它们分别是顶压、炉顶温度、透气性、喷煤、富氧率、全塔压差、热风压力、热风温度、热风流量、空气湿度和前一炉硅含量。计算它们与当前硅含量的互信息值,得到如下结果:编号变量单位互信息1顶压kPa0.122炉顶温度℃0.223透气性m3/min·kPa0.144喷煤t/h0.295富氧率vol%0.216全塔压差kPa0.107热风压力kPa0.158热风温度℃0.329热风流量m3/min0.1310空气湿度vol%0.0811前一炉硅含量wt%0.45互信息值介于0到1,越大表示两个变量相关性越强。从表中可以看出前一炉硅含量与当期硅含量联系最大,但其余的变量的影响也不能忽略。步骤三所述的归一化方法如下:我们设定训练数据的样本量为400,测试数据集为50。用预测命中率J和均方误差MSE两个指标来验证模型预测的精度:在实际生产过程中,预测误差小于0.1即可满足要求。我们提出的模型的命中率达到90%,均方误差为0.0023。具有很高的精度,完全能满足实际生产的需求。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都属于本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 基于模糊神经网络的秸秆发酵燃料乙醇过程补料预测控制系统及方法与流程
- 基于模糊神经网络预测污水水质数据的方法与流程
- 基于T‑S模糊Elman神经网络的短期电力负荷预测方法与流程
- 一种基于模糊玻尔兹曼机的忆阻神经网络训练方法与流程
- 一种基于模糊神经网络的主动噪声控制方法、系统及直升机驾驶员头盔与流程
- 一种基于ANFIS模糊神经网络的机器人路径规划方法与流程
- 一种基于模糊神经网络的主动噪声控制方法、系统及装甲车驾驶员头盔与流程
- 一种基于模糊神经网络的主动噪声控制方法、系统及坦克头盔与流程
- 基于改进模糊神经网络的输电线路绝缘子状态检测方法与制造工艺
- 一种基于区间二型模糊神经网络的污水处理溶解氧浓度跟踪控制方法与制造工艺