基于变换矩阵的欠定混合矩阵估计方法与流程
本发明属于通信技术领域,更进一步涉及信号处理领域中的一种基于变换矩阵的欠定混合矩阵估计方法。本发明可以用于数据通信中,当信道传输参数和源信号数目未知且观测信号数目小于源信号数目时,利用接收到的观测信号实现欠定混合矩阵的估计。
背景技术:
欠定盲分离技术可以在信道传输参数和源信号数目等先验信息未知且观测信号数目小于源信号数目的情况下,仅依靠接收到的观测信号来估计出欠定混合矩阵和恢复出源信号,因此对欠定盲分离的研究一直是国际上信号处理领域的一个热点。在欠定盲分离技术中,欠定混合矩阵估计是实现欠定盲分离的基础,其估计精度直接影响到源信号的恢复效果。在传统的欠定混合矩阵估计方法中往往存在抗噪性能差、欠定混合矩阵估计精度不高以及运算复杂度高等缺点。
哈尔滨工程大学在其申请的专利文件“一种针对欠定盲源分离的混合矩阵估计方法”(申请号201510726953.0,申请日2015.10.30,公开号105354594A)中提出一种针对欠定盲分离的欠定混合矩阵估计方法。该方法对接收到的两路观测信号分别进行短时傅里叶变换得到观测信号的短时傅里叶系数,然后利用得到的短时傅里叶系数进行聚类,估计出欠定混合矩阵。该发明存在的不足之处是,当源信号在时频域时,对稀疏性的要求较高,噪声和异常值对欠定混合矩阵估计效果影响较大,抗噪性能不好。
西安电子科技大学所拥有的专利技术“基于密度的欠定盲源分离方法”(申请号201310116467.8,申请日2013.04.03,公开号103218524B)中提出了一种基于改进K均值的欠定混合矩阵估计方法。该方法首先将观测数据投影到单位超球面上,并计算每个投影点的密度参数,然后剔除低密度投影点,利用K均值聚类方法对高密度投影点进行聚类,最后计算聚类的Davies-Bouldin指标,得到欠定混合矩阵的估计。该方法存在的不足之处是,当计算聚类的Davies-Bouldin指标时,需要进行多次迭代,运算复杂度高,而且得到的欠定混合矩阵估计精度不高。
技术实现要素:
本发明的目的在于针对上述现有技术存在的不足,提出一种基于变换矩阵的欠定混合矩阵估计方法,可以在提高欠定混合矩阵估计精度的同时,降低运算复杂度。
实现本发明目的的具体思路是:首先获取观测信号矩阵,保留高能量数据矩阵和构建有效数据矩阵,然后通过变换矩阵和聚度集合来对有效数据矩阵进行聚类,得到欠定混合矩阵的估计。
实现本发明目的的具体步骤如下:
(1)将每个采集时刻采集到的观测数据依次存入到观测信号矩阵中;
(2)计算高能量门限值:
(2a)按照下式,计算观测信号矩阵中每一列的能量值:
其中,Et表示观测信号矩阵中第t列的能量值,||·||2表示取2范数操作,x(t)表示观测信号矩阵中第t列的数据;
(2b)按照下式,计算高能量门限值:
λ=αmax(Et)
其中,λ表示高能量门限值,α表示系数,α∈[0.1,0.5],max(·)表示取最大值操作;
(3)判断观测信号矩阵中每一列的能量值是否大于高能量门限值,若是,则执行步骤(4),否则,执行步骤(5);
(4)将观测信号矩阵中能量值大于高能量门限值的所有列向量,按列依次存入高能量数据矩阵中;
(5)剔除观测信号矩阵中能量值小于高能量门限值的列向量;
(6)构建有效数据矩阵:
(6a)对高能量数据矩阵中的每一列进行归一化处理,得到归一化矩阵;
(6b)按照下式,计算初始角度矩阵:
其中,dis表示初始角度矩阵,arccos(·)表示取反余弦操作,(·)T表示转置操作,X1表示归一化矩阵,π表示圆周率;
(6c)对初始角度矩阵中的每一行元素进行升序排列,得到有效矩阵;
(6d)按照下式,计算有效矩阵中的列效值:
δ=int(βn)
其中,δ表示有效矩阵中的列效值,int(·)表示取整操作,β表示比例系数,β∈[0.01,0.05],n表示有效矩阵中列向量的总个数;
(6e)将有效矩阵中列序号等于列效值的列向量作为列效向量;
(6f)计算列效向量中所有元素的平均值,将该平均值作为密度阈值;
(6g)判断列效向量中的每一个元素是否小于密度阈值,若是,则执行步骤(6h),否则,执行步骤(6i);
(6h)将列效向量中小于密度阈值的元素序号存入到高密度集合中;
(6i)将列效向量中大于密度阈值的元素序号存入到低密度集合中;
(6j)将归一化矩阵的所有列序号中等于高密度集合元素值的列向量组成有效数据矩阵;
(7)构建变换矩阵:
(7a)按照下式,计算有效角度矩阵:
其中,ang表示有效角度矩阵,X2表示有效数据矩阵;
(7b)将有效角度矩阵中大于密度阈值的元素置为0,其他元素置为1,得到变换矩阵;
(8)对有效数据矩阵进行聚类:
根据变换矩阵,对有效数据矩阵进行聚类,将聚类结果存入到估计矩阵中;
(9)剔除估计矩阵中的第一个列向量,得到欠定混合矩阵。
本发明与现有技术相比具有以下优点:
第一,由于本发明通过保留高能量数据矩阵,构建有效数据矩阵,克服了现有技术中欠定混合矩阵估计精度易受噪声和异常值影响的缺点,使得本发明能够具有较好的抗噪性能以及具有较高的欠定混合矩阵估计精度。
第二,由于本发明通过构建变换矩阵和聚度集合,对有效数据矩阵进行聚类,克服了现有技术中欠定混合矩阵估计运算复杂度较高的缺点,使得本发明能够具有较低的运算复杂度。
附图说明
图1是本发明的流程图;
图2是本发明中对有效数据矩阵进行聚类步骤的流程图;
图3是本发明的仿真图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照附图1,对本发明的具体步骤描述如下。
步骤1,将每个采样时刻采集到的观测数据依次存入到观测信号矩阵中。
步骤2,计算高能量门限值。
按照下式,计算观测信号矩阵中每一列的能量值:
其中,Et表示观测信号矩阵中第t列的能量值,||·||2表示取2范数操作,x(t)表示观测信号矩阵中第t列的数据。
按照下式,计算高能量门限值:
λ=αmax(Et)
其中,λ表示高能量门限值,α表示系数,α∈[0.1,0.5],max(·)表示取最大值操作。
步骤3,判断观测信号矩阵中每一列的能量值是否大于高能量门限值,若是,则执行步骤4,否则,执行步骤5。
步骤4,将观测信号矩阵中能量值大于高能量门限值的所有列向量,按列依次存入高能量数据矩阵中。
步骤5,剔除观测信号矩阵中能量值小于高能量门限值的列向量。
步骤6,构建有效数据矩阵。
对高能量数据矩阵中的每一列进行归一化处理,得到归一化矩阵。
按照下式,计算初始角度矩阵:
其中,dis表示初始角度矩阵,arccos(·)表示取反余弦操作,(·)T表示转置操作,X1表示归一化矩阵,π表示圆周率。
对初始角度矩阵中的每一行元素进行升序排列,得到有效矩阵。
按照下式,计算有效矩阵中的列效值:
δ=int(βn)
其中,δ表示有效矩阵中的列效值,int(·)表示取整操作,β表示比例系数,β∈[0.01,0.05],n表示有效矩阵中列向量的总个数。
将有效矩阵中列序号等于列效值的列向量作为列效向量。
计算列效向量中所有元素的平均值,将该平均值作为密度阈值。
判断列效向量中的每一个元素是否小于密度阈值,若是,则执行步骤6中的第8步,否则,执行步骤6中的第9步。
将列效向量中小于密度阈值的元素序号存入到高密度集合中。
将列效向量中大于密度阈值的元素序号存入到低密度集合中。
将归一化矩阵的所有列序号中等于高密度集合元素值的列向量组成有效数据矩阵。
步骤7,构建变换矩阵。
按照下式,计算有效角度矩阵:
其中,ang表示有效角度矩阵,X2表示有效数据矩阵。
将有效角度矩阵中大于密度阈值的元素置为0,其他元素置为1,得到变换矩阵。
步骤8,对有效数据矩阵进行聚类。
下面结合附图2对本步骤做详细的描述。
根据变换矩阵,对有效数据矩阵进行聚类,将聚类结果存入到估计矩阵中。
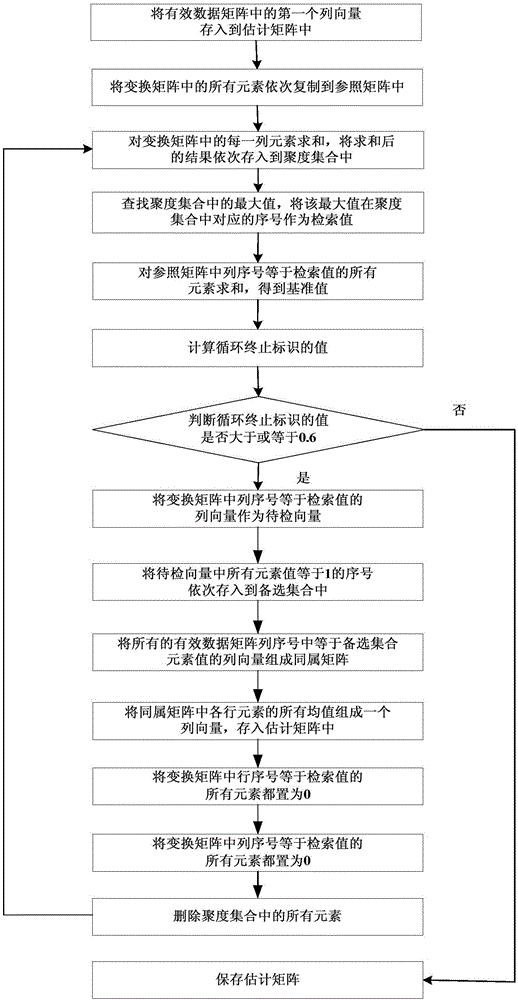
第1步,将有效数据矩阵中的第一个列向量存入到估计矩阵中;
第2步,将变换矩阵中的所有元素依次复制到参照矩阵中;
第3步,对变换矩阵中的每一列元素求和,将求和后的结果依次存入到聚度集合中;
第4步,查找聚度集合中的最大值,将该最大值在聚度集合中对应的序号作为检索值;
第5步,对参照矩阵中列序号等于检索值的所有元素求和,得到基准值;
第6步,按照下式,计算循环终止标识的值:
其中,ε表示循环终止标识的值,d表示聚度集合中的最大值,D表示基准值;
第7步,判断循环终止标识的值是否大于或等于0.6,若是,则执行第8步,否则,执行第15步;
第8步,将变换矩阵中列序号等于检索值的列向量作为待检向量;
第9步,将待检向量中所有元素值等于1的序号依次存入到备选集合中;
第10步,将所有的有效数据矩阵列序号中等于备选集合元素值的列向量组成同属矩阵;
第11步,将同属矩阵中各行元素的所有均值组成一个列向量,存入估计矩阵中;
第12步,将变换矩阵中行序号等于检索值的所有元素都置为0;
第13步,将变换矩阵中列序号等于检索值的所有元素都置为0;
第14步,删除聚度集合中的所有元素,执行第3步;
第15步,保存估计矩阵。
步骤9,剔除估计矩阵中的第一个列向量,得到欠定混合矩阵。
下面结合仿真图对本发明的效果做进一步的描述。
1.仿真条件:
本发明的仿真实验是在硬件环境为Pentium(R)Dual-Core CPU E5300@2.60GHz,软件环境为32位Windows操作系统的条件下进行的。
仿真参数设置为:使用matlab软件产生稀疏源信号和观测信号,源信号数目为5,接收天线数目为3,采集次数为5000。分别对基于改进K均值的欠定混合矩阵估计方法、基于势函数的欠定混合矩阵估计方法和本发明提出的方法进行仿真。
2.仿真内容与结果分析:
本发明的仿真实验是使用本发明所提出的方法,以及使用现有技术的基于改进K均值的欠定混合矩阵估计方法和基于势函数的欠定混合矩阵估计方法,分别对观测信号进行欠定混合矩阵估计。
图3(a)是采用本发明提出的方法和现有技术中的两个方法(基于改进K均值的欠定混合矩阵估计方法和基于势函数的欠定混合矩阵估计方法),在不同信噪比的情况下,分别对欠定混合矩阵进行估计得到的估计偏差比较图。
图3(a)中的横坐标表示信噪比,纵坐标表示欠定混合矩阵估计偏差。图3(a)中以正方形标示的曲线表示本发明所得到的欠定混合矩阵估计偏差随信噪比变化的曲线,以五角星标示的曲线表示基于势函数的欠定混合矩阵估计方法所得到的欠定混合矩阵估计偏差随信噪比变化的曲线,以三角形标示的曲线表示基于改进K均值的欠定混合矩阵估计方法所得到的欠定混合矩阵估计偏差随信噪比变化的曲线。
由图3(a)中的三条曲线可见,在信噪比为6dB到22dB范围内,本发明提出的方法得到的欠定混合矩阵估计偏差值,均小于基于改进K均值的欠定混合矩阵估计方法和基于势函数的欠定混合矩阵估计方法所得到的混合矩阵估计偏差值。
图3(b)是采用本发明提出的方法和现有技术中的两个方法(基于改进K均值的欠定混合矩阵估计方法和基于势函数的欠定混合矩阵估计方法),在不同信噪比的情况下,对欠定混合矩阵进行估计得到的运算时间比较图。
图3(b)中的横坐标表示信噪比,纵坐标表示运算时间。图3(b)中以正方形标示的曲线表示本发明所得到的运算时间随信噪比变化的曲线,以五角星标示的曲线表示基于势函数的欠定混合矩阵估计方法所得到的运算时间随信噪比变化的曲线,以三角形标示的曲线表示基于改进K均值的欠定混合矩阵估计方法所得到的运算时间随信噪比变化的曲线。
由图3(b)可见,在信噪比为6dB到22dB范围内,本发明的运算时间均小于基于改进K均值的欠定混合矩阵估计方法和基于势函数的欠定混合矩阵估计方法所得到的运算时间。
综上所述,在低信噪比和高信噪比的情况下,本发明在欠定混合矩阵估计精度和运算复杂度方面均优于现有技术。因此,本发明能够在保证欠定混合矩阵估计精度的同时,降低运算的复杂度,节省运算时间。
- 还没有人留言评论。精彩留言会获得点赞!