基于自训练的零样本视频分类方法与流程
零样本视频分类涉及机器学习中的视频分类问题,具体讲,涉及基于自训练的零样本视频分类方法。
背景技术:
对于传统的视频分类系统,要想准确识别出某类视频,必须给出相应的带标签的训练数据。但训练数据的标签往往是难以获得的,零样本视频分类就是解决类别标签缺失问题的一种有效手段,其目的在于模仿人类无需看过实际视觉样例,就能认出新的类别的能力。传统的分类方法是将给定的数据集划分为训练集和测试集,用在训练集上学到的模型来识别测试集中的数据,其中训练集和测试集有着相同的类别数。与传统的方法不同的是,零样本视频分类是在没有训练样本的情况下识别新的类别,也就是说训练集和测试集在数据的类别上没有交集,如图1所示。零样本学习旨在通过已有的辅助信息(属性、类别名称等)来训练识别未知类别的分类器,因此可以认为零样本学习对未知类别的识别是建立在人类对类别的描述之上,而不是大量的训练数据。
在零样本视频分类中,类别名称所组成的语义空间是最常用的辅助信息,对于未见过的类别的测试视频和其相应的类别名称,需要借助语义空间建立联系。在语义空间中,每一个类别名称都被表示成一个高维向量,这一高维向量又可被称为词向量(word vector)。常用的词向量提取方法是Mikolov等人提出的word2vec,它是一种无监督的方法,可以将语料库中的单词用向量来表示,并且向量之间的相似度可以很好的模拟单词语义上的相似度。
在给定的语义空间中求得已见过的和未见过的类别的语义特征向量后,各类别间的语义相关性就可以由语义特征向量之间的距离求出。然而,视频是由视觉空间中的视觉特征向量表示的,由于语义鸿沟的存在,它不能与语义空间的特征向量直接建立联系。现有的方法大多通过已见过的类别视频的视觉特征和相应标签的语义特征,学习一个从视觉空间到语义空间的映射函数。然后,通过这个映射函数,将测试视频的视觉特征映射至语义空间,得到预测的语义特征,再找出离它最近的未见过类别的语义特征,从而确定所属类别。
用典型相关分析(Canonical Correlation Analysis,CCA)解决零样本视频分类的方法是学习一个从视觉空间V到公共空间T的映射矩阵wx,以及从语义空间S到公共空间T的映射矩阵wy,使得映射后的两个特征之间相关性最大。具体可表述为求如下相关系数的最大值:
这里x∈Rp是视频的视觉特征,y∈Rq是视频类别的语义特征,E[·]表示数学期望,Cxx=E[xxT]=XXT∈Rp×p和Cyy=E[yyT]=YYT∈Rq×q表示集合内协方差矩阵,Cxy=E[xyT]=XYT∈Rp×q表示集合间协方差矩阵,且有其中X∈Rp×n是所有训练视频的视觉特征组成的矩阵,Y∈Rq×n是所有训练视频类别的语义特征组成的矩阵,n是训练视频总数。注意这里我们把观察样本的统计值作为数学期望的合理近似,并忽略协方差矩阵的系数1/n,这对CCA计算并无影响,本专利以后也采用这种做法。
从公式(3.1)可以发现,ρ关于wx和wy尺度无关,则CCA可表述为如下问题的解:
于是,在零样本视频分类问题中,CCA(公式(3.2))的物理意义就是:让视频的视觉特征与其类别的语义特征在映射到公共空间后的欧式距离最接近。
求解这个优化问题,定义Lagrange函数
令得
分别用和左乘以(3.4)的两边,可得记λ1=λ2=λ,则(3.4)可简化为
设Cyy可逆且λ≠0,由(3.5)可得代入(3.5),整理得
这样,CCA转化为求解两个大小分别为p×p和q×q的矩阵的广义特征值—特征向量问题。在一些文献中,常将CCA问题等价地刻画为如下广义特征值问题:
简记为Aw=λBw,这里A,B分别对应与公式(3.7)中左右两个矩阵。设特征值λ按非递增顺序排列为λ1≥λ2≥...≥λd≥λd+1≥...≥λr≥0,对应于非零特征值的特征向量为wxi和wyi,i=1,...,d,这里d≤r≤min(p,q),则可利用任一对特征向量(即基向量)wxi和wyi进行形如和的特征抽取,这里抽取的特征和可称之为典型变量(canonical variate)或典型成分(canonical component)。
求得映射矩阵wx,wy之后,对于未见过的类别的测试数据,将其视觉特征x'映射到公共空间,得到然后,将所有的未见过的类别的语义特征映射到公共空间,得到其中y'是测试数据的语义特征,m是测试数据的类别数。找出与相关性最大的对应的类别,它就是测试数据的分类结果。
技术实现要素:
为克服现有技术的不足,本发明旨在提出一种有效的零样本视频分类方法,通过本方法可以将训练视频的视觉特征和视频类别名称的语义特征映射到一个公共空间,在这个公共空间中,视频的视觉特征和相应的语义特征具有良好的对应关系。对于新输入的测试视频,将它的视觉特征映射到公共空间,找到对应的语义特征,就可以确定测试视频的所属类别。为此,本发明采用的技术方案是,基于自训练的零样本视频分类方法,将训练视频的视觉特征和视频类别名称的语义特征映射到一个公共空间,在这个公共空间中,视频的视觉特征和相应的语义特征具有良好的对应关系,对于新输入的测试视频,将它的视觉特征映射到公共空间,找到对应的语义特征,确定测试视频的所属类别;其中,采用CCA和自训练的方法使得测试样本的映射分布于原型点周围:首先在测试样本的映射点中寻找K个距离测试样本原型点最近的点,然后将这K个点求平均之后所得的点作为调整后的原型点,令表示原型点的K近邻集合,表示调整后的原型点,自训练的过程用如下公式表述:
对于未见过的类别的测试数据,将其视觉特征x’映射到公共空间,得到然后,将所有未见过的类别的语义特征映射到公共空间,得到y'是测试数据的语义特征,m是测试数据的类别数,找出与相关性最大的对应的类别,从而得到测试数据的分类结果。
具体步骤细化为:
输入:测试样本的视频特征Xte=[x1,x2,...,xn],其中n是测试数据的个数;测试样本类别名称的语义特征Zte=[z1,z2,...,zm],其中m是测试集的类别数;
输出:经CCA自训练调整过的测试类别名称的语义特征即调整过后的原型点;
第一步:确定最近邻范围参数K;
第二步:选取每个原型点的K近邻;
第三步:依据公式5.1求出经过调整之后的原型点。
用上述CCA和自训练的方法进行零样本视频分类的步骤如下所述:
(1)提取训练数据的视频特征X以及训练数据类别名称的语义特征Y;
(2)由CCA计算得到视觉空间向公共空间的映射矩阵Wx,以及语义空间向公共空间的映射矩阵Wy;
(3)对于新输入的测试数据,提取视频特征x,并映射到公共空间,得到
(4)将所有候选的类别的语义特征映射到公共空间,得到其中m是测试数据的类别数;
(5)通过自训练来调整原型点,得到
(6)在公共空间中,找出与距离最近的这个所对应的类别就是测试数据的分类结果。
本发明的特点及有益效果是:
通常的零样本视频分类方法是将视频的视觉特征映射到类别名称的语义特征空间,然后进行分类。但是,类别名称的语义特征构成的原始空间往往不能很好的描绘数据集的类别结构。一种更好的方式是寻求视觉特征空间和语义特征空间之间的一个公共空间。CCA可以满足这个寻找公共空间的需求。并且,经过特征空间的映射之后,域转化问题也不可避免,本专利采用的自训练方法可以很好地弥补域转换所带来的不足。
此外,基于自训练的零样本视频分类技术还具有以下有益效果:
(1)新颖性:自训练的方法通过调整语义原型点,弥补了域转换所带来的不足,更进一步地提升了分类的准确率。
(2)有效性:经过实验验证,与未采用自训练的方法相比,本发明设计的算法在零样本视频分类中可以取得更高的准确率,因此是一种有效的零样本视频分类方法。
(3)实用性:本方法简单易行,效果优良。
附图说明:
图1零样本分类与普通分类之间的区别。
图2零样本分类示意图。
图3自训练示意图。
图4整体算法流程图。
具体实施方式
零样本视频分类属于机器学习中的视频分类问题。分类问题是指,根据已知的训练数据集学习一个分类器,然后利用这个分类器对新的输入实例进行分类。零样本视频分类也是分类问题,只是在测试数据集中没有出现过训练数据中已知的类别。本发明通过典型相关分析(Canonical Correlation Analysis,CCA),建立视频的视觉空间与视频类别的语义空间之间的联系,从而实现零样本视频分类。在此基础之上,本发明通过自训练的方法进一步提升分类的准确率。
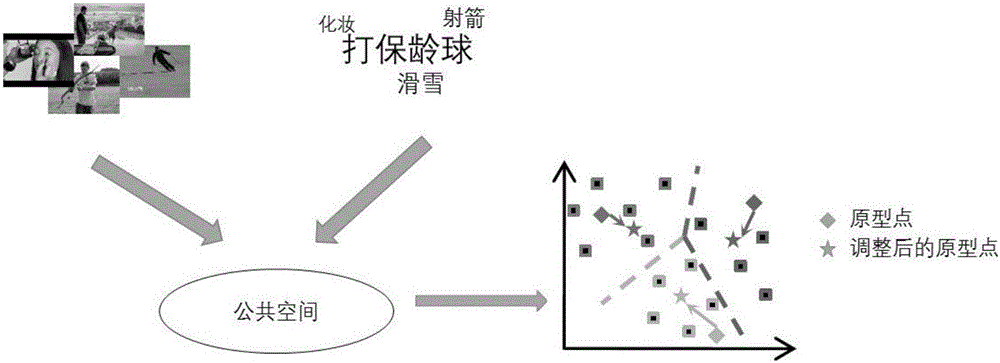
本发明旨在提供一种有效的零样本视频分类方法,通过本方法可以将训练视频的视觉特征和视频类别名称的语义特征映射到一个公共空间,如图2所示。在这个公共空间中,视频的视觉特征和相应的语义特征具有良好的对应关系。对于新输入的测试视频,将它的视觉特征映射到公共空间,找到对应的语义特征,就可以确定测试视频的所属类别。
当测试样本通过从映射矩阵映射到公共空间后,视觉特征映射后的数据点并不一定会整齐地分布在语义特征映射点的周围,从而导致测试样本被错分到其他类别中,这便是域转换带来的不利影响,这里语义特征映射点又被称为原型点(prototype),本发明将延续这一说法。
本发明采用自训练(self training)的方法来降低域转换带来的不利影响。自训练是指调整测试样本的原型点,使得测试样本的映射分布于原型点周围,从而提高分类的准确率,如图3所示。首先需要在测试样本的映射点中寻找K个距离测试样本原型点最近的点,上标T表示转置,然后将这K个点求平均之后所得的点作为调整后的原型点。令表示原型点的K近邻集合,表示调整后的原型点,自训练的过程可用如下公式表述:
对于未见过的类别的测试数据,将其视觉特征x’映射到公共空间,得到然后,将所有未见过的类别的语义特征映射到公共空间,得到m是测试数据的类别数。找出与相关性最大的对应的类别,它就是测试数据的分类结果。
下面结合附图和具体实施例进一步详细说明本发明。
本发明设计的自训练的方法如下所述:
输入:测试样本的视频特征Xte=[x1,x2,...,xn],其中n是测试数据的个数;测试样本类别名称的语义特征Zte=[z1,z2,...,zm]Y={y1,y2,...,ym},其中m是测试集的类别数;
输出:经自训练调整过的测试类别名称的语义特征即调整过后的原型点
第一步:确定最近邻范围参数K(可依据经验或实验结果选取)
第二步:选取每个原型点的K近邻
第三步:依据公式5.1求出经过调整之后的原型点
用上述CCA和自训练的方法进行零样本视频分类的步骤如下所述,整体算法流程如图4所示:
(7)提取训练数据的视频特征X以及训练数据类别名称的语义特征Y;
(8)由CCA计算得到视觉空间向公共空间的映射矩阵Wx,以及语义空间向公共空间的映射矩阵Wy;
(9)对于新输入的测试数据,提取视频特征x’x′,并映射到公共空间,得到
(10)将所有候选的类别的语义特征映射到公共空间,得到其中m是测试数据的类别数。
(11)通过自训练来调整原型点,得到
(12)在公共空间中,找出与距离最近的这个所对应的类别就是测试数据的分类结果。
- 还没有人留言评论。精彩留言会获得点赞!