一种基于MPI的ML‑KNN多标签中文文本分类方法与流程
本发明涉及机器学习和高性能计算领域,具体涉及一种基于MPI编程并行化多标签分类算法ML-KNN。
背景技术:
近年来,信息技术迅猛发展,互联网数据规模随之呈海量增长,其表现形式也愈加丰富,然而传统的监督学习认为每个样本只有一个标签,对事物的复杂语义信息缺乏准确表述的能力,多标签学习(Multi-Label Learning)应运而生。多标签学习认为单个样本存在多个标签与之关联,与多个标签关联的样本能够更好的表述。近年来,多标签学习问题受到了机器学习学术界和工业界越来越多的重视,已成为机器学习界的研究热点之一。
ML-KNN(multi-label k Nearest Neighbor)是张敏灵和周志华提出的一种多标签分类算法,该算法是由经典的单标签学习算法KNN(k Nearest Neighbor)改进而来的。ML-KNN首先求出待预测样本的k个最近邻类别标签出现的先验概率和后验概率,再基于最大化后验概率的原则去确定待预测样本的标签集。算法在文本分类、生物信息学、信息检索、网页挖掘等诸多领域表现出了良好的效果。
设Ξ为特征空间,Ψ是有限个标签的集合。对于任一样本x(x∈Ξ),其标签的集合为样本x的类别向量,向量中的元素为(l∈Ψ),若l∈Y,则的值为1,否则为0。此外,定义N(x)为样本x在训练集中的K近邻的集合,其中样本之间相似度用欧氏距离度量,则成员统计向量被定义为:
用于统计在样本x的K近邻中标签为l的样本的个数。
对于测试样本t,表示事件:样本t含有标签l;则表示事件:样本t不含标签l;表示事件:在样本t的K近邻中,恰好有j个样本含有标签l。利用最大化后验概率准则(Maximum a Posteriori,MAP),测试样本t的标签向量为:
通过贝叶斯公式,上式可转换为:
是成立的先验概率,通过统计训练集中与标签l相关的样本数量得到;表示当成立时,测试样本t的K近邻中有个样本含有标签l的概率。
2.多标签文本分类
Internet上存在的海量数据主要包括文本、声音、图像数据等。其中,文本数据与其他数据相比,具有占用网络资源小的特点,这使得网上的数据大多是以文本的形式呈现的。为了有效的管理和利用这些文本数据,从中发现有价值的信息,基于内容的信息检索和数据挖掘技术倍受关注。而文本分类技术是信息检索的基础,其主要任务是按照预先定义的主题类别,为文档集合中的每个文档确定一个类别。
文本分类最初是应信息检索的需求而出现的,早期以人工构建分类器为主,经过几十年的发展,基于机器学习的文本分类技术成为了主流,该方法包涵文本预处理,特征选择,分类器的构建三个步骤,实现了文本的自动分类。在互联网广泛使用的今天,网络信息快速膨胀,基于机器学习的文本分类技术已成为信息检索与数据挖掘领域的核心技术。
文本分类可根据分类后类标签的个数分为单标签文本分类和多标签文本分类。区别于多类别文本分类,多标签文本分类是指单个文本具有两个及其以上的标签与之关联。在现实世界中,多标签文本分类是相当普遍的,比如,一篇新闻报道可能包含里约奥运会、女排、决赛等多个主题。
3.MPI
MPI(Message Passing Interface,消息传递接口)是由MPI论坛(MPI Forum)提出的一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准,具有高效率,方便移植,功能强大等特点。MPI是一个库,而不是一门独立的编程语言,可以被FORTRAN和C/C++调用,其适用于共享和分布式存储的并行计算环境,用它编写的程序可以直接在SMP(Symmetric Multi-Processor,对称式多处理器)集群上运行。
本发明旨在解决ML-KNN的具体实现中大规模分类问题,控制计算的时间和空间代价。鉴于VSM仍是文本表示的主要方法,导致样本的特征空间维度较高,在大规模分类问题中具有一定的特殊性。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种在处理高维数据的时候的中文文本分类方法。本发明的技术方案如下:
一种基于MPI的ML-KNN多标签中文文本分类方法,其包括以下步骤:
1)对训练集和待预测数据集中的所有文本进行预处理,包括分词,去停用词及去低频词在内的步骤;
2)对预处理后的训练集进行特征词汇提取得到特征词汇表,再根据特征词汇表对训练集和待预测数据集作文本矢量化表示;
3)构造分类器并分类:首先基于并行编程模型MPI将ML-KNN算法并行,然后使用训练集对并行后的ML-KNN分类器进行训练,最后使用训练好的ML-KNN分类器对待预测文本数据集进行分类,得到待预测文本数据集分类结果。
进一步的,所述步骤1)中的分词步骤是将原始文本中的中文句子按照一定的规范重新组合成词序列的过程;去除停用词的步骤是根据停用词汇表删除对分类没有意义的停用词汇,;去除低频词的步骤是指去掉某些只在极少的文本中出现过的单词,这样的词留在集合中会导致大部分文本样本在该特征词汇下的值为0。
进一步的,步骤2)特征的提取只针对训练集,具体做法是将预处理后的训练集进行词频统计,将在训练集中出现次数大于设定阈值T的单词加入特征词汇表,并计算特征词汇表中的每个单词的IDF值以及每个单词在文档中的词频TF,将含有IDF值和TF值的特征词汇表通过MPI_Bcast函数广播至各个进程,再在各个进程中求出与该进程相对应文档中单词的TF-IDF值,实现文档的向量化表示。
进一步的,步骤4)将ML-KNN分类器并行化的步骤包括:
首先将训练数据集以特征为单位均匀划分成p个特征数据列,再将每个特征数据列均与划分成q个特征数据子集,则原数据集被划分成了p*q个特征数据子集;
将划分好的特征数据子集通过MPI_Send函数传入p*q个进程中,各个进程
通过MPI_Recv函数接收,每个进程有且只有一个特征数子集,数据子集进
行距离运算,
再进行训练集特征矩阵的划分,得到近邻矩阵N(xj);
将由人工标记的训练集标签信息传入进程0,在进程0中计算先验概率同时利用得到的近邻矩阵N(xj)计算出后验概率
进而求出测试样本t对于标签l的概率Pt,l(b)以及t是否含有标签l。
进一步的,所述距离公式使用的距离公式为:
dist(a,b)=a*b+b2
其中a为当前样本的特征向量,b为目标样本的特征向量,dist(a,b)表示当前样本到其他目标样本的距离,计算过程中需要用到的其他特征数据子集通过调用广播函数MPI_Bcast传入。
进一步的,在进行广播前,需调用MPI_Comm_split函数将原始通信域划分成q个独立的通信域,即每个特征数据列所对应的进程为一个独立的通信域,然后将计算好的包括样本编号,特征名称信息,与近邻样本的距离信息在内的结果通过MPI_Gatherv函数收集到进程0,在进程0中通过加法运算即得到ML-KNN算法中所需的近邻矩阵N(xj)。
本发明的优点及有益效果如下:
本发明基于并行编程模型MPI将多标签文本数据的预处理、特征提取以及ML-KNN算法分类三个过程并行化,相比传统的串行方法,极大的提高了效率。值得一提的是,在数据的划分方面,相比其他并行方案的只以样本为单位划分,提出了一种新的针对文本数据的划分方法,即既可以以样本为单位划分,又可以以特征为单位划分,使得本发明在处理高维数据的时候,具有更大的优势。
附图说明
图1是本发明提供优选实施例是基于MPI的ML-KNN多标签中文文本分类流程图;
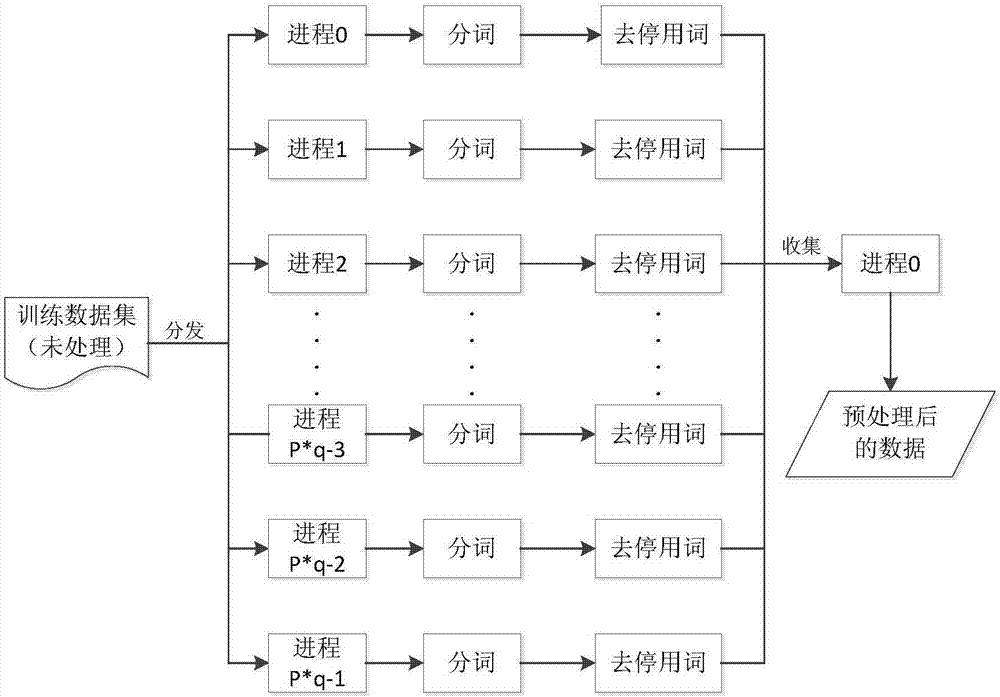
图2是基于MPI并行化的数据预处理流程图;
图3是基于MPI并行化的文本特征提取流程图;
图4是基于MPI并行化的文本向量化流程图;
图5是基于MPI的ML-KNN多标签学习算法并行—数据划分图;
图6是基于MPI的ML-KNN多标签学习算法并行—距离计算图;
图7是基于MPI的ML-KNN多标签学习算法并行—近邻矩阵求取;
图8是基于MPI的ML-KNN多标签学习算法并行—预测流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
本发明根据ML-KNN算法的特点,在MPI并行编程模型下并行化的实现了文本分类的每个步骤。包括文本数据预处理,文本特征提取及向量化,ML-KNN算法并行和分类几个部分。本发明具体按以下步骤实施:
(1)数据预处理。其中包括分词、去停用词、低频词三个部分。
(2)特征提取与向量化。包括词频统计,特征词汇表的构建,滤除不在特征词汇表中的词汇,计算特征词汇的IDF值,文档向量化,特征提取的目的是筛选出区分能力最强,最具有代表性的特征,向量化的目的是为了适应机器学习算法,即本发明中的ML-KNN算法。
(3)ML-KNN算法的并行化与分类。基于并行编程模型MPI将传统的ML-KNN算法并行,在保证精度的情况下提升分类的效率。
基于MPI的ML-KNN多标签中文文本分类流程如图1所示,下面将结合其他的附图对本发明的具体过程作进一步阐述。
1.数据预处理
此步骤是对训练集和待预测数据集中的所有文本进行处理,包括分词,去停用词,去低频词三个部分。分词是将原始文本中的中文句子按照一定的规范重新组合成词序列的过程;去除停用词是根据停用词汇表删除对分类没有意义的停用词汇,如:“啊”、“的”、“我”。低频词是指某些单词只在极少的文本中出现过,如一两个文本中出现,这样的词留在集合中会导致大部分文本样本在该特征词汇下的值为0,所以需要将这些低频词过滤掉。
在此步骤,文本数据的格式为:每行为一个样本(文本),包含文本名和文本内容。如图2所示,假设现有计算资源:p*q个进程(MPI以进程为单位)。首先进程0读入数据并将数据集以行为单位均匀划分成p*q个互不相交子集,再通过MPI_Send函数将划分好的子集传入p*q个进程中,且要求传入每个进程中的子集不相同,各个进程通过MPI_Recv函数接收子集,即每个进程中有且只有唯一的子集。其次,在每个进程中对其相应的子集进行分词,去除分词结果中包含在停用词汇表中的停用词并进行词频统计与去除低频词操作,待这些操作全部完成后,每个进程将其处理后的结果通过MPI_Gatherv函数收集到进程0,在进程0中进行合并得到预处理后的数据。
训练集和待预测数据集在此步骤是一致的,但此步骤中待预测数据集的中间结果将用于待预测数据集的向量化,而训练集的中间结果则是用于特征的提取。
2.特征的提取与向量化
本步骤中的特征的提取只针对训练集,具体做法是将预处理后的训练集进行词频统计,将在训练集中出现次数大于某个阈值T(本发明取值为5)的单词加入特征词汇表,并计算特征词汇表中的每个单词的IDF值。
在此步骤,输入是预处理后的训练数据集,其内容包括:文本名,文本分词后产生的词序列。如图3所示,与步骤1的划分方式相似,将预处理后的训练集以样本为单位均匀划分成p*q个互不相交子集传入p*q个进程,即每个进程有且只有唯一的子集,发送节点调用MPI_Send函数,接收节点调用MPI_Recv函数。在每个进程中,对与之相对应的子集进行词频统计操作,然后将统计后的结果通过MPI_Reduce函数归约求和,结果保存到进程0,返回的统计结果包括:该子集中所有的单词及该单词在该子集中出现的次数,该子集中的文档名以及该文档的单词个数。
进程0将每个进程返回的结果通过设置阈值的方式,选出词频超过阈值的单词,用以生成特征词汇表,本发明在此步骤阈值设置为5。再将特征词汇表通过MPI_Bcast函数广播至每个进程,在每个进程中,对每个特征词汇表中的单词,统计单词在不同的文档中出现的次数以及在每个文档中出现的次数,再通过MPI_Reduce函数将统计结果归约至进程0,得到总的该单词在不同文档中出现的次数以及在每个文档中出现的次数。然后通过汇总的两个值计算出每个单词的IDF值以及每个单词在文档中的词频TF,将含有IDF值和TF值的特征词汇表通过MPI_Bcast函数广播至各个进程,再在各个进程中求出与该进程相对应文档中单词的TF-IDF值,实现文档的向量化。最后,通过MPI_Gatherv函数将各进程向量化后的文档收集至进程0,如图4所示。
本过程中的文档向量化部分,训练集和待预测数据集保持一致。
3.ML-KNN的并行化与分类
本步骤将传统的多标签学习算法ML-KNN并行,以高效的对多标签文本进行分类。对于数据集的划分如图5所示,首先将训练数据集以特征为单位均匀划分成p个特征数据列,再将每个特征数据列均与划分成q个特征数据子集,则原数据集被划分成了p*q个特征数据子集。
将划分好的特征数据子集通过MPI_Send函数传入p*q个进程中,各个进程通过MPI_Recv函数接收,每个进程有且只有一个特征数子集。如图6所示,在每个进程中,对与之相对应的数据子集进行距离运算,距离计算公式使用的距离公式dist(a,b)=a*b+b2,为了并行的计算距离,同时提高计算效率。
其中a为当前样本的特征向量,b为目标样本的特征向量。Dist(a,b)表示当前样本到其他目标样本的距离。
阐述的距离公式。在对每个特征数据子集的距离运算中,需要用到该特征子集所在特征数据列的全部数据,本发明采用了与存储了该特征数据列数据的所有进程通过MPI_Bcast函数互相广播的方案,需要注意的是该方案需要先将存储该特征数据列的进程集合划分成一个独立的通信域,即有p个独立的通信域,再在每个通信域中进行广播。如图7所示。每个进程计算出不完整的距离值后,将结果使用MPI_Reduce函数归约求和到进程0,返回结果包括:文本名称,与其他样本的不完整距离向量。进程0再将返回的结果按样本为单位整合,得到距离矩阵。例如:样本A和样本B的特征被分到了p个进程中,在p个进程中分别计算了一次样本A到样本B的不完整距离,返回给了进程0p个不完整距离,只需将这p个不完整距离相加,即可得到真实的样本A到样本B的距离的度量。
利用求出距离矩阵,就可以求出每个样本的K个最近邻样本,由此得到近邻矩阵。近邻矩阵的求取待预测数据集与训练集是一致的。如图8所示,利用训练集的近邻矩阵N(xj)和多标签文本的标签信息,通过原始ML-KNN算法中的公式,即可求出先验概率和后验概率
对每个测试样本来说,通过与训练集一致的方式求出待预测数据集的近邻矩阵N(t),可进而求出将其代入训练集的后验概率中求得测试样本后验概率进而求出测试样本对于标签l的概率Pt,l(b),其计算方式如下:
其中b∈{0,1},Pt,l(1)表示测试样本t具有标签l的概率,Pt,l(0)表示测试样本t不具有标签l的概率。若Pt,l(1)大于Pt,l(0),则测试样本t对于标签l,其值被判定为1;若Pt,l(1)小于Pt,l(0),则测试样本t对于标签l,其值被判定为0。对待预测数据集中的所有样本重复上述步骤即可求出待预测数据集的标签集合。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!