一种面向大数据的并行系统优化方法与流程
本发明涉及面向大数据的并行系统优化方法。
背景技术:
数据密集型复杂算式是指需要计算大量数据并拥有复杂依赖结构算式,大多数涉及连加和连乘操作,如该算式的计算过程需要消耗大量的时间。数据密集型复杂算式是现有的大数据分析的基础,在数据分析领域有非常重要的应用,现有技术存在如下问题:
1、现有平台只提供基础的操作,如Hadoop中只提供了Map和Reduce的操作。这种模式对于没有经验的编程者来说是十分困难的。
2、现有工具包只提供了现有的算法中的计算算式计算方法,并不能提供普适性的算式计算方法。
3、在现有技术下,数据密集型复杂计算只能通过多轮的数据重分布完成,运行的时间大大增加。
数据密集型(复杂)算式指的是含有多个连加连乘等统计算以及计算数据量大的公式。
技术实现要素:
本发明是为了解决现有技术都是针对并行系统中的某一特定的算法,没有针对复杂计算表达式,且计算耗时长的问题,而提出的一种面向大数据的并行系统优化方法。
一种面向大数据的并行系统优化方法以下步骤实现:
步骤一:将数据密集型算式进行抽象化处理;
步骤二:将步骤一抽象化处理后的数据密集型算式生成算式语义树;
步骤三:将步骤二生成的语义树进行化简并生成算式依赖图;
步骤四:将步骤三生成的算式依赖图进行分层并生成任务序列;
步骤五:根据步骤四生成的任务序列在并行系统中生成任务依赖关系,执行后得到数据密集型算式的计算结果。
发明效果:
1.经过实验证明,该算法在数据量越大的情况下展现出越好的优化效果。在GB级别的数据量下,平均节约57.3%的计算时间。
2.经过实验证明,在该算法下,算式的计算时间不依赖于算式的复杂度,而依赖于算式生成的任务数量。
3.该算法具有普适性,可应用于不同的并行平台,如Hadoop和Spark;并不要求使用者的编程经验,给出复杂表达式即可得到优化的计算结果。
附图说明
图1为本发明流程图;
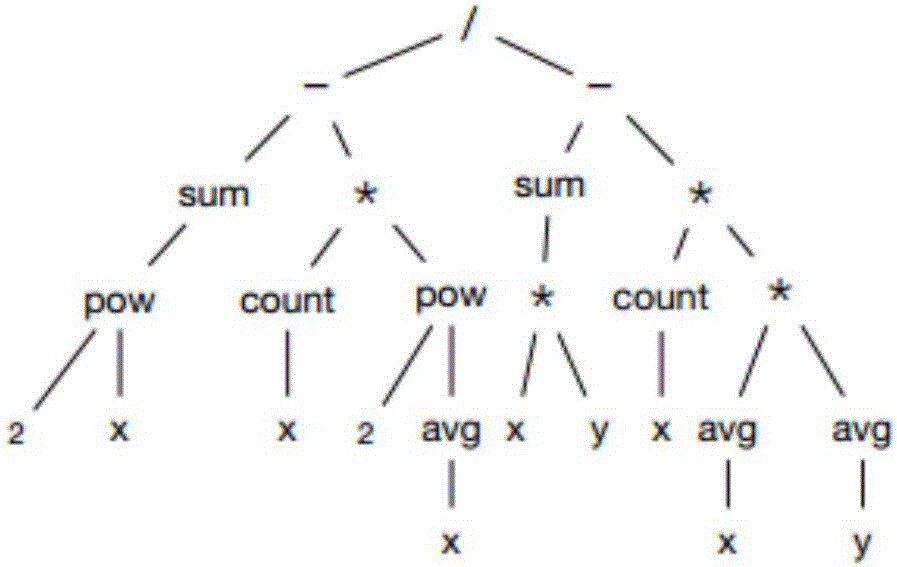
图2为语义树结构图;图中“/”代表除号,“-”代表减号,“*”代表乘号,“sum”代表连加符号,“pow”代表乘方符号,avg”代表平均数符号,“count”代表计数符号,“x”、“y”和“2”代表操作变量和操作数。
图3为化简过程图;
图4为分层示意图;
图5为生成的任务序列图;图中任务序列由下至上,MapReduce:avg()代表执行一轮平均数计算的映射归约操作;MapReduce:avg(),count()代表执行一轮平均数计算和计数计算的映射归约操作;MapReduce:sum()代表执行一轮连加计算的映射归约操作;共4轮MapReduce即映射归约操作。
图6为任务序列调度图;
图7为简单聚集运算配置图;图中,输入变量x,map映射成为Key:value即键值对,经过reduce归约成结果,valuesum连加结果,valuecount计数结果。配置操作符:sum和count,即为在归约过程中进行连加和计数操作。
图8为复杂聚集运算配置图;
图9为CCA、MCA、ACF优化前运行时间对比图;
图10为CCA、MCA、ACF优化后运行时间对比图;
图11为ACF优化前后对比图;
图12为MCA优化前后对比图;
图13为CCA优化前后对比图。
具体实施方式
具体实施方式一:一种面向大数据的并行系统优化方法包括以下步骤:
步骤一:将数据密集型复杂算式进行抽象化处理;
步骤二:将步骤一抽象化处理后的数据密集型算式生成算式语义树;
步骤三:将步骤二生成的语义树进行化简并生成算式依赖图;
步骤四:将步骤三生成的算式依赖图进行分层并生成任务序列;
步骤五:根据步骤四生成的任务序列在并行系统中生成任务依赖关系,执行后得到数据密集型算式的计算结果。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中将数据密集型算式进行抽象化处理具体为:
将数据密集型算式中的子运算分定义为简单计算和聚集计算两种,每一个聚集运算要用一轮MapReduce完成,将数据密集型算式进行函数式抽象;所述简单计算为四则运算、乘方和开方,聚集计算为统计运算,MapReduce为编程模型,用于大规模数据集(大于1TB)的并行运算。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤二中将步骤一抽象化处理后的数据密集型算式生成算式语义树具体过程为:
提取数据密集型算式中的变量,并确定子算式,将子算式中的运算符(加、减、乘、除、连加、连乘等)作为父节点,对应该运算符的计算变量作为子节点,生成算式语义树,所述语义树从叶子节点到根节点每一条路径上只有一个聚集运算。子算式如算式中的∑x2等。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤三中将步骤二生成的语义树进行化简并生成算式依赖图的具体过程为:
将语义树中所有对应相同变量的结点合并为同一结点,对相同变量进行相同计算的结点合并为同一结点。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤四中将步骤三生成的算式依赖图进行分层并生成任务序列的具体过程为:
根据算式依赖图中变量与运算符的距离进行分层,以任意变量作为初始节点,以变量到运算符经过的节点数作为运算符所在的层数,当变量与运算符之间有多条路径时,以经过节点数多的路径为准,其中每个运算符为一个节点;
提取每一层相同变量的聚集运算,按照初始节点到终结节点的顺序生成任务序列;每一层中不同变量的聚集运算并行放入一轮MapReduce中执行;每一层中相同变量的聚集运算串行放入一轮MapReduce中执行。
其它步骤及参数与具体实施方式一至四之一相同。
实施例一:如图1所示,一种面向大数据的并行系统优化方法的步骤为:
1、抽象算式结构
将算式中的子运算分为简单计算和聚集计算两种,每一个聚集运算要用一轮MapReduce完成。将算式进行函数式抽象,如将连加符号表示为sum(),抽象后进行下一步操作。将上式抽象为函数式表达式为:
2、生成算式语义树
根据算式的依赖关系生成如图2所示的语义树结构。
3、化简并生成算式依赖图
进行语义树化简。我们采用两个原则进行语义树化简。
All-to-1。所有对应相同变量的结点合并为同一结点,用于消除冗余的结点。
Same-to-1。对相同变量进行相同计算的结点合并为同一结点。这样相同的计算可以在同一个任务中进行,进而减少了数据重分布过程。
应用这两个原则对例子进行化简,如图3所示。化简后生成了算式依赖图,依据该算式依赖图生成算式的任务序列。
4、生成任务顺序
根据算式依赖图生成计算任务计划,该计算用于任务分配。首先,我们根据算式与变量的距离进行分层,如图4所示。
根据分层生成MapReduce任务,每一层的相同运算生成同一个任务,生成任务序列如图5所示。
5、并行系统执行
将任务序列生成并行系统中的job依赖关系序列,放入现有的大数据并行系统中执行。如图6所示。该算式生成3个MapReduce任务并行执行。
执行后,得到算式最终的计算结果。实验证明该算法可以极大的提升计算效率。
在Hadoop中实现了该算法。通过Job Configure文件进行系统配置。我们将配置过程分为简单聚集运算和复杂聚集运算。简单聚集运算配置在Reduce过程中直接进行配置,如图7所示。
复杂聚集运算配置则需要在Mapper中建树来确定运算过程,从而生成计算结果,如图8所示。
本发明方法可以在现有并行平台,如Sparks和Hyracks等平台中应用。仅需将配置条件稍作修改,适合于上述系统即可。
本发明方法作为数据分析的基础优化算法,可以应用于数据分析方向,如商业分析、金融、工业、农业等领域。
复相关分析Complex correlation analysis(CCA):
矩阵相关分析Matrix correlation analysis(MCA):
任意复杂算式Arbitrary complex formula(ACF):
运行时间对比图,如图9~图13可知,优化前后,运行时间出现大幅度缩减。并可以观察到数据量越大,优化效果越明显。
- 还没有人留言评论。精彩留言会获得点赞!