一种基于神经网络的水质评价分类方法与流程
本发明涉及模式识别与机器学习领域,特别涉及一种融合了lda,bpnn与adaboost的水质评价分类方法。
背景技术:
水质的预测与评价是水资源开发利用的重要组成部分,随着人口与经济发展,世界水资源的需求量不断增加,我国水资源也面临着质与量的双重挑战,其中水质挑战尤为突出。水质的好坏关系到人民的健康安全,关系到国民的生活品质,因此迫切需要解决我国的水质安全问题。所以研究水质评价分类方法有重要意义。但由于评价指标与水质等级间的非常复杂的非线性关系,以及水体污染的随机性和模糊性,对于水质评价至今没有一个被广泛接受的评价模型。目前水质评价方法有单因子评价法与综合评价法两大类。
美国是较早开始水质评价的国家。1965年,horton提出了水质质量指数(wqi),nemerow提出了内梅罗法,ross提出了利用生化需氧量,氨氮,悬浮物及溶解氧四项指标评价水质。目前水质评价不仅考虑物理和化学指标,还考虑生物指标,使得水质评价更加全面科学。我国水质评价工作开始于1973年,大体经过了4个阶段:初步尝试阶段,广泛探索阶段,全面发展阶段和环境影响评价阶段。初期仅限于城市或小范围区域的现状评价,如官厅水库环境质量评价,北京西郊环境质量评价等,之后开展了松花江,白洋淀,武昌东湖,昆明滇池,太湖等水环境的专题质量评价工作。20世纪90年代后,各种数学方法和模型的广泛应用使得水质评价方法得到进一步扩展。常见的有神经网络法,投影寻踪方法,灰色指数法,物元分析法等。现在,水质评价几乎成了所有综合环境质量评价中不可缺少的重要内容。
现在实行的地表水环境质量标准(gb3838-2002)中要求,地表水环境质量评价应根据应实现的水域功能类别,选取相应类别标准,进行单因子评价,即以单项指标最差所属级别确定其综合水质级别,这是符合实际的,因为若某项指标浓度严重超标,已不适合饮用,却仍评为可作为饮用水源地的三类水,将给人民生命健康带来威胁。但是单因子评价法各个参数之间没有联系,缺乏可比性,因此需要一种综合的水质评价方法。bpnn是一种行之有效的数据处理与分析算法,它的应用领域在不断扩大并逐渐完善,立足于bpnn,同时为提高鲁棒性,本方法提出使用lda算法对水质特征参数进行预处理,使用adaboost计算框架综合各个神经网络的运算结果以提高评价分类的精度。
技术实现要素:
本发明的目的正是为了克服传统单因子水质评价分类方法的缺点与不足,提供一种综合的水质评价分类方法,本发明使用lda线性判别分析对水质特征进行初始融合,使用bpnn算法训练多个神经网络,最后使用adaboost计算框架综合各个神经网络的计算结果对水质进行评价分类。
用于水质评价分类的测定方法,包括以下具体步骤:
步骤一:获取各个水域中各类水质参数,包括ph,温度,电导率,氧化还原电位,溶解氧,氨氮,高锰酸盐指数,总磷,铜,铅,锡共10项作为评价指标,并进行参数归一化处理。
步骤二:使用lda线性判决分析算法将原始的带标签的10维水质特征数据变换为5维水质特征数据。
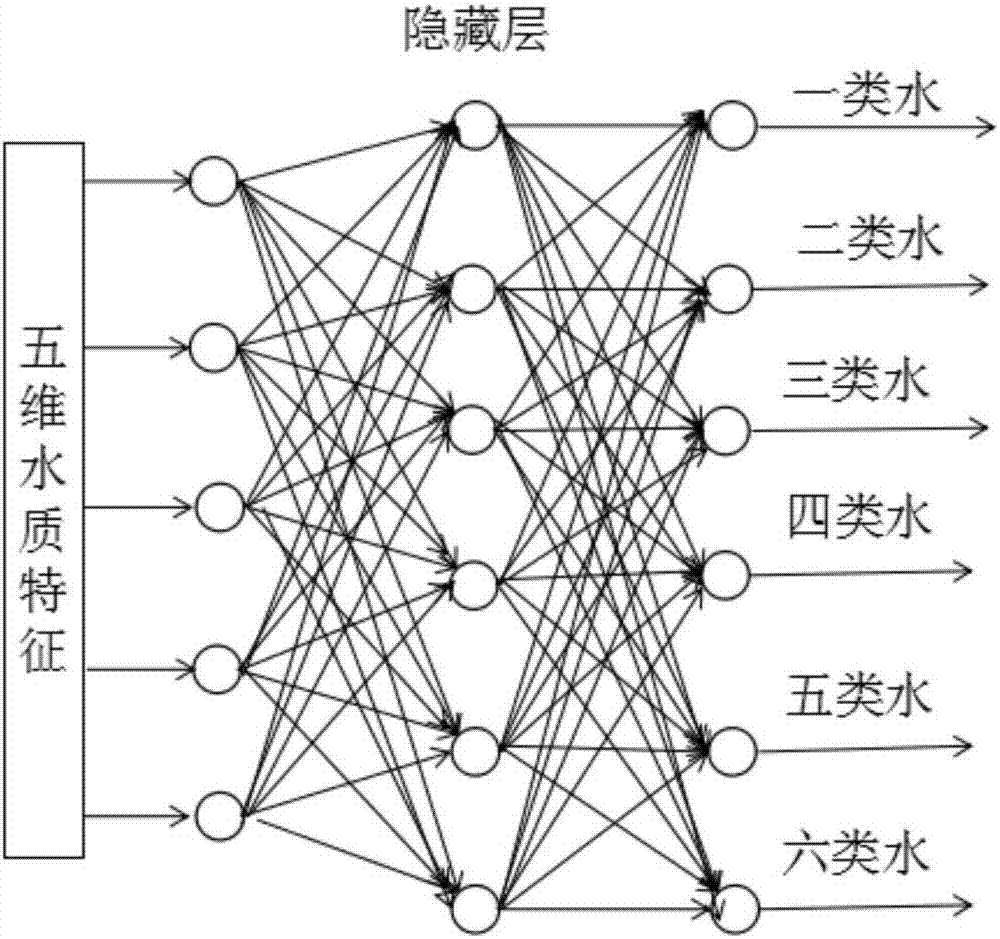
步骤三:构建5*6*6的神经网络结构,第一层为输入层,第二层为隐藏层,第三层为输出层,第一层节点对输入不进行函数变换,第二层以及第三层节点的转换函数为sigmoid函数,随机初始化网络权值,训练神经网络使得损失函数达到最小值,从而获得优化的网络连接权重。
步骤四:依据adaboost算法更新每个样本的权重,重新执行步骤三。
步骤五:重复执行步骤四直到训练所得神经网络分类准确率达到90%。
步骤六:使用adaboost算法综合步骤三,四,五训练得到的各个神经网络的运算结果,对水质做出评价预测。
进一步地,步骤一中由于获得的各类水质参数数值波动范围不一致,因此需要对水质参数进行归一化处理。
进一步地,在构建神经网络时,输入层的节点数由输入数据维数决定,输出层的节点数由水质分类的种类数决定,中间隐藏层的节点数与输入输出直接相关,即
4.进一步地,步骤四在更新权值时,减小被正确分类的样本的权重,增大被错误分类的样本的权重。在调整神经网络的权值时加入了冲量与动态的学习速率;
权值更新函数定义为:
其中δw(k)为第k次更新时权值的变化,η(k)为动态的学习速率,mse表示神经网络预测值与实际值之间的误差,w表示当前网络权值,mo(k)表示冲量,α为一个常数;
误差函数定义为:
其中n表示神经网络输出层的节点数,yi表示神经网络预测的第i个节点的输出,oi表示实际值;
自适应的学习速率函数定义为:
其中mse(k)表示第k次更新时的误差,mse(k-1)表示第k-1次更新时的误差;
冲量函数定义为:
mo(k)=δw(k-1)
其中mo(k)表示第k次权值更新时的冲量,δw(k-1)表示第k-1次权值更新时权值的变化量。
进一步地,步骤六在神经网络训练结束后利用adaboost计算框架对各神经网络的评价结果进行线性组合运算求取最后的预测结果。
进一步地,步骤六中,使用adaboost综合各个神经网络的分类结果,取结果最大的那一维序号作为对应水质的类别;综合各个神经网络分类结果的计算公式为:
其中t表示训练得到的神经网络个数,wt为各个神经网络的权重,ht(x)为各神经网络的输出结果。
本发明与现有技术相比,具有如下优点和有益效果:
1、特征太多会造成模型复杂,训练速度过慢,因此本发明引入了特征融合。本发明用lda线性判决分析算法进行水质特征融合,增大了类间距离,缩小了类内距离,减小了分类器的分类难度。
2、在使用梯度下降法最优化目标函数时,容易陷入局部最小值,因此本方法在神经网络权值更新时加入了冲量进行优化。
3、神经网络算法的突出问题是收敛速度问题,本方法通过对连续两次mse误差的比较,动态调整学习速率,使得本方法对误差曲面的变化更为敏感,使其具有更快的收敛速率。
4、adaboost针对同一个训练集训练了多个神经网络分类器,将这些分类器综合起来可以构成一个更强的最终分类器。使用adaboost可以排除一些不必要的训练数据,而将重点放在关键的训练数据上,从而提高了分类准确度。
5、本方法综合了多个水质参数的影响,相比传统的单因子评价法更加全面。
附图说明
图1是本算法融合了lda,bpnn,adaboost三种算法后的基本执行流程图。
图2是本算法所构建的神经网路的模型结构图。
图3是bpnn与adaboost结合的模型结构图。
具体实施方式
为了使本发明的目的,技术方案和优点更加清楚明白,以下结合具体实施方案,对本发明的实施作进一步的详细说明。
步骤一:获取各个水域中各类水质参数,包括ph,温度,电导率,氧化还原电位,溶解氧,氨氮,高锰酸盐指数,总磷,铜,铅,锡共10项,再对参数做归一化处理,如公式所示:
其中x*表示归一化处理后的参数值,x表示原参数值,min表示该参数在本样本空间中的最小值,max表示该参数在样本空间中的最大值。
步骤二:利用lda线性判决分析方法进行水质特征融合,这样有利于bpnn进行训练。lda算法是一种有监督的特征融合算法,若样本类型数为n,那么融合后样本特征维数为n-1,而水质类型有6类,因此10维水质特征数据进行特征融合之后维数变为5。
步骤三:参考gb3838-2002中国地表水环境质量标准,标准中将地表水分为6类,故输出层神经元个数确定为6。
输出水质分类为1-6类分别编码为:
一类水:[0.9,0.1,0.1,0.1,0.1,0.1]
二类水:[0.1,0.9,0.1,0.1,0.1,0.1]
三类水:[0.1,0.1,0.9,0.1,0.1,0.1]
四类水:[0.1,0.1,0.1,0.9,0.1,0.1]
五类水:[0.1,0.1,0.1,0.1,0.9,0.1]
六类水:[0.1,0.1,0.1,0.1,0.1,0.9]
本训练网络使用含一个隐藏层的神经网络。隐藏层节点个数与输入节点数以及输出节点数有关,即
权值更新函数定义为:
其中δw(k)为第k次更新时权值的变化,η(k)为动态的学习速率,mse表示神经网络预测值与实际值之间的误差,w表示当前网络权值,mo(k)表示冲量,α为一个常数,值为0.3。
误差函数定义为:
其中n表示神经网络输出层的节点数,yi表示神经网路预测的第i个节点的输出,oi表示样本标签向量第i维度的实际值。
自适应的学习速率函数定义为:
其中mse(k)表示第k次权值更新时的误差,mse(k-1)表示第k-1次权值更新时的误差。
冲量函数定义为:
mo(k)=δw(k-1)
其中δw(k-1)表示第k-1次权值更新时权值的变化量。
利用反向传播和随机梯度下降算法有监督地最小化误差函数,从而获得优化的网络连接权值,再计算分类的准确率。
步骤四:根据上一次的预测结果更新每个样本的权值。计算该神经网络在各样本下的总误差εt:
其中n表示样本总数。dt(i)表示对于第t个神经网络,第i个样本所占的权重。yt(xi)表示第t个神经网络,第i个样本对应的输出。oi表示第i个样本的实际值。yt(xi)=oi表示神经网络输出值与样本实际值相等,若两个值相等i(yt(xi)=oi)等于1,否则i(yt(xi)=oi)等于0。
样本的权值更新函数为:
其中dt(i)表示第t个神经网络中第i个样本的权重,dt-1(i)表示第t-1个神经网络中第i个样本的权重,样本被正确分类则εt前取负号,否则取正号。zt是使得
神经网络输出在最后结果中所占权重为:
重新执行步骤三。
步骤五:重复执行步骤四直到训练所得神经网络分类准确率达到90%。
步骤六:对步骤三,四,五所得的神经网络输出的结果向量做线性组合运算,取结果最大的那一维序号作为对应水质的类别。
线性组合函数定义为:
其中x表示输入样本,t表示训练所得的神经网络的数量,wt为各个神经网络的权重,ht(x)为各神经网络的输出结果。
本发明引入了特征融合。本发明用lda线性判决分析算法进行水质特征融合,增大了类间距离,缩小了类内距离,减小了分类器的分类难度。在使用梯度下降法最优化目标函数时,容易陷入局部最小值,因此本方法在神经网络权值更新时加入了冲量进行优化。本方法通过对连续两次mse误差的比较,动态调整学习速率,使得本方法对误差曲面的变化更为敏感,使其具有更快的收敛速率。adaboost针对同一个训练集训练了多个神经网络分类器,将这些分类器综合起来可以构成一个更强的最终分类器。使用adaboost可以排除一些不必要的训练数据,而将重点放在关键的训练数据上,从而提高了分类准确度。
- 还没有人留言评论。精彩留言会获得点赞!