基于机器视觉的多表字符识别系统及方法与流程
本发明涉及数字图像处理和仪表示数识别领域,尤其涉及到基于机器视觉的多表字符识别系统及方法。
背景技术:
数显仪表由于其精度高、稳定性好、安装使用方便、体积小等特点,目前被广泛地应用于机械制造、石油、化工等各个行业中,尤其在工业控制领域应用广泛。一般工业领域使用数显仪表时会采用多个数显仪表集中显示需要监测的数据,这样既节约空间资源又利于工作人员对生产数据进行实时的监测。
经走访调研发现珠三角地区多数陶瓷工厂的窑炉温度监测和控制虽然安装大量的现场指示仪表,但这些仪表不具有远传功能,需要现场读数,用来监控工业现场运行状况。虽然有数字温控仪表,但是还是需要人工进行抄表工作,定期以报告的形式将数据递交给生产主管进行分析。监控室仪表众多,人工抄表费时费力低效,而且容易引起误判;而且,常见的字符识别都是一图一表的单表识别,一台摄像机只拍摄一个电表,既占用空间,又浪费资源,不利于企业的长远发展。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种节省人力、工作效率高、能同时识别多个电表、电表识别率高、有效解决生产现场摄像头实时采集的大量图像和大量电表数据的存储问题、释放PC内存、节约资源的基于机器视觉的多表字符识别系统。
为实现上述目的,本发明所提供的技术方案为:基于机器视觉的多表字符识别系统,包括图像采集模块、网络存储模块以及软件处理模块;
图像采集模块为带有网络模块的摄像头,摄像头实时捕捉多电表图像;
网络存储模块为FTP服务器,摄像头网络模块将捕捉到的多电表图像上传至FTP服务器;
软件处理模块,对从网络存储模块下载到的多电表图像进行处理和识别;
其中,软件处理模块包括电表组分割单元、图像预处理单元、图像倾斜校正单元、图像增强单元、字符区域定位单元、字符分割单元、图像归一化单元、字符特征提取单元以及BP神经网络识别单元;
电表组分割单元,采集电表组中每个电表工作状态的图像并保存,作为后续匹配的模板,采用基于NCC模板匹配方法在电表组目标图像中进行全局搜索,找到与模板匹配的电表并分割出来;
图像倾斜校正单元,对数显式仪表进行Canny边缘检测,采用霍夫变换法求出图中最长直线及其斜率,计算出图像倾斜角度,对其进行旋转倾斜校正;
图像增强单元,对电表前20%像素进行增强而对其他的像素进行抑制;
字符区域定位单元,选用区域的最大梯度差MGD大于阈值的次数统计确定字符区域;
字符分割单元,对电表进行双向投影,从左向右定位出每个字符的起始和结束位置,并切割出来,通过垂直切割和水平切割得到字符的精确位置;
字符特征提取单元,采用局部统计特征的粗网格描述字符进行特征提取;
BP神经网络识别单元,采用具有在线训练功能的基于BP神经网络的识别方法识别字符。
进一步地,所述图像预处理单元包括灰度化处理单元、二值化处理单元以及形态学处理单元;
其中,灰度化处理单元,采用对RGB三分量进行加权平均得到较合理的灰度图像;
形态学处理单元,处理图像中目标区域的边缘,消除字符之间的黏连和椒盐噪声,使得前景图像区域变小,前景图像内部的背景区域被放大;
二值化处理单元,采用最大类间方差法Otsu实现二值化,将要识别的目标和图像的背景区分开来。
为实现上述目的,本发明还提供一种用于基于机器视觉的多表字符识别系统的方法,该方法包括以下步骤:
(1)图像采集;
将带有网络模块的摄像头安置在待测电表组前适当范围,进行多电表图像的实时捕捉;
(2)图像上传;
摄像头网络模块将捕捉到的多电表图像上传至FTP服务器;
(3)软件处理;
对从网络存储模块下载到的多电表图像进行处理和识别,最后将电表识别结果以.txt文本格式保存到本地PC指定盘,并以Excel表格形式导出。
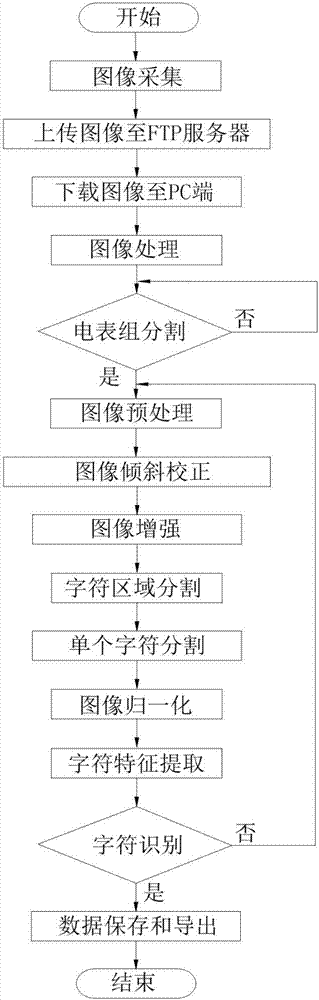
进一步地,步骤(3)中对图像处理和识别包括以下步骤:
1)电表组分割;
现场电表安装无规律,摄像机一次拍摄的电表数量多且位置不统一,所以需要将每块电表快速分割定位并进行实时识别;电表组通过模板匹配进行分割;先采集电表组中每个电表工作状态的图像并保存,作为后续匹配的模板,采用基于NCC模板匹配方法在电表组目标图像中进行全局搜索,找到与模板匹配的电表并分割出来;
而基于NCC模板匹配方法,其步骤如下:
(1获取模板像素并计算均值与标准方差、像素与均值diff数据样本;
(2根据模板大小,在目标图像上从左到右,从上到下移动窗口,计算每移动一个像素之后窗口内像素与模板像素的NCC值,与阈值比较,大于阈值则记录位置;
(3根据得到位置信息,使用红色矩形标记出模板匹配识别结果;
(4系统显示分割结果。
NCC计算公式为:其中,表示像素点p的灰度值,μ表示窗口所有像素平均值,σ表示标准方差,g表示模板像素值,m表示模板的像素总数,m-1表示自由度。
2)图像预处理;
预处理过程包括灰度化、二值化和形态学处理;灰度化采用对RGB三分量进行加权平均得到较合理的灰度图像;采用腐蚀等形态学处理图像中目标区域的边缘,消除字符之间的黏连和椒盐噪声,使得前景图像区域变小,前景图像内部的背景区域被放大,利于字符的识别;采用最大类间方差法Otsu实现二值化,将要识别的目标和图像的背景区分开来;
3)图像倾斜校正;
对数显式仪表进行Canny边缘检测后,图像中有明显的直线信息,采用霍夫变换法求出图中最长直线及其斜率,设直线公式为:y=kx+b,式中:k为直线斜率,b为直线在y轴上的截距,其中直线的斜率定义为:直线与直角坐标系正半轴方向夹角θ的正切值,其表达式为:k=arctanθ,计算出图像倾斜角度,对其进行旋转倾斜校正;
4)图像增强;
对电表前20%像素进行增强而对其他的像素进行抑制,到达增强目标字符抑制背景的目的,便于后续操作。
5)字符区域定位;
由于字符区域和背景对比度强烈,其梯度值较大,选用区域的最大梯度差MGD大于阈值的次数统计确定字符区域;
6)字符分割;
字符区域通常由多个字符组成,因此需要把字符串分割为单个字符才能识别,本方案采用投影法对电表进行双向投影,从左向右定位出每个字符的起始和结束位置,并切割出来,通过垂直切割和水平切割得到字符的精确位置;
7)图像归一化;
为了方便特征提取,把分割好的图像归一化到大小为15×21的图像。
8)字符特征提取;
采用局部统计特征的粗网格描述字符进行特征提取;
9)BP神经网络识别;
采用具有在线训练功能的基于BP神经网络的识别方法识别字符。
本方案原理如下:
摄像头实时捕捉电表组图像,并通过装在摄像头上的网络模块将图像上传至FTP服务器;当需要识别时,将多电表图像从FTP云端下载至本地PC,接着应用程序对图像进行电表组分割、图像预处理、图像倾斜校正、图像增强、字符区域定位、字符分割、图像归一化、字符特征提取、BP神经网络识别一系列的识别处理,最后将电表识别结果以.txt文本格式保存到本地PC指定盘,并以Excel表格形式导出。
与现有技术相比,本方案具有以下优点及有益效果:
能同时识别多个电表图像,大大节省人力资源和工作时间,通过使用FTP云端用以存储电表图像和电表识别数据,实现资源共享,并且解决了生产现场摄像头实时采集的大量图像和大量电表数据的存储问题,释放了PC内存,提高了电表识别效率。
附图说明
图1为本发明系统的结构示意图;
图2为本发明的多电表字符识别流程图;
图3为本发明中字符分割过程投影示意图;
图4为本发明中网格特征提取示意图;
图5为本发明中三层BP网络结构图。
具体实施方式
下面结合具体实施例对本发明作进一步说明:
参见附图1所示,本实施例所述的基于机器视觉的多表字符识别系统,包括图像采集模块1、网络存储模块2以及软件处理模块3;其中,软件处理模块3包括电表组分割单元3-1、图像预处理单元3-2、图像倾斜校正单元3-3、图像增强单元3-4、字符区域定位单元3-5、字符分割单元3-6、图像归一化单元3-7、字符特征提取单元3-8以及BP神经网络识别单元;图像预处理单元3-2包括灰度化处理单元3-2-1、二值化处理单元3-2-2以及形态学处理单元3-2-3。
工作时,流程如图2所示,图像采集模块1为带有4G网络模块的摄像头,实时捕捉多电表图像,并将捕捉到的多电表图像上传至网络存储模块2FTP服务器,需要识别时,从FTP服务器下载多电表图像至软件处理模块3,具体的处理识别步骤如下:
电表组分割单元3-1处理:
电表组通过模板匹配进行分割;先采集电表组中每个电表工作状态的图像并保存,作为后续匹配的模板,采用基于NCC模板匹配方法在电表组目标图像中进行全局搜索,找到与模板匹配的电表并分割出来;
NCC取值范围为[-1,1],目标图像即电表组图像的每个像素点都可以看作是RGB数值,相当于一个样本数据的集合,模板图像相当于它的子集。当模板与目标图像中另外一个样本数据相互匹配则它的NCC值为1,表示相关性很高,如果是-1则表示完全不相关,基于这个原理,实现图像基于模板匹配识别算法。首先对数据归一化,公式为:其中f表示像素点p的灰度值,μ表示窗口所有像素平均值,σ表示标准方差,假设g表示模板像素值,则其中m表示模板的像素总数,m-1是自由度。
基于NCC模板匹配方法,其步骤如下:
(1获取模板像素并计算均值与标准方差、像素与均值diff数据样本;
(2根据模板大小,在目标图像上从左到右,从上到下移动窗口,计算每移动一个像素之后窗口内像素与模板像素的NCC值,与阈值比较,大于阈值则记录位置;
(3根据得到位置信息,使用红色矩形标记出模板匹配识别结果;
(4系统显示分割结果。
灰度化处理单元3-2-1处理:
图像灰度化处理,采用加权平均法:将图像从RGB颜色空间转化为HSI色彩空间,在HSI空间中I就是图像的灰度值,H和S分别表示了图像的色调和饱和度,RGB三分量映射到H分量的公式:
饱和度分量的公式为:
强度分量为:
将三个分量以不同的权值进行加权,得到从彩色图像到灰度图的转换,公式为:I=030R+0.59G+0.11B。
二值化处理单元3-2-2处理:
采用最大类间方差法,最大类间方差可根据图像的灰度值选择合适的阈值对图像进行二值化处理,图像像素分为目标和背景两类,定义类间方差g描述目标和背景的差异,对于给定图像,有合适的阈值使该图像的类间方差g最大化,该阈值就为二值化的最佳阈值。其中ω0和ω1分别为前景和背景的比例,μ0和μ1分别为前景和背景像素的均值,μ为整个图像的像素均值,g为要求的最大类间方差。
μ=ω0×μ0+ω1×μ1
g=ω0(μ0-μ)2+ω1(μ1-μ)2
g=ω0ω1(μ0-μ1)2
形态学处理单元3-2-3处理:
采用腐蚀形态学处理图像中目标区域的边缘,使得前景图像区域变小,前景图像内部的背景区域被放大。
图像倾斜校正单元3-3处理:
对数显式仪表进行Canny边缘检测后,图像中有明显的直线信息,采用霍夫变换法求出图中最长直线及其斜率,设直线公式为:y=kx+b,式中:k为直线斜率,b为直线在y轴上的截距,其中直线的斜率定义为:直线与直角坐标系正半轴方向夹角θ的正切值,其表达式为:k=arctanθ,计算出图像倾斜角度,对其进行旋转倾斜校正;
图像增强单元3-4处理:
对电表前20%像素进行增强而对其他的像素进行抑制,到达增强目标字符抑制背景的目的,步骤如下:
首先统计图片中像素的最大值,然后对所用的像素值进行降序排序,排序后20%那一点的值level,最后对图像中每一点进行增强。
字符区域定位单元3-5处理:
从背景进入字符的梯度值Gin和从字符进入背景的梯度值Gout符号刚好相反,梯度的绝对值接近相等。在字符的附近选取某一区域,求得区域的最大梯度值Gmax和最小梯度值Gmin,则该区域的最大梯度差MGD,即为:
MGD=Gmax-Gmin
设定一个阈值,MGD大于阈值的可能是字符行或列。由于噪声干扰的存在,非字符图像有时也存在个别MGD大于阈值的情况。因此,选用MGD大于阈值的次数统计确定字符区域,此方法可对字符区域准确定位。
字符分割单元3-6处理:
由于字符区域彩色像素点较多,多聚集在一起;字符与字符之间有一定空隙,这些空隙多是像素值为0的背景像素。根据这个特点,对电表字段区域做垂直投影;数字区域对应的投影有明显峰值,以此为判断条件实现垂直分割;对垂直分割后的每个数字做水平投影,根据水平投影对实现单个数字的水平分割。通过垂直切割和水平切割后就得到了字符的精确位置。
原理如下:
投影如图3所示,图像函数为f(x,y),a为投影方向,b为与其垂直的方向,b与x轴夹角为θ,则f(x,y)沿着a的定义为:
当固定θ时,p(b,θ)是b的函数,是一个一维波形。改变θ,可得到不同方向上的f(x,y)的的投影。在x轴和y轴上的投影定义为Px,Py:
以x轴为投影轴,统计与x轴正交方向上所有图像点的灰度值总和。投影直方图可以非常直观的反映图像点相对于轴向的空间分布情况。对于大小为M*N的二值图像f(x,y),x轴的投影分布函数HX(x)为:
由于每个字符所在处都有黑色像素,而字符之间有一定的无黑色像素区。只要取x轴作为投影横轴,垂直投影,以投影的黑色像素个数作为纵坐标;再以y轴作为投影横轴,水平投影,投影的黑色像素个数作为横坐标。通过此方法就可以得到投影图,再根据投影图即可把字符分割开来。
图像归一化单元3-7处理:
将分割图像归一化为15×21;
计算需要缩放的比例:
计算图像缩放后的大小:
W=W×scale
H=H×scale
将缩放后的图像放在中间,在该图像上下左右补零至15×21;
字符特征提取单元3-8处理:
采用局部特征统计特征的粗网格进行特征提取。方法为:用OTSU方法将归一化后数字图像二值化,然后把图像分成几个局部小区域,并把每个小区域上的字符像素密度作为描述特征,即统计每个小区域中图像像素所占的百分比。针对大小为15×21的图像,划分为多个3×5的小区域,共15个。分别求得每个小方格内黑色像素的个数占这个小方格内总像素的百分比,形成一个3×5的矩阵,依次取每行元素转化为1×15的矩阵,作为神经网络的输入数据。
依次处理数字0到9,作为字符识别的特征,如图4所示。
BP神经网络识别单元3-9处理:
建立三层网络,由于输入是提取的每个数字的特征,共有15个数据,输出的对应的是0到9共十个数字,所以输入层和输出层神经元节点数分别为15和10。采用一般的经验公式(hide表示隐含层个数,m和n分别为输入层和输出层节点数,a取1-10的常数)来确定隐层节点层数,经过多次试验确定最终的隐层节点层数为15:通过试验验证,当隐含层达到15个节点数时,系统的训练和误差都达到理想的状况,所以网络的输入层、隐含层和输出层神经元节点数分别为15、15和10。取了O至9共十个数字作为待识别数,每个数字取10个样本进行训练,共有100个训练样本,另取10个样本作为识别样本。当输入图像0~9后,在输出神经元对应的位置上为1,其他的位置为O;输入数字0,第一个输出神经元为l,其他为0;输入数字1,第二个输出神经元为1,其他为O:依此类推。识别时,如果某个输出神经元的权值大于等于0.8,则认为该数字图像为对应的数字。如果所有的输出神经元的权值都小于0.8,则系统认为无法识别,如图5所示。
最后将电表识别结果以.txt文本格式保存到本地PC指定盘,并以Excel表格形式导出。
本实施例通过一系列操纵对电表组处理识别,一次可同时识别20-30个电表。使用FTP服务器存储电表图像和电表识别数据,实现资源共享的同时解决了生产现场摄像头实时采集的大量电表图像和大量电表数据的存储问题,释放了PC内存,提高了电表识别效率。通过现场测试,字符的识别率可达98%,平均每幅图像的识别时间在10ms以内。该系统具有识别速度快,抗干扰能力强,正确率高的优势,在保证识别正确率的前提下,大大提高了效率,时间仅为同等数量单表识别的1/10。并且,该系统针对不同型号不规则放置的多表识别同样适用。
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!