显示从输入图像检测到的对象物的图像处理装置的制作方法
本发明涉及一种显示从输入图像检测到的对象物的图像处理装置,特别是涉及一种检测在图像中拍摄到的多个对象物的影像位置,为了使操作者确认检测到的对象物的影像是否正确而显示检测结果的图像处理装置。
背景技术:
一般在使用图像处理装置从拍摄装置视野内的图像中检测特定的对象物的影像时,在表示对象物的基准信息(一般称为模型图案或模板等)与通过拍摄装置取得的输入图像之间进行特征量的匹配,当一致度超过指定的等级(阈值)时判断为成功检测对象物。
但是,即使一致度超过了阈值,实际上也不一定正确地检测到对象物的影像。因此,为了调整一致度的阈值等检测参数,操作者有时通过目视来确认是否正确检测到对象物。为了确认是否正确检测到对象物,多采用在输入图像上的检测位置绘制模型图案的原点、包围模型图案的矩形、模型图案的形状这样的方法。
并且,不仅在从输入图像检测对象物的情况下,还在检查输入图像中的对象物的情况下,在参数调整的阶段需要由操作者目视来确认好坏判定结果是否妥当。在这种情况下,优选对缺陷部分着色,或者使用不同的颜色包围作为不良品的对象物,以便容易理解地显示判定结果。
另外,存在基于检测结果和好坏判定结果,进行用于提高对象物检测准确度的机器学习和用于改良模型图案的统计处理的情况。在称为机器学习的有教师学习的方法中,赋予输入数据及其标签(ok/ng和种类)。为了基于检测结果和好坏判定结果进行有教师学习,进行检测结果和好坏判定结果是否正确的确认,如果具有不正确的结果,则通过按钮或文本框等来修正标签。另外,在统计处理中,针对好的判定结果的对象物的影像进行处理,或者使用好坏的判定结果来计算用于判别好坏的阈值。在这里,在学习中包含机器学习以及统计处理。
日本特开2007-114843号公报记载了操作者输入好坏判定结果,根据图像和好坏判定结果,设定用于进行好坏判定的阈值的好坏判定。通过选择图像文件名来进行图像的选择,如果不一个一个地打开图像则无法确认好坏判定结果。另外,设想针对图像为一个好坏判定结果,但是没有设想判定图像内的多个对象物的好坏。
国际公开第2001/041068号记载了一种缺陷检查系统,当变更了缺陷抽出的参数时,针对存储的全部图像再度进行缺陷抽出,并与该好坏判定一同显示缩略图像。另外,在进行新的缺陷判定时,在图像上图示多个被判定为缺陷的部分。在这里,为了放大判定为缺陷的区域,或者在缺陷辞典中登录该缺陷,需要在图像上点击缺陷部分。因此,无法同时放大多个缺陷来进行显示。另外,登录缺陷的作业也很繁杂。
特开2013-142558号公报记载了外观检查装置,其在设定了好坏的图像群中新追加了作为良品的图像时,根据良品的图像群计算判定阈值,并通过该阈值确认不良品是否被判定为不良品。在该专利中能够一张一张地显示图像来修正好坏,但是难以容易地确认大量图像的好坏。另外,没有考虑针对一张图像判定多个部位。
如上所述,在确认检测结果和好坏判定结果时,多采用在图像上绘制检测结果和好坏判定结果这样的方法。
但是,该方法存在以下的问题:
在从一个图像检测多个对象物时,如果检测结果重叠或者检测结果相邻接,则难以确认正确性。并且,在修正标签时,难以将进行修正的按钮、复选框等与检测结果对应起来。
如果针对图像的检测结果的尺寸小,则难以确认正确性。
技术实现要素:
本发明的目的在于提供一种图像处理装置,其显示从输入图像中检测到的对象物,以便容易地进行检测结果和好坏判定结果的确认。
图像处理装置具备:对象物检测单元,其基于对象物的模型图案,从拍摄对象物而得到的输入图像检测对象物的一个乃至多个影像;检测结果显示单元,其针对检测出的各个影像,以图形方式重叠显示检测结果,检测结果显示单元具备:第一框体,其显示整个所述输入图像;第二框体,其一览显示包含从该输入图像检测出的一个乃至多个影像中的各个影像的部分图像,在第一框体中显示的输入图像中,针对检测出的全部的影像重叠显示检测结果,在第二框体中显示的部分图像中,重叠显示与各个部分图像对应的影像的检测结果。
附图说明
通过参照以下的附图,能够更加明确地理解本发明。
图1是表示第一实施方式的图像处理装置的结构的框图。
图2表示使用了第一实施方式的图像处理装置的结构例子。
图3表示使用了第一实施方式的图像处理装置的其他结构例子。
图4表示拍摄到的输入图像与图像坐标系的关系。
图5是表示第一实施方式的图像处理装置的处理流程的流程图。
图6表示对象物的模型图案的例子。
图7表示与模型图案相关的数据的形式例子。
图8表示输入图像一览画面的显示例子。
图9表示在图8的状态下点击了第二标签的修正按钮后的显示例子。
图10表示检测结果一览画面的显示例子。
图11表示在图10的状态下点击了第一标签的修正按钮后的显示画面。
图12表示检测结果一览画面的其他显示例子。
图13表示检测结果一览画面的另一显示例子。
图14表示检测结果一览画面的另一显示例子。
图15表示检测结果一览画面的另一显示例子。
图16表示在以相同的姿态显示部分图像上的对象物的影像时的检测结果一览画面的显示例子。
图17表示在以原有的尺寸比同时显示不同尺寸的对象物的影像时的检测结果一览画面的显示例子。
图18是表示第二实施方式的图像处理装置的处理流程的流程图。
图19表示在第二实施方式中使用的检测结果一览画面的显示例子。
图20表示通过步骤s204显示的检测结果一览画面的显示例子。
图21表示修正了第一标签时的检测结果一览画面的显示例子。
图22示意地表示神经元的模型。
图23示意地表示将图22所示的神经元进行组合而构成的三层神经网络。
图24表示第一以及第二实施方式的学习单元22的概要结构。
具体实施方式
以下,参照附图对显示从输入图像检测到对象物的图像处理装置进行说明。然而,希望可以理解本发明并不限于附图或以下说明的实施方式。
在实施方式的说明中,如下那样使用记号。为了明确地进行说明,首先对记号进行说明。
np:构成模型图案的特征点的数量
p_i:模型图案的第i个特征点(i从1到np)
ni:输入图像的数量
i_j:第j个输入图像(j从1到ni)
nt_j:从第j个输入图像i_j检测到的对象物的影像的数量
t_jg:从第j个输入图像i_j检测到的第g个对象物的影像(g从1到nt_j)
l1_jg:从第j个输入图像i_j检测到的第g个对象物的影像的第一标签
l2_j:第j个输入图像i_j的第二标签
图1是表示第一实施方式的图像处理装置的结构的框图。
如图1所示,第一实施方式的图像处理装置10具有运算部20、存储部30、显示部40以及操作部50。在图像处理装置10上连接了视觉传感器11、操作盘12、显示装置13等。运算部20包含对象物检测单元21以及学习单元22。存储部30包含模型图案存储单元31、学习数据存储单元32、检测结果存储单元33。显示部40包含检测结果显示单元41以及输入图像显示单元42。操作部50包含部分图像选择单元51以及输入图像选择单元52。图像处理装置10中包含的各部分在具有cpu、rom、ram等的计算机上通过软件来实现。
视觉传感器11通过通信线缆与图像处理装置10相连接。视觉传感器11向图像处理装置10供给拍摄到的图像数据。操作盘12通过通信线缆与图像处理装置10相连接。操作盘12用于操作在显示装置13中显示的画面。显示装置13通过通信线缆与图像处理装置10相连接。在显示装置13中显示由视觉传感器11拍摄到的图像和检测结果等。此外,视觉传感器11、操作盘12以及显示装置13也可以与图像处理装置10为一体。显示装置13是具有crt、液晶面板等的显示设备。操作盘12可以是鼠标和键盘,也可以是显示装置13上的触摸屏。
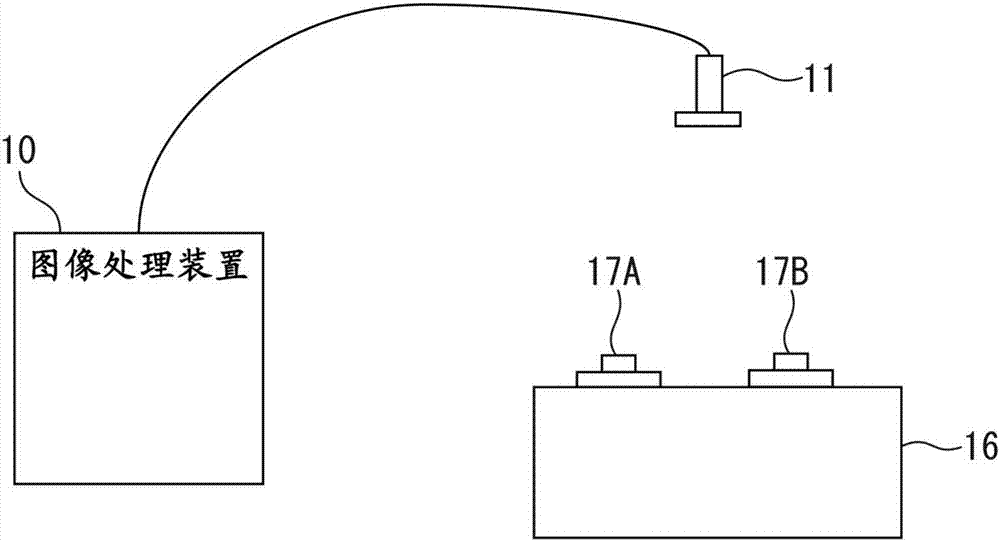
图2表示使用了第一实施方式的图像处理装置10的结构例子。
如图2所示的那样,在能够拍摄对象物17a以及17b的位置固定设置视觉传感器11,并将对象物17a以及17b放置在作业台16上。放置在作业台16上的对象物17a以及17b可以是单个也可以是多个。视觉传感器11可以是拍摄灰度图像或彩色图像的照相机,也可以是能够取得距离图像的立体照相机或三维传感器。
在第一实施方式中,以使用照相机作为视觉传感器11,视觉传感器11输出灰度图像的方式来进行说明。照相机例如是具有ccd(chargecoupleddevice,电荷耦合器件)等拍摄元件的电子照相机,是具有通过拍摄来在拍摄面(ccd阵列面上)上检测二维图像的功能的众所周知的受光设备。此外,以下将拍摄面中的二维坐标系称为图像坐标系。
图3表示使用了第一实施方式的图像处理装置10的其他结构例子。
如图3所示,可以在机器人1的机头(机械手)2等可动部上设置视觉传感器11。另外,也可以在机器人1的机头上抓持对象物17a以及17b,进行移动以使对象物17a以及17b进入固定设置的视觉传感器的视野内。机器人1通过通信线缆连接,由机器人控制装置3进行控制。机器人控制装置3在机器人1的控制中利用来自图像处理装置10的处理结果。
图4表示拍摄到的输入图像与图像坐标系的关系。
如图4所示,输入图像100具有长方形的图像面,并具有与长方形的边相对应的图像坐标系110。通过图像坐标系110的xy坐标来表示图像面上的位置。在图4的输入图像100中,包含三个对象物的图像200a~200c。此外,在以下的说明中,存在将对象物的图像简称为对象物的情况。
图5是表示第一实施方式的图像处理装置的处理流程的流程图。
根据学习单元22进行的处理,操作者在图像处理装置中进行的操作以及处理的内容不同。在这里,首先以学习单元22进行统计处理的情况为例进行说明。
在步骤s101作成在对象物的检测中使用的模型图案。
第一实施方式中的模型图案由多个特征点构成。作为特征点能够使用各种点,在第一实施方式中使用边缘点作为特征点。边缘点是图像中亮度梯度大的点,能够用于取得对象物的轮廓形状。抽出边缘点的方法是众所周知的。可以以任意的粒度来取得边缘点,在这里针对一个像素抽出一个边缘点。
特征点并不限于边缘点,例如也可以使用sift这样的特征点。从图像抽出sift特征点的方法如“objectrecognitionfromlocalscale-invariantfeatures”,davidg.lowe,proc.oftheinternationalconferenceoncomputervision,corfu(sept.1999)等中记载的那样是众所周知的。
特征点至少具有位置。在将边缘点的亮度梯度的方向定义为特征点的姿态时,能够与位置合并来定义特征点的位置姿态。在第一实施方式中,特征点具有位置、姿态。
图6表示对象物的模型图案的例子。如图6所示的那样,对象物200的模型图案由多个特征点(边缘点)p_i(i=1~np)构成。构成模型图案的特征点p_i的位置姿态可以通过任意的形式来表现,作为一个例子,举出如下方法:在模型图案中定义坐标系(以下称为模型图案坐标系),通过从模型图案坐标系看到的位置矢量和方向矢量等来表现构成模型图案的特征点的位置t_pi(i=1~np)和姿态v_pi(i=1~np)。
另外,模型图案坐标系的原点可以任意定义。例如,可以从构成模型图案的特征点中选择任意一点,将该点定义为原点,也可以将构成模型图案的全部特征点的重心定义为原点。
模型图案坐标系的姿态(轴的方向)也可以任意定义。例如,可以定义为在做成了模型图案的图像中图像坐标系与模型图案坐标系平行,也可以定义为从构成模型图案的特征点中选择任意的两点,从其中一方朝向另一方的方向成为x轴方向。
图7表示与模型图案相关的数据的形式例子。
如图7所示的那样,针对各特征点通过位置以及姿态来表现与模型图案相关的数据。以图7所示的形式(位置、姿态)在模型图案存储单元31中存储构成模型图案的特征点p_i。
在步骤s102,取得包含对象物的影像的一个乃至多个输入图像i_j(j=1~ni)。输入图像通过在视觉传感器11的视野内配置对象物来拍摄图像而取得。优选在与实际的生产线相同的环境下拍摄图像。可以大量保存实际在生产线上拍摄到的对象物的图像,并使用这些图像。可以在一张输入图像中拍摄到多个对象物。
在步骤s103,通过对象物检测单元21对各个输入图像i_j(j=1~ni)进行模型图案与输入图像i_j的匹配,进行对象物的检测。将检测结果与输入图像i_j对应起来存储在检测结果存储单元33中。此外,将直到进行以下的学习处理为止的一连串处理的结果存储在检测结果存储单元33中。对象物检测单元21检测对象物的方法有各种各样,例如,作为众所周知的方法,能够利用如下方法:“generalizingthehoughtransformtodetectarbitraryshapes”,d.h.ballard,patternrecognitionvol.13,no.2,pp.111-122,1981中记载的广义霍夫变换、“randomsampleconsensus:aparadigmformodelfittingwithapplicationstoimageanalysisandautomatedcartography”,martina.fischler,etal.,communicationsoftheassociationforcomputingmachineryvol.24no.6pages381-395,june1981中记载的ransac等。另外,在本实施方式中,将一致度虽然不足阈值但是一致度在预先设定的范围内的对象物的影像也追加为检测结果。例如,在以0~100定义一致度时,允许到一致度的阈值减去10得到的一致度为止。即使这样一致度也不足阈值的检测结果,也能够在后面的步骤中作为正确的检测结果来变更标签。
作为进行了检测的结果,从输入图像i_j检测出nt_j个对象物的影像。另外,将检测到的影像设为t_jg(g=1~nt_j),将影像t_jg的检测位置设为r_tjg。检测位置r_tjg是表示从图像坐标系观察到的对象物的影像t_jg的位置姿态,即对影像t_jg重合了模型图案时从图像坐标系观察到的模型图案坐标系的位置姿态的齐次变换矩阵,通过下式来表示。
例如,在对象物相对于照相机的光轴不倾斜,作为在图像中拍摄到的对象物的影像的移动只考虑全等变换即可时,a00~a12如下那样。
a00=cosθ
a01=-sinθ
a02=x
a10=sinθ
a11=cosθ
a12=y
其中,(x、y)是图像上的位置,θ是图像上的旋转移动量。
另外,在对象物相对于照相机的光轴不倾斜,但是对象物与照相机的距离不固定时,根据距离在图像中拍摄到的对象物的影像的大小进行变化,因此作为在图像中拍摄到的对象物的影像的移动成为相似变换。此时,a00~a12如下那样。
a00=s·cosθ
a01=-s·sinθ
a02=x
a10=s·sinθ
a11=s·cosθ
a12=y
其中,s是示教的模型图案的大小与对象物的影像t_jg的大小的比。
将检测位置r_tjg与输入图像i_j成对存储在检测结果存储单元33中。
基于从各输入图像i_j(j=1~ni)检测到的对象物的影像t_jg(j=1~ni、g=1~nt_j)的检测位置r_tjg,对构成模型图案的特征点p_i的位置姿态进行变换,并与图像上的对象物的影像重合。
为了说明,分别通过齐次变换矩阵r_pi来表示构成模型图案的特征点p_i的位置姿态。r_pi能够如下那样记载。
b00=vx_pi
b01=-vy_pi
b02=tx_pi
b10=vy_pi
b11=vx_pi
b12=ty_pi
其中,t_pi=(tx_pi,ty_pi)是模型图案坐标系中的p_i的位置,v_pi=(vx_pi,vy_pi)是模型图案坐标系中的p_i的姿态。
在这里,需要注意构成模型图案的特征点p_i的位置姿态r_pi通过模型图案坐标系来表现。
在把对输入图像i_j中拍摄到的对象物的影像t_jg重合了模型图案时的从图像坐标系观察到的特征点p_i的位置姿态设为r_pi′时,对于r_pi′使用从模型图案坐标系观察到的特征点p_i的位置姿态r_pi以及从图像坐标系观察到的影像t_jg的检测位置r_tjg,表现为以下那样。
r_pi′=r_tjg·r_pi
此外,为了后面的说明,将从图像坐标系观察到的p_i的位置设为t_pi′,将从图像坐标系观察到的p_i的姿态设为v_pi′。
在这里,对各对象物的影像t_jg赋予第一标签l1_jg(j=1~ni,g=1~nt_j)。在第一实施方式中,能够作为对象物的影像的标签选择的是“ok”、“ng”这两个。在第一实施方式中,将检测到的对象物的影像内的一致度为阈值以上的全部对象物的影像的第一标签l1_jg设为“ok”。将检测到的对象物的影像内的一致度不足阈值的对象物的影像的第一标签l1_jg设为“ng”。
在步骤s104,使用者确认从各输入图像i_j(j=1~ni)检测到的对象物的影像t_jg(j=1~ni,g=1~nt_j),并修正标签。确认赋予了“ok”的对象物的影像,在判断为不是对象物时,将第一标签变更为“ng”,并存储该修正后的标签。并且,确认赋予了“ng”的对象物的影像,在判断为应检测为对象物时,将第一标签变更为“ok”,并存储该修正后的标签。
在第一实施方式中,往复由输入图像显示单元42显示的输入图像一览画面和由检测结果显示单元41显示的检测结果一览画面,由此来确认对象物的影像t_jg(j=1~ni、g=1~nt_j)。
在显示装置中显示输入图像一览画面和检测结果一览画面。可以并列显示两个画面,也可以交替显示两个画面。在第一实施方式中说明交替显示两个画面的方法。
图8表示输入图像一览画面的显示例子。
在输入图像一览画面中,如图8所示那样一览显示全部的输入图像i_j(j=1~ni)。例如,按照以下的规则来进行该显示。
*在画面内按照指定的倍率来排列显示输入图像。在第一实施方式中输入图像的尺寸全部相同,但是输入图像的尺寸也可以不同。
*根据画面的尺寸和输入图像的尺寸以及倍率来自动决定画面内的图像的列数或行数。
在无法显示出全部的图像时,显示滚动条。通过滚动条能够使画面滚动来阅览全部的图像。滚动条可以纵向出现,也可以横向出现。
*输入图像的显示倍率能够通过倍率下拉来指定。可以相比原图像放大显示,也可以缩小显示。
说明在输入图像中拍摄到的对象物的影像上绘制模型图案的步骤。模型图案的绘制可通过以下的步骤来进行。
(1)针对全部输入图像i_j(j=1~ni)进行以下(2)的处理。
(2)针对从输入图像i_j检测到的全部对象物的影像t_jg(g=1~nt_j)进行以下(2-1)~(2-2)的处理。
(2-1)基于对象物的影像的位置r_tjg来计算从图像坐标系观察模型图案的全部特征点p_i(i=1~np)时的位置r_pi′。
(2-2)在输入图像i_j的位置r_pi′上绘制点。在第一标签l1_jg为“ok”时通过绿色绘制,在第一标签l1_jg为“ng”时通过红色绘制。可以将特征点p_i不绘制为点,而是绘制为线段。因此,将第一标签l1_jg表现为通过绿色或红色显示的对象物的一连串的特征点。
对第二标签进行说明。
*各输入图像具有第二标签l2_j(j=1~ni)。
*在各输入图像的左上方配置了第二标签的修正按钮。第二标签的修正按钮也可以配置在输入图像的下方等图像外。
基于第一标签l1_jg(g=1~nt_j)如下那样决定第二标签l2_j。如果相同的输入图像内的全部对象物的影像的第一标签l1_jg为“ok”,则使第二标签l2_j为“ok”。
如果在相同输入图像内的对象物的影像中只要有一个第一标签l1_jg为“ng”,则使第二标签l2_j为“ng”。
第二标签的修正按钮如下那样显示。
将第二标签显示为在第二标签的修正按钮上方显示的标签。
关于第二标签的修正按钮的背景颜色,在为“ok”时为绿色,在为“ng”时为红色。
在点击了第二标签的修正按钮时,第二标签l2_j在“ok”与“ng”之间切换。另外,与之相配合,将相同图像内的全部对象物的影像的第一标签l1_jg也变更为与l2_j相同。按照第一标签l1_jg和第二标签l2_j的变更,画面也更新。
图9表示在图8的状态下点击了第二标签的修正按钮后的显示例子。从第一行的左侧开始第二个图像的第二标签从“ok”变为“ng”。
当在输入图像一览画面中点击了输入图像i_j时,转移到一览显示该输入图像的检测结果的检测结果一览画面。
图10表示检测结果一览画面的显示例子。
如图10所示的那样,在检测结果一览画面中,如以下那样一览显示选择的输入图像i_j的对象物的影像t_jg(g=1~nt_j)。
*在检测结果一览画面中显示第一框体和第二框体。
*在第一框体和第二框体中,能够变更为不同的图像的显示倍率。
*能够变更第一框体和第二框体的大小。例如,能够通过拖移第一框体和第二框体的边界线来改变两个框体的大小。
*在点击了返回按钮时,能够返回到输入图像一览画面。
在第一框体中显示全体图像。
*在操作了第一框体的倍率下拉时,能够变更全体图像的显示倍率。
*在全体图像无法收纳在第一框体中时,显示滚动条。
*在全体图像中,能够通过与在输入图像一览画面的图像中绘制模型图案相同的方法,在检测到的对象物的影像上绘制模型图案。
在第二框体中显示部分图像。
*在操作第二框体的倍率下拉时,能够变更部分图像的显示倍率。
*在全部的部分图像无法收纳在第二框体中时,显示滚动条。滚动条可以纵向出现,也可以横向出现。
*针对各对象物的影像t_jg(g=1~nt_j)制作部分图像。通过以下的步骤来制作部分图像。
1.在输入图像的检测到的对象物的影像上绘制模型图案。针对对象物的影像t_jg进行以下的处理(1-1)~(1-2)即可。
(1-1)基于对象物的影像的位置r_tjg来计算模型图案的全部特征点p_i(i=1~np)的从图像坐标系观察时的位置r_pi′。
(1-2)在输入图像i_j的位置r_pi′上绘制点。在第一标签l1_jg为“ok”时用绿色绘制,在第一标签l1_jg为“ng”时用红色绘制。也可以将特征点p_i不绘制为点,而绘制为线段。
2.求出计算出的全部r_pi′(i=1~np)的位置t_pi′=(tx_pi,ty_pi)的x方向的最大值tx_pi_max、最小值tx_pi_min和y方向的最大值ty_pi_max、最小值ty_pi_min。
3.将用于切出来自输入图像的部分图像的形状设为矩形,通过左上的顶点位置和右上的顶点位置来定义矩形。在将空白设为α时,能够将左上的顶点位置计算为(tx_pi_min-α,tx_pi_min-α),将右下的顶点位置计算为(ty_pi_max+α、ty_pi_max+α)。空白α可以是预先决定的值,也可以根据图像的尺寸等计算出来。
4.通过计算出的矩形从输入图像切出,作为部分图像。
在通过部分图像选择单元51选择了部分图像时,部分图像成为选择状态进行高亮显示。例如,通过点击部分图像,与其他的部分图像相区别地显示该部分图像,即进行高亮显示。关于部分图像的高亮显示,例如可以通过明亮颜色的框线来围住部分图像。另外,即使在全体图像中也高亮显示与该部分图像对应的对象物的影像t_jg。在全体图像的高亮显示中,也可以通过明亮的框线来围住对象物的影像。使框线的形状为与用于切出部分图像的矩形相同即可。或者,也可以通过改变绘制模型图案的颜色来进行高亮显示。并且,在放大了全体图像,仅显示全体图像的一部分时,能够自动地滚动全体图像,以便操作者能够确认高亮显示的对象物的影像。
*将各部分图像与第一标签l1_jg(j=1~ni、g=1~nt_j)对应起来。
*在各部分图像的左上配置了第标签的修正按钮。第一标签的修正按钮也可以配置在部分图像正下方等图像外。
*在第一标签的修正按钮上显示第一标签(“ok”或“ng”)。
*关于第一标签的修正按钮的背景颜色,在“ok”时为绿色,在“ng”时为红色。
*在点击了第一标签的修正按钮时,第一标签l1_jg在“ok”与“ng”之间切换。与第一标签l1_jg的变更相符地画面也更新。
图11表示在图10的状态下点击了第一标签的修正按钮后的显示画面。第二框体的左上的部分图像以及第一框体的与该部分图像对应的对象物的特征点从绿色变更为红色。另外,与第二框体的左上的部分图像对应显示的第一标签的修正按钮从“ok”变更为“ng”。
图12表示检测结果一览画面的另一显示例子。
如图12所示的那样,作为其他的显示例子,能够增大第一框体,并减小第二框体。在该例子中,第一框体的倍率为50%,第二框体的倍率为25%。在成为这样的结构时,能够在第二框体中大致确认各个对象物的全体图像,并在希望更加细致地确认时,通过第一框体进行确认。
图13表示检测结果一览画面的另一显示例子。
如图13所示的那样,作为另一显示例子,能够减小第一框体的倍率,并增大第二框体的倍率。在该例子中,第一框体的倍率为25%,第二框体的倍率为50%。在成为这样的结构时,在第二框体中能够通过放大显示对象物的影像来细致地确认,在第一框体中能够确认在整个图像中该对象物位于哪里。
图14表示检测结果一览画面的另一显示例子。
在图14的例子中,在检测结果一览画面的下部追加了向前的图像按钮,向后的图像按钮、图像索引的文本框。
在按压向前的图像按钮时,显示输入图像i_j的前一个输入图像i_j-1及其检测结果t_j-1g(g=1~nt_j-1)。
在按压向后的图像按钮时,显示输入图像i_j的后一个输入图像i_j+1及其检测结果t_j+1g(g=1~nt_j+1)。
当在图像索引的文本框中输入了整数值x时,显示输入图像i_x及其检测结果t_xg(g=1~nt_x)。
由此,能够不返回输入图像一览画面地在检测结果一览画面中显示其他的输入图像和其检测结果。
图15表示检测结果一览画面的另一显示例子。
第一框体和第二框体的配置不仅能够配置为左右排列,而且还能够配置为上下排列。另外,还能够如图15所示那样配置。在进行了这样的配置时,能够将更多对象物的影像作为部分图像来排列显示。
在步骤s105,将检测到的对象物的影像t_jg(j=1~ni,g=1~nt_j)和第一标签l1_jg的多个数据集作为学习数据,通过学习单元22进行机器学习或统计处理。对于学习单元22的处理,还包含第二实施方式的情况,将在以下进行叙述。
作为第一实施方式的图像处理装置的变形例考虑以下。
*能够保持多个模型图案,并对各模型图案赋予名称。在标签中使用匹配的模型图案的名称。在修正标签时通过下拉框选择标签。
*不是通过多个特征点来定义模型图案,而是通过模板图像这样的形式来进行定义。此时,使用归一化相关这样的方法来检测对象物。因为在将模板图像作为模型图案使用时无法进行特征点的绘制,所以需要在对象物的影像的周围绘制矩形等来表现检测结果。
*不通过按钮进行标签的修正,而通过复选框或文本框来进行。在使用复选框时,仅能指定2值。在使用文本框时,能够输入任意的字符串。
*不是通过下拉而是通过滑块来切换倍率。
*操作者不决定倍率,根据画面尺寸和图像尺寸自动决定。
*不是在图像上绘制模型图案的特征点,而绘制包围模型图案的矩形或模型图案的中心位置。还可以组合它们来进行绘制。包围模型图案的矩形或中心位置能够由用户手动来定义,也可以在制作模型图案时自动设定。
在输入图像一览画面中显示了很多图像时,不是通过滚动条进行滚动,而是通过切换页面来切换显示的图像。例如,在具有100张图像时,在每一页中显示9张,划分为12页来进行显示。在检测结果一览画面的第二框体中也可以使用相同的方法。
*可以使切取检测结果一览画面的部分图像的方法如下那样。
1.预先定义包围模型图案的矩形。该矩形在示教模型图案时,可以自动的定义,也可以由操作者手动的定义。矩形能够通过矩形的左端顶点u1的位置姿态和宽度u_w、高度u_h来定义。顶点u1的从模型图案坐标系观察时的位置姿态通过齐次变换矩阵r_u1来定义。
2.基于对象物的影像的位置r_tjg来计算顶点u1的从图像坐标系观察时的位置姿态r_u1′。
3.使用顶点u1在图像坐标系中的位置姿态r_u1′和宽度u_w、高度u_h来切出部分图像。
在该情况下,部分图像上的对象物的影像以相同的姿态进行显示。当然,切出部分图像的形状也可以不是矩形。
图16表示在以相同姿态显示部分图像上的对象物的影像时的检测结果一览画面的显示例子。
*也可以同时显示不同尺寸的对象物的影像。此时,可以使对象物的影像大小一致来显示,也可以按照原有尺寸比来显示。
图17表示在以原有的尺寸比同时显示不同尺寸的对象物的影像时的检测结果一览画面的显示例子。
图18是表示第二实施方式的图像处理装置的处理流程的流程图。
第二实施方式的图像处理装置具有与第一实施方式的图像处理装置相同的硬件结构,部分处理与第一实施方式不同。第二实施方式的说明中,首先以学习单元22进行统计处理的情况为例进行说明。
另外,图19表示在第二实施方式中使用的检测结果一览画面的显示例子。
在图19的画面中,第一框体和第二框体上下排列配置。另外,在第一框体的右侧配置了snap按钮、find按钮、finish按钮。
在步骤s201中,进行与第一实施方式的步骤s101相同的处理。
在步骤s202中,在视觉传感器11的视野内配置对象物并按压snap按钮,拍摄一张输入图像。优选在输入图像i_j中拍摄到的对象物的影像包含在检测中成为问题的变动。作为确认了输入图像i_j的结果,在判断为作为学习数据不理想时,可以再次按压snap按钮来重新拍摄输入图像i_j。将拍摄到的图像作为全体图像在第一框体中显示。因为此时未检测到对象物,所以在全体图像的对象物的影像上未绘制模型图案,也不显示部分图像。此时可以只显示第一框体,而不显示第二框体。
在步骤s203中,当按压了find按钮时从输入图像i_j进行对象物的检测。检测处理可以与第一实施方式的步骤s103同样地进行。但是,在这里只从一个输入图像i_j进行检测。
在步骤s204中,通过检测结果一览画面来一览显示从输入图像i_j检测到的对象物的影像t_jg(g=1~nt_j)。
图20表示在步骤s204显示的检测结果一览画面的显示例子。
全体图像和部分图像的显示可以与第一实施方式同样地进行。隐藏第一框体右侧的snap按钮、find按钮,并追加了add按钮、discard按钮。操作者确认在检测结果一览画面中显示的全体图像和部分图像,并与第一实施方式同样地确认在检测结果中是否有问题。
并且,在步骤s204中,能够如第一实施方式的检测结果一览画面那样修正第一标签。
图21表示修正了第一标签时的检测结果一览画面的显示例子。
在这里,确认赋予了“ok”的对象物的影像,当判定为不是对象物时,将第一标签变更为“ng”,并存储该修正后的标签。并且,确认赋予了“ng”的对象物的影像,在判断为应检测为对象物时,将第一标签变更为“ok”,并存储该修正后的标签。
在步骤s205中,决定是否向学习数据追加对象物的影像t_jg(g=1~nt_j),在决定追加时,按压add按钮,并将输入图像i_j和对象物的影像t_jg(g=1~nt_j)、第一标签l1_jg(g=1~nt_j)对应起来追加到学习数据中。在不追加时,按压discard按钮,丢弃输入图像i_j和对象物的影像t_jg以及第一标签l1_jg。不论按压add按钮和discard按钮中的哪个,都再次从步骤s202开始处理。
如果追加了足够的学习数据则按压finish按钮,并向步骤s206前进。
在此,在向s206前进之前,可以如第一实施方式的步骤s104那样追加以下的步骤:使用输入图像一览画面和检测结果一览画面来确认并修正在学习数据中追加的全部的输入图像i_j(j=1~ni)所对应的对象物的影像t_jg(j=1~ni,g=1~nt_j)的第一标签l1_jg(j=1~ni,g=1~nt_j)。
在步骤s206中,基于收集到的学习数据与第一实施方式的步骤s105一样地,将对象物的影像t_jg(j=1~ni,g=1~nt_j)与第一标签l1_jg(j=1~ni,g=1~nt_j)组成的多个数据集作为学习数据,通过学习单元22进行统计处理。
以下,对第一以及第二实施方式中的学习单元22的统计处理进行说明。
学习单元22进行学习,以便能够正确判定对象物的影像t_jg(j=1~ni,g=1~nt_j)是否是与模型图案相对应的对象物。换而言之,在输入了认为包含对象物的影像的部分图像时,进行学习以便能够正确地进行是否包含对象物的影像的判定。到此为止,通过对象物检测单元21从输入图像中检测出对象物,得到某种程度的检测精度,但是作为学习单元22的学习结果,进一步提高检测精度。在这里,通过对象物检测单元21进行检测,并在学习数据存储单元32中存储被认为包含适合作为学习对象的第一标签为“ok”的对象物的影像的部分图像。如果学习单元22的运算处理能力足够高,也可以通过不是输入部分图像,而是将输入图像输入来检测对象物的方式进行学习。学习单元22针对在学习数据存储单元32中存储的多个部分图像进行统计处理,改善模型图案。
本申请人在日本专利申请2015-218357中公开了针对基于模型图案检测到的对象物的多个影像进行统计处理,改善模型图案的技术,例如,学习单元22通过使用了在日本专利申请2015-218357中公开的统计处理的技术来实现。但是,学习单元22执行的统计处理并不限于此。
以上,对学习单元22执行统计处理时的第一以及第二实施方式进行了说明。以下,对学习单元22进行机器学习(有教师学习)的情况进行说明。
学习单元22进行机器学习,以便改善对象物检测单元21检测为对象物的准确度。此时的正确检测是指将对象物正确检测为对象物,不将非对象物检测为对象物,不存在未将对象物检测为对象物的检测遗漏,也不存在将非对象物检测为对象物的误检测。为了进行这样的学习,优选作为学习数据,由图像处理装置10在输入图像中判定为对象物的影像并且由使用者确认判定正确的部分图像(“ok”“ok”)、由图像处理装置10在输入图像中判定为对象物的影像但是由使用者确认为判定错误的部分图像(“ok”“ng”)、由图像处理装置10在输入图像中判定为不是对象物的影像但是由使用者确认为判定错误的部分图像(“ng”“ok”)、由图像处理装置10在输入图像中判定为不是对象物的影像并且由使用者确认判定正确的部分图像(“ng”“ng”)为相似的比例,从而可高效地进行学习。因此,在上述的学习单元22进行统计处理的第一以及第二实施方式中,将具有第一标签从“ng”变更为“ok”的履历以及从“ok”变更为“ng”的履历的部分图像与履历对应起来存储在学习数据存储单元32中。它们成为部分图像(“ng”“ok”)以及部分图像(“ok”“ng”)。并且,操作者从判定为对象物的影像并维持了判定的部分图像(“ok”“ok”)以及在输入图像中未判定为对象物的影像并维持了判定的部分图像(“ng”“ng”)中,选择适当的部分图像来作为学习数据,作为部分图像(“ok”“ok”)以及部分图像(“ng”“ng”)存储在学习数据存储单元32中。但是,并不限于此,也可以随机地收集部分图像作为学习数据来使用。另外,也可以将“ng”“ng”的部分图像作为学习数据来使用。
学习单元22具有如下功能:通过解析来从输入的数据集合中抽出其中有用的规则和知识表现、判断基准等,输出该判断结果,并且进行知识的学习(机器学习)。机器学习的方法有各种各样,但是大体上例如分为“有教师学习”、“无教师学习”、“强化学习”,在这里使用“有教师学习”。并且,具有在实现这些方法的基础上,学习特征量自身的抽出的被称为“深度学习(deeplearning)”的方法。此外,这些机器学习(机器学习装置20)也可以使用通用的计算机或处理机,在采用gpgpu(general-purposecomputingongraphicsprocessingunits通用图形处理器)或大规模pc集群等时,能够更高速地进行处理。
“有教师学习”是指通过大量地向学习单元22赋予某个输入和结果(标签)的数据组合,来学习这些数据组所具有的特征,并归纳性地获得根据输入推定结果的模型,即为其关系性。当在实施方式中应用该有教师学习时,例如能够使用神经网络等算法来实现学习单元22。
作为有教师学习中的价值函数的近似算法,能够使用神经网络。图22示意地表示神经元的模型,图23示意地表示组合图22所示的神经元而构成的三层的神经网络。即,神经网络例如由模拟图22所示的神经元模型的运算装置以及存储器等构成。
如图22所示,神经元输出与多个输入x(在图22中作为一个例子,为输入x1~输入x3)相对的输出(结果)y。对各输入x(x1、x2、x3)乘以与该输入x相对应的权重w(w1、w2、w3)。由此,神经元输出通过下式表现的输出y。此外,输入x、输出y以及权重w全是矢量。另外,在下式中,θ为偏置,fk为激活函数。
参照图23来说明组合图22所示的神经元而构成的三层神经网络。如图23所示的那样,从神经网络的左侧输入多个输入x(在此作为一个例子,为输入x1~输入x3),从右侧输出结果y(在此作为一个例子,为结果y1~结果y3)。具体来说,将输入x1、x2、x3乘以对应的权重来对三个神经元n11~n13中的各个神经元进行输入。将与这些输入相乘的权重统一记载为w1。
神经元n11~n13分别输出z11~z13。在图23中,将这些z11~z13统一记载为特征矢量z1,能够视为抽出了输入矢量的特征量而得到的矢量。该特征矢量z1是权重w1和权重w2之间的特征矢量。将z11~z13乘以对应的权重来对两个神经元n21、n22中的各个神经元进行输入。将与这些特征矢量相乘的权重统一记载为w2。
神经元n21、n22分别输出z21、z22。在图23中,将这些z21、z22统一记载为特征矢量z2。该特征矢量z2是权重w2和权重w3之间的特征矢量。将z21、z22乘以对应的权重来对三个神经元n31~n33中的各个神经元进行输入。将与这些特征矢量相乘的权重统一记载为w3。
最后,神经元n31~n33分别输出结果y1~结果y3。在神经网络的动作中,具有学习模式和价值预测模式。例如,在学习模式中使用学习数据组来学习权重w,使用该参数在预测模式中进行机器人的行为判断。此外,虽然为了方便而写为预测,但是自不用说还能够进行检测、分类、推论等多种任务。
在这里,可以即时学习在预测模式下使机器人实际动作而得到的数据,并将其反映在下次的行为中(在线学习),也可以使用预先收集到的数据进行汇总的学习,以后一直通过该参数进行检测模式(批量学习)。或者,在这中间,在每次积累了一定程度的数据时插入学习模式。
另外,权重w1~w3能够通过误差逆传播法(反向传播)来进行学习。此外,误差的信息从右侧进入向左侧流动。误差逆传播法是对于各神经元调整(学习)各自的权重,以使得输入了输入x时的输出y和真实的输出y(教师)之间的差分变小的方法。
这样的神经网络可以在三层以上进一步增加层(称为深度学习)。另外,也能够只从教师数据自动地获得阶段性地进行输入的特征抽出,并递归导出结果的运算装置。
图24表示第一以及第二实施方式的学习单元22的概要结构。
学习单元22具有状态量观测部61、神经网络62、神经网络(nn)更新控制部63。如上所述,学习单元22例如通过gpgpu(general-purposecomputingongraphicsprocessingunits通用图形计算处理单元)来实现。
状态量观测部61从学习数据存储单元32接收由部分图像及其包含的对象物的影像的第一标签组成的数据集。学习数据存储单元32存储非常多的数据集,并依次发送到状态量观测部61。
神经网络62是进行深度学习的神经网络,针对来自状态量观测部61的部分图像计算判定结果(“ok”“ng”)。在神经网络62中能够针对各神经元通过nn更新控制部63调整(学习)权重。
nn更新控制部63进行以下的更新控制:将神经网络62根据来自状态量观测部61的部分图像计算出的判定结果(“ok”“ng”)与该部分图像的第一标签(教师数据)进行比较,针对神经网络62的各神经元变更权重,以使得比较结果一致的概率增高。
此外,通过学习单元22进行处理的内容不限于上述内容。一般在有教师的机器学习中,学习对输入以及与其对应的输出(标签)进行映射的函数。在第一以及第二实施方式中,公开了将输入图像、检测到的对象物的影像作为输入,从而快速修正成为其输出的标签的方法。根据该输入与输出学习映射函数的方法可以为任意方法。
以上,对实施方式进行了说明,实施方式的检测结果一览画面具有以下的特征。
*由第一(上)框体和第二(下)框体这两个框体构成。
*在第二框体中显示了将各个检测到的对象物的影像切出的部分图像。
*在第一框体中显示全体图像中的对象物的影像。但是,并不限定框体的排列方法,可以是上下、左右、或之外的排列。
*能够将各个框体的显示倍率独立地进行变更。
*当在第二框体中选择了对象物的影像时,在上方的框体中高亮显示对应的对象物的影像。
*并且,在第一框体中只显示了图像的一部分时,滚动整体的图像,以便显示选择的对象物的影像。
*当在第一框体中选择了对象物的影像时,在第二框体中选择对应的对象物的影像。
*能够在第二框体中修正检测结果和好坏判定结果的标签(ok/ng等)。
在上述的显示画面中具有以下的优点。
*在第二框体中,能够不受相同图像中的其他对象物的影像打扰地,集中针对对象的对象物的影像进行确认。
*在变更检测到的对象物的标签时,容易理解按钮、文本框等是属于哪个对象物的影像。
*能够简单地确认检测到的对象物的各个影像是在图像中的哪个位置。
*在第一框体中在全体的图像中放大显示对象物的影像,并在第二框体中缩小显示各个对象物的影像,由此能够在第一框体中细致地确认对象物的影像,并在第二影像中大致确认各个对象物全体
*与之相反,在第二框体中放大显示各个对象物的影像,并在第一框体中缩小显示全体的图像,由此能够在第二框体中细致地确认对象物的影像,并在第一框体中显示在整个图像中该对象物位于哪个位置。
并且,具有操作者希望确认多个图像的检测结果或判定结果的情况。例如,为如下的情况。
*希望确认在生产中拍摄到的图像中是否具有不正确的检测。
*在变更了检测参数后,针对多个图像进行检测,希望确认是否针对全部的图像进行了正确的检测。
*为了机器学习用于在好坏判定中进行辨别的参数,在将既有的好坏判定结果作为学习数据使用时,确认既有的好坏判定结果是否正确,如果错误则修正判定结果(标签)。
在如此确认多个图像的检测结果时,以下的方法是有效的:将多个图像缩小显示后的图像来在输入图像一览画面中显示,在该图像上绘制检测结果,在更细致地确认时,选择图像将其移动到确认上面说明的各个图像的检测结果的输入图像一览画面中。
并且,权利要求所记载的结构和其效果如下所述。
一种图像处理装置,其具有:对象物检测单元,其基于对象物的模型图案,从拍摄了对象物的输入图像检测对象物的一个乃至多个影像;检测结果显示单元,其针对检测出的各个影像,以图形方式重叠显示检测结果,检测结果显示单元具备:第一框体,其显示整个输入图像;第二框体,其一览显示包含从该输入图像检测出的一个乃至多个影像中的各个影像的部分图像,在第一框体中显示的输入图像中,针对检测出的全部的影像重叠显示检测结果,在第二框体中显示的部分图像中,重叠显示与各个部分图像对应的影像的检测结果。
通过该结构,能够在第一框体中在全体图像中确认以下的点。
*在哪里如何拍摄出对象物的影像。
*拍摄出几个对象物的影像。
*是否没有从相同位置检测出多个对象物的影像。
在第二框体中能够不受相同图像中的其他对象物的影像的干扰,集中针对确认对象的对象物的影像来进行确认。
通过在相同窗口内同时显示第一框体和第二框体,能够在同时发挥上述优点的同时确认对象物的影像。由此,能够快速确认图像内拍摄到的多个对象物的影像。
如国际公开第2001/041068号那样,还考虑了在第一框体中显示全体图像,在第二框体中通过表的形式显示检测结果的方法。但是,在该方法中难以了解表示检测结果的表的行与图像上的对象物的影像的关联。另外,与通过表形式使用文字来确认检测结果相比,观察部分图像的方法能够直观地确认对象物的影像。
检测结果显示单元在第二框体中显示的部分图像上,进一步重叠显示与各个部分图像所对应的影像关联起来存储的第一标签信息,并且能够基于操作者的操作来变更第一标签信息。
通过在第二框体的部分图像上设置用于操作标签的单元,容易了解对象物的影像与标签的操作单元之间的对应关系。另外,无需选择对象物这样的操作,就可以修正标签。例如,在国际公开第2001/041068号中,必须在选择对象物后修正标签。另外,还考虑了通过表形式显示检测结果,当选择了表的行时,在全体图像上高亮显示与该检测结果相对应的对象物的影像,在表的行中设置用于修正标签的单元这样的方式。但是,在该方法中,为了确认图像需要选择表的行。除此之外,虽然还考虑了在第一框体的全体图像上设置操作标签的单元,但是在该方法中对象物的影像重叠、或相邻接时,难以了解操作单元与对象物的影像的对应关系。
检测结果显示单元在第一框体和第二框体中通过各个设定倍率来显示图像。
首先,能够构成为在第一框体中在全体的图像中放大显示对象物的影像,并在第二框体中缩小显示各个对象物的影像。此时,在第一框体中通过增大显示对象物的影像能够细致地确认。另外,在第二框体中能够大致确认各个对象物的整个影像。其次,还能够构成为在第二框体中放大显示各个对象物的影像,并在第一框体中缩小显示全体的图像。此时,在第二框体中通过增大显示对象物的影像能够细致地确认。另外,在第一框体中能够确认在整个图像中该对象物位于哪里。通过这样针对相同对象物以不同的倍率同时确认对象物的影像,能够快速进行确认。
检测结果显示单元具备从第二框体中显示的多个部分图像中选择一个部分图像的部分图像选择单元,在第一框体中显示的输入图像中,高亮显示针对对象物的影像的检测结果,该对象物的影像相当于通过部分图像选择单元选择出的部分图像。
通过该结构,能够容易确认在第一框体的全体图像中显示的对象物的影像与在第二框体中作为部分图像显示的对象物的影像的对应关系。
检测结果显示单元在第一框体中显示的所述输入图像上,重叠显示与从输入图像检测出的一个乃至多个影像中的各个影像对应的第一标签信息。
通过该结构,在第一框体的全体图像中,也能够确认标签的信息。对于仅通过部分图像难以确认对象物的影像的情况有帮助。例如,在对象物的影像看到某个物品的一部分时,具有难以确认对象物的影像在整个物品中的位置关系的情况。在这种情况下,通过在第一框体的全体图像中也显示标签信息,确认变得容易。
图像处理装置具备:检测结果存储单元,其将多个输入图像与从该多个输入图像中的各个输入图像检测出的对象物的一个乃至多个影像的检测结果关联起来进行存储;输入图像选择单元,其用于从多个输入图像中选择一个输入图像,检测结果显示单元显示通过输入图像选择单元选择出的一个输入图像、与该一个输入图像相关联地存储在检测结果存储单元中的检测结果。
通过该结构,能够不往复输入图像显示单元和检测结果显示单元,而在检测结果显示单元上进行多个图像的确认。例如,通过在检测结果显示单元上准备向后图像按钮来作为输入图像选择单元,能够在检测结果显示单元中依次改变图像。
图像处理装置具备输入图像显示单元,其在重叠了从各个输入图像检测出的对象物的一个乃至多个影像以及检测结果后,一览显示在检测结果存储单元中存储的多个输入图像,检测结果显示单元显示通过输入图像选择单元选择出的一个输入图像,能够基于操作者的操作来切换输入图像显示单元和检测结果显示单元。
通过输入图像显示单元,一览显示多个图像的检测结果,由此猜测可能有问题的图像,在希望更细致地确认时,能够通过检测结果显示单元只确认该图像的检测结果。由此,能够从多个图像中直观地移动到确认特定图像的检测结果的画面中。
检测结果存储单元将第二标签信息与多个输入图像中的各个输入图像相关联地存储,输入图像显示单元进一步重叠显示与多个输入图像中的各个输入图像相关联地存储的第二标签信息,并且使操作者能够变更第二标签信息,通过变更一个输入图像的第二标签信息,一并变更与该一个输入图像相关联地存储的多个对象物的各个影像所对应的第一标签信息。
通过该结构,在输入图像显示单元中仅通过确认各图像便能够确认检测结果的情况下,能够不移动到检测结果显示画面而修正检测结果的标签。例如,如果在输入图像显示单元中将对象物的影像足够大地显示,则不需要在检测结果显示画面中进行确认。但是,当在图像内显示了多个检测结果的情况下,仅在使全部的检测结果为相同的标签时能够使用该方法。另外,在图像内只显示一个检测结果的情况下,能够只通过输入图像显示单元进行确认的可能性高。在这种情况下,因为标签也只为一个,所以也不需要为了修正各个标签而移动到输入图像显示单元。通过这样的功能,即使图像内的检测结果为多个和单个中的任意一个,也能够使用相同的方法来应对。
图像处理装置具备:学习数据存储单元,其对检测出的各个影像附加第一标签信息,并相互关联地作为学习数据进行存储;学习单元,其基于学习数据进行机器学习或统计处理。
通过该结构,针对对象物的影像进行检测或好坏判定,附加第一标签信息的精度提高。
通过本发明的图像处理装置的显示,起到以下的效果:针对从输入图像检测出的对象物能够容易地进行检测结果和好坏判定结果的确认。
- 还没有人留言评论。精彩留言会获得点赞!