基于相似度对比的建设工程项目数据管理方法及系统与流程
本发明属于建设工程项目数据管理领域,具体涉及一种基于相似度对比的建设工程项目数据管理方法及系统。
背景技术:
目前,建设行业历史累积的工程项目数据(包括工程项目特征指标数据)数量惊人、种类繁多,而且这些数据的层级较复杂,维度过多,导致业界难以用统一的标准对这些数据进行深度分类及管理。
现有技术中采用的分类及管理方案的实施大多主要依赖人工判断,过于耗时费力,且造成企业管理成本居高不下。这是导致大部分企业对历史工程项目数据疏于管理的主要原因,从而也阻碍了项目数据之间的有效对比、校验及海量历史工程项目数据价值的实现。
技术实现要素:
本发明针对目前存在的工程项目数据的分类管理过于耗时耗力、企业管理成本高等缺陷,提出一种基于相似度对比的建设工程项目数据管理方法,同时相应提出了一种基于相似度对比的建设工程项目数据管理系统的结构方案。
本发明提出的一种基于相似度对比的建设工程项目数据管理方法,主要包括以下步骤a1至a6:
a1、将各项目根据行业标准划分层级类别;
a2、根据各项目的层级类别确定工程项目特征的备选指标,搜集选定的备选指标对应的工程项目特征指标数据,并存储于项目库中;
a3、从项目库中选择目标项目的工程项目特征指标数据,并筛选出与目标项目的层级类别相同的关联项目的工程项目特征指标数据;
a4、对工程项目特征指标数据出现缺失或异常的目标项目或关联项目,相应进行缺失值或异常值处理;
a5、对目标项目和各关联项目的工程项目特征指标数据进行标准化处理;
a6、基于标准化后的工程项目特征指标数据,计算各关联项目与目标项目之间的相似度。
本发明的一优选方案中,步骤a1中的层级类别具体包括行业类型、工程类型、项目类型三个层级类别。但根据不同的行业标准可有不同的层级类别划分方案。
本发明的一优选方案中,步骤a2中工程项目特征的备选指标包括公共指标和各行业特殊属性指标。
本发明的一优选方案中,步骤a4包括a41至a42:
a41、对目标项目和关联项目的工程项目特征指标数据的异常值和缺失值进行识别;
a42、对工程项目特征指标数据出现缺失或异常的目标项目或关联项目的异常值或缺失值相应进行填补修正。
本发明的一优选方案中,步骤a5包括:将目标项目和各关联项目的工程项目特征指标数据以最小值至最大值相应映射到[0,1]区间进行标准化。即最小值映射为0,最大值映射为1,其他值处于0至1之间。
本发明的一优选方案中,步骤a6包括:基于欧氏距离计算公式并结合预置的各工程项目特征指标数据的权重,计算各关联项目与目标项目之间的相似度。
本发明的一优选方案中,步骤a6之后还可包括步骤:a7、根据相似度选择相应的关联项目与目标项目进行对比分析。
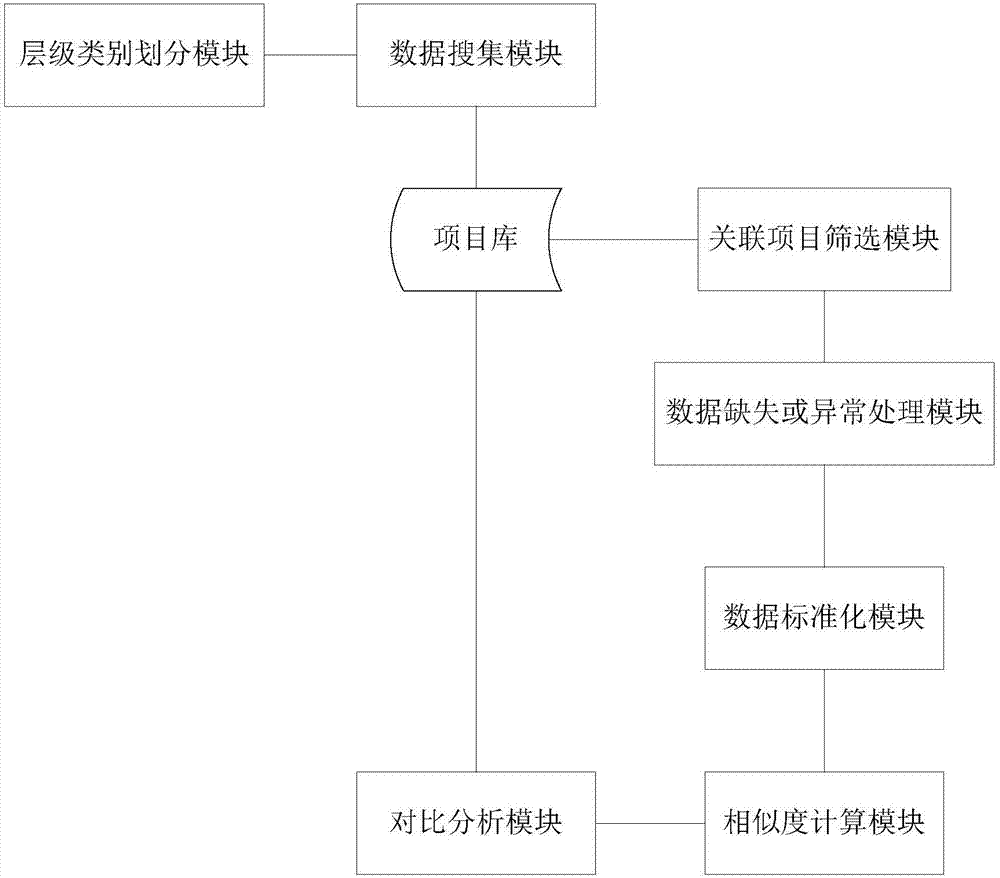
本发明相应提出的一种基于相似度对比的建设工程项目数据管理系统的结构方案,主要包括层级类别划分模块、数据搜集模块、关联项目筛选模块、数据缺失或异常处理模块、数据标准化模块、相似度计算模块;
层级类别划分模块,将各项目根据行业标准划分层级类别;
数据搜集模块,根据各项目的层级类别确定工程项目特征的备选指标,搜集选定的备选指标对应的工程项目特征指标数据,并存储于项目库中;
关联项目筛选模块,从项目库中选择目标项目的工程项目特征指标数据,并筛选出与目标项目的层级类别相同的关联项目的工程项目特征指标数据;
数据缺失或异常处理模块,对工程项目特征指标数据出现缺失或异常的目标项目或关联项目,相应进行缺失值或异常值处理;
数据标准化模块,对目标项目和各关联项目的工程项目特征指标数据进行标准化处理;
相似度计算模块,基于标准化后的工程项目特征指标数据,计算各关联项目与目标项目之间的相似度。
本发明的一优选方案中,除了以上模块之后还包括:对比分析模块,根据相似度选择相应的关联项目与目标项目进行对比分析。
本发明具备以下有益效果:基于统一标准划分的层级类别,对目标项目与关联项目的工程项目特征指标数据进行相似度计算,实现对不同项目之间的相似性度量,相对于人工判断具有省时省力、成本低等优点。本发明可方便地实现工程项目的分类及管理,对于企业积累的海量历史工程项目数据价值的实现提供了重要技术基础。
附图说明
图1是实施例一涉及的一种基于相似度对比的建设工程项目数据管理方法流程示意图。
图2是实施例二涉及的一种基于相似度对比的建设工程项目数据管理系统结构框图。
具体实施方式
为了便于本领域技术人员理解,下面将结合附图以及实施例对本发明进行进一步描述。
实施例一
请参阅图1,实施例一涉及的一种基于相似度对比的建设工程项目数据管理方法,主要包括以下步骤s100至s600:
s100、将各项目根据行业标准划分层级类别。
作为参考,根据行业标准,步骤s100中的层级类别可包括行业类型、工程类型、项目类型三个层级类别。例如:项目1的行业类型为建筑工程,工程类型为居住建筑工程,项目类型为宿舍项目。当然,根据不同的行业标准可有不同的层级类别划分方案。
s200、根据各项目的层级类别确定工程项目特征的备选指标,搜集选定的备选指标对应的工程项目特征指标数据,并存储于项目库中。
例如:根据步骤s200执行后搜集到表1所示工程项目特征指标数据(或简称为指标数据):
表1.原始的工程项目特征指标数据
如表1所示,步骤s200中工程项目特征的备选指标可包括公共指标和各行业特殊属性指标。公共指标包括总造价、单方造价、各专业单方造价(土建、装饰、电气、市政工程、消防、智能化)等指标;行业特殊属性指标包括建筑面积、层数、总高度等指标。当然,备选指标不限于以上分类。
s300、从项目库中选择目标项目的工程项目特征指标数据,并筛选出与目标项目的层级类别相同的关联项目的工程项目特征指标数据。
例如:根据步骤s300假设选择项目1为目标项目,并且筛选到项目2至项目7为关联项目。
s400、对工程项目特征指标数据出现缺失或异常的目标项目或关联项目,相应进行缺失值或异常值处理。
步骤s400的详细方案具体可参考以下步骤s410至s420:
s410、对目标项目和关联项目的工程项目特征指标数据的异常值和缺失值进行识别。
本实施例中,异常值是指一组数据值(测定值)与大部分同类数据的差距较大的情况,可作为缺失值进行处理。缺失值是指原始的工程项目特征指标数据出现缺失的情况,因此需要通过某种合理的方式对其进行填补或修正。例如:一、各维度指标数据出现小于零的数可视为异常值;二、各指标数据大于该指标的上限qmax或小于该指标的下限qmin可视为异常值。
关于qmax和qmin的计算如下所示:
假定有n项目,第k个指标数据由小到大排序后组成向量(x1,x2,x3…,xn),第k个指标数据中的上限和下限分别为qmax和qmin。向量(x1,x2,x3…,xn)的上四分位数为q1,下四分位数为q3。
q1=x(n+1)×0.25(1)
q3=x(n+1)×0.75(2)
qmin=q1-1.5(q3-q1)(3)
qmax=q3+1.5(q3-q1)(4)
关于q1和q3的计算会出现另外一种情况,当(n+1)×0.25不为整数时,假设(n+1)×0.25的整数部分为a,小数部分为b,q1=(1-b)xa+bxa+1,q3同理可得。
s420、对工程项目特征指标数据出现缺失或异常的目标项目或关联项目和异常值或缺失值相应进行填补修正。
本实施例只对总造价、单方造价、各专业特殊属性指标进行异常值识别,异常值会当成缺失值处理。下面将对缺失值处理做详细说明。根据步骤s200涉及的所有指标数据,缺失值处理主要有两种方式:第一种,对项目各专业单方造价缺失的指标数据进行零填充,这是因为项目本身并不一定会包含所有专业类型;第二种,对于总造价、单方造价、各专业特殊属性指标,当后续计算目标项目与其关联项目之间的相似度时,目标项目在这些指标中存在缺失值的那些指标将不参与相似度计算,其他关联项目某指标存在缺失值,而目标项目不存在缺失值,则该项目不参与与目标项目的相似度计算。
以表1为例,根据步骤s410首先分别对各项目的总造价、单方造价、建筑面积、层数、总高度进行异常值识别,并识别到以下异常值:
总造价:17648.74311
单方造价:4139.67、2705.14
建筑面积:65241.6
根据步骤s420将以上异常值变成缺失值,再对土建、装饰、电气、市政工程、消费、智能化进行零填补,得到如下表2:
表2.经过异常和缺失处理后的工程项目特征指标数据
根据步骤s420,目标项目1存在层数指标数据缺失,因此层数指标将不参与相似度计算,其他指标都将参与相似度计算。对于项目5、项目6、项目7分别在单方造价、总造价和建筑面积存在缺失值,因此项目5、项目6、项目7都不参与项目1的相似度计算,最后确定参与相似度计算的项目及其工程项目特征指标数据如表3所示:
表3.参与相似度计算的工程项目特征指标数据
s500、对目标项目和各关联项目的工程项目特征指标数据进行标准化处理。
作为参考,步骤s500具体包括:将目标项目和各关联项目的工程项目特征指标数据以最小值至最大值相应映射到[0,1]区间进行标准化。即最小值映射为0,最大值映射为1,其他值处于0至1之间。
假定有n个项目,第k个指标数据组成向量xk(x1,x2,x3…,xn),对该向量进行标准化处理后得到x'k(x1',x'2,x'3…x'n)。
……
上述公式中xmin是xk的最小值,xmax是xk的最大值。
经过步骤s500处理后得到以下表4中标准化后的工程项目特征指标数据:
表4.标准化后的工程项目特征指标数据
s600、基于标准化后的工程项目特征指标数据,计算各关联项目与目标项目之间的相似度。
作为参考,步骤s600的一方案包括:基于欧氏距离计算公式并结合预置的各工程项目特征指标数据的权重,计算各关联项目与目标项目之间的相似度,具体如下:
sim(x,y)=1-dis(x,y)(8)
其中,sim(x,y)为项目x和项目y的相似度,dis(x,y)为项目x和项目y的距离,距离越大,相似度越小;n为项目x和项目y进行相似度计算的指标个数;a1至an为预置的各指标对应的工程项目特征指标数据的权重,且满足a1+a2+…an=1;x1至xn为项目x中各指标对应的标准化后的工程项目特征指标数据,y1至yn为项目y中各指标对应的标准化后的工程项目特征指标数据。
本实施例中,a1至an可采用专业设定,例如:将总造价的权重定为5%、单方造价定为5%,各专业总占比60%,其他属性一共占比30%。各专业的权重50%*各专业单方造价与所有专业单方造价之和的占比,其他属性各占比30%/属性指标的总个数。
基于步骤s600进行以下计算:
总造价a1=5%
单方造价a2=5%
建筑面积
总高度
土建
……
智能化
权重向量a=(0.05,0.05,0.15,0.15,0.236,0.221,0.109,0.014,0.013,0.006)
综合以上可分析得到,以项目1为目标项目时,计算其与其他三个项目的相似度得出,与项目1最相似度的项目是项目4,其次项目2,最后是项目3。
以上为本实施例的主要技术内容,参阅图1,进一步应用中本实施例还可包括以下步骤:
s700、根据相似度选择相应的关联项目与目标项目进行对比分析。
实施例二
请参阅图2,实施例二介绍的是与实施例一相对应的一种基于相似度对比的建设工程项目数据管理系统,其主要包括层级类别划分模块、数据搜集模块、关联项目筛选模块、数据缺失或异常处理模块、数据标准化模块、相似度计算模块;
层级类别划分模块,将各项目根据行业标准划分层级类别;
数据搜集模块,根据各项目的层级类别确定工程项目特征的备选指标,搜集选定的备选指标对应的工程项目特征指标数据,并存储于项目库中;
关联项目筛选模块,从项目库中选择目标项目的工程项目特征指标数据,并筛选出与目标项目的层级类别相同的关联项目的工程项目特征指标数据;
数据缺失或异常处理模块,对工程项目特征指标数据出现缺失或异常的目标项目或关联项目,相应进行缺失值或异常值处理;
数据标准化模块,对目标项目和各关联项目的工程项目特征指标数据进行标准化处理;
相似度计算模块,基于标准化后的工程项目特征指标数据,计算各关联项目与目标项目之间的相似度。
请继续参阅图2,进一步优选方案中,还包括对比分析模块,其用于根据相似度选择相应的关联项目与目标项目进行对比分析。
以上实施例二的技术原理和有益效果与实施例一相对应,这里不再赘述。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!