一种基于GPU的高精度图形电磁散射计算方法与流程
本发明涉及电磁散射领域,尤其是一种图形电磁散射计算方法方法。
背景技术:
复杂目标的电磁散射特性是武器平台设计必须考察的重要指标之一,通常使用图形算法来计算电大尺寸的复杂目标雷达散射截面积(radarcrosssection,rcs),如飞机坦克等模型,其特殊的硬件消隐能力可以大大提高计算效率。当使用图形算法计算大尺寸模型时,为了适应屏幕,往往模型会被缩放,因而损失精度,并且由于输出精度的问题,图形算法的计算结果总是存在少量偏差,同时一个模型的360度rcs计算总是需要消耗大量时间,效率还有待提高,如果能解决精度的问题,并使模型显示不再受到屏幕限制,同时提高效率,则对复杂目标的电磁散射计算将有重大意义。
技术实现要素:
为了克服现有技术的不足,本发明提出了一种复杂目标的高精度快速电磁散射计算方法,该方法使图形算法的计算精度大大提升,同时提高了图形算法的计算效率,实现了高精度快速的复杂目标电磁散射计算。
本发明解决其技术问题所采用的技术方案的步骤如下:
步骤1:针对飞机导弹类目标进行3d建模,模型信息包括目标的位置信息、目标的材料以及目标材料对应的相对介电常数和相对磁导率,通过3d建模软件调整模型角度和模型比例,使一个像素最多包含一个曲面结构,使用opengl中的glew库函数控制图形处理器(graphicsprocessingunit,gpu),搭建基于着色器处理图形的cpu-gpu异构计算环境,同时在内存与显存中存储基于物理光学法的图形算法,通过程序编程控制中央处理器(centralprocessingunit,cpu)与gpu,当cpu与gpu均处于待命状态时,则完成搭建基于gpu的协同计算框架,此时调用opengl的绘图指令读取3d模型中的模型信息并导入内存;
步骤2:创建无光照的像素细分计算环境
使用opengl库函数中的glbindrenderbuffers指令函数,控制缓存部件gpu中的存储控件帧缓存对象(framebufferobject,fbo),以fbo为显示载体,将屏幕显示控制在显存中,使用glrenderbufferstorage指令函数设定fbo在显存中的内存空间,将fbo的大小提高到当前所使用屏幕分辨率大小的3到4倍,使用顶点着色器将步骤一中的模型信息离散到fbo缓存部件中,同时在顶点着色器中编程控制gpu将当前所使用屏幕上的每个像素按照像素边长的中点进行二等分或四等分,即将原来一个像素的数据二等分后放大了4倍,或将像素边长4等分后放大了16倍,以此实现像素的细分,细分后的像素根据模型位置信息对应步骤一中的模型信息,使用glshadersource函数将步骤一中的模型信息传入顶点着色器,在顶点着色器中计算模型的法矢量后得到新的模型信息,使用gluseprogram函数将新的模型信息传入gpu中的光栅化模块,模型信息经过光栅化即可离散成各个独立的电磁参数,电磁参数按照像素的位置信息一一对应保存至片元着色器中,至此,像素细分计算环境搭建完成;
步骤3:当片元着色器中获取到步骤二中光栅化的以像素为单位的电磁参数时,片元着色器先进行电磁参数的单位换算和格式换算,换算后的电磁参数按照公式(1)计算即可得出rcs散射值,公式(1)如下:
式(1)中σ表示散射场,λ表示波长,∑pixels()表示细分后的像素为单位求和计算,f为幅度函数,k为波数,z′为像素深度,δs为细分后像素的投影面积,ed为绕射场分量,其中γ按照三种不同极化方式对应不同的计算公式,不同极化方式的γ计算公式如下:
其中n′x、n′y、n′z分别为法矢量在坐标轴xyz上的三个坐标分量,εr(2)、εr(1)分别为内层和外层材料的相对介电常数,μr(2)、μr(1)分别为内层和外层材料的相对磁导率,α(1)为内层材料入射角;
公式(1)中f如下所示:
其中l、h分别为像素的宽和高,sinc为三角函数,k为波数,
步骤4:使用opengl中的映射函数glframebuffertexture将步骤3中计算的散射场分量保存在片元着色器中,然后使用映射函数将片元着色器中的散射场分量映射到纹理缓存中,通过映射函数glbindtexture将纹理缓存中的散射场分量数据映射到cpu内存中,而后在cpu中完成求和,即可得到总散射场,并根据麦克斯韦公式计算表面电流,最终得到实时雷达散射截面积以及模型表面动态实时的电流强度。
本发明的有益效果是由于采用基于像素细分的图形算法,有效避免复杂目标缩放在屏幕上,不同离散片元因为显示精度而导致重合在一个像素上,致使模型细节损失。使用gpu并结合像素细分技术可以大幅度提高模型显示精度及计算精度,极好的弥补了图形算法相比于低频算法精度差的问题,同时不再需要光照模型来获取法矢量信息,光照模型无法避免因为光照颜色分量的精度限制,以及多次推倒计算带来的误差,而像素细分的图形算法直接在gpu中就完成了法矢量的获取以及后期rcs计算,计算结果统一保存到内存中使用cpu完成最后叠加计算,大大提高了cpu和gpu的计算效率,其中精度从0.00135提高到了小数点后第七位,计算效率提到达30倍。
附图说明
图1为本发明的中央处理器图形处理器协同计算框架图。
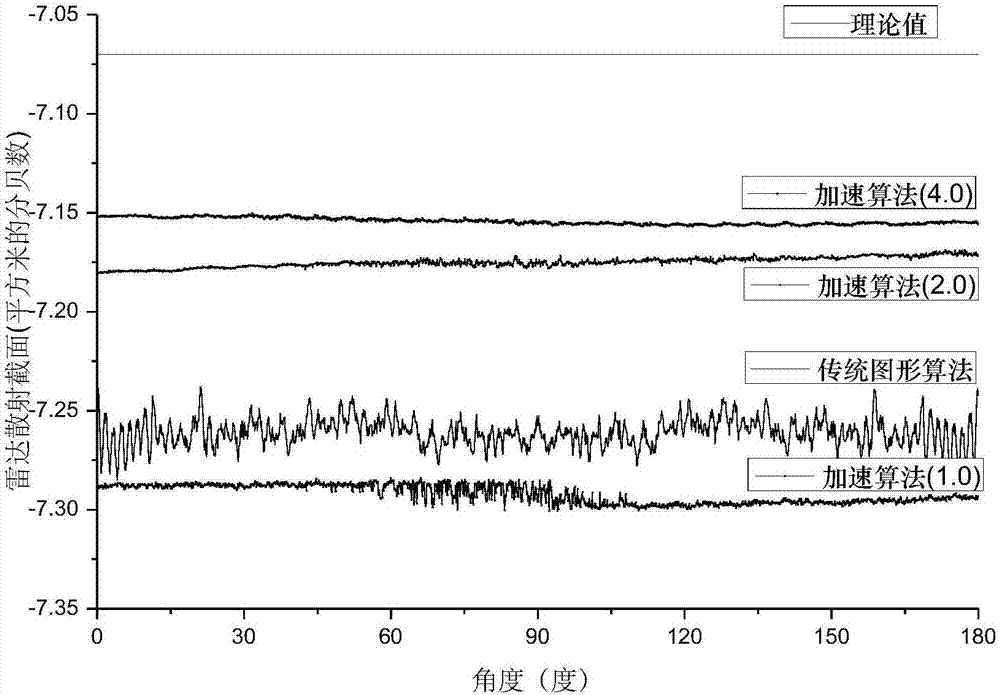
图2为本发明的雷达散射截面积计算结果图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本发明的目的是为了解决在武器外形设计时,大尺寸的复杂目标,如飞机坦克等模型,不能精确快速的计算武器模型的雷达散射截面积的问题,通过本发明提供的方法,可以更精确、高效率的获取雷达散射截面积,并且使模型电磁特效计算过程不在受到屏幕硬件条件的限制。
步骤1:针对飞机导弹类目标进行3d建模,模型信息包括目标的位置信息、目标的材料以及目标材料对应的相对介电常数和相对磁导率,通过3d建模软件调整模型角度和模型比例,使一个像素最多包含一个曲面结构,使用opengl中的glew库函数控制图形处理器(graphicsprocessingunit,gpu),搭建基于着色器处理图形的cpu-gpu异构计算环境,同时在内存与显存中存储基于物理光学法的图形算法,通过程序编程控制中央处理器(centralprocessingunit,cpu)与gpu,当cpu与gpu都处于待命状态时,则完成搭建基于gpu的协同计算框架,此时调用opengl的绘图指令读取3d模型中的模型信息并导入内存;
其中cpu-gpu协同计算框架图如图1所所示,基于gpu的计算框架是使用高版本的opengl来控制gpu中的着色器,将本该在cpu中运行的计算全部放到gpu中来执行,极大的提高了计算的效率,同时可以直接获取gpu中的模型处理数据,不再需要光照模型来推算显存中的模型数据,减少了数据交换,同时省略了繁琐的处理过程。其中,在cpu进行的模型参数变换都转移到gpu中的顶点着色器中完成,以代替光照模型,并获取rcs计算需要的相关数据,同时将相关数据通过opengl导入显存部件中,按照类型编号分组,以备后续计算使用。
步骤2:创建无光照的像素细分计算环境
使用opengl库函数中的glbindrenderbuffers指令函数,控制缓存部件gpu中的存储控件帧缓存对象(framebufferobject,fbo),以fbo为显示载体,将屏幕显示控制在显存中,使用glrenderbufferstorage指令函数设定fbo在显存中的内存空间,将fbo的大小提高到当前所使用屏幕分辨率大小的3到4倍,使用顶点着色器将步骤一中的模型信息离散到fbo缓存部件中,同时在顶点着色器中编程控制gpu将电脑屏幕上的每个像素按照像素边长的中点进行二等分或四等分,即将原来一个像素的数据放大了4倍,或将像素边长4等分后放大了16倍,以此实现像素的细分,细分后的像素根据模型位置信息对应步骤一中的模型信息,使用glshadersource函数将步骤一中的模型信息传入顶点着色器,在顶点着色器中计算模型的法矢量后得到新的模型信息,使用gluseprogram函数将新的模型信息传入gpu中的光栅化模块,模型信息经过光栅化即可离散成各个独立的电磁参数,电磁参数按照像素的位置信息一一对应保存至片元着色器中,至此,像素细分计算环境搭建完成;
利用opengl中对fbo的控制,实现像素细分技术,并同时使得雷达散射目标尺寸不受显示器分辨率限制,使模型显示放在显示内存中创建的虚拟屏幕中完成。细分像素可以有效避免复杂目标缩放在屏幕上,不同离散片元因为显示精度而导致重合在一个像素上,致使模型细节损失,使用gpu,可以不考虑光照影响,并结合像素细分可以大幅度提高模型显示精度及计算精度,极好的弥补了图形算法相比于低频算法精度差的问题;
像素细分完成后,按照细分后的像素对应的模型位置信息,获取步骤1中准备好的计算数据,使每个虚拟细分像素都精确对应各自的计算参数,并按照虚拟细分像素将数据导入到gpu中的片元着色器中,片元着色器是绑定纹理,后期逐个像素进行二次处理的地方,因此可以在片元着色器中完成细分像素的逐个像素散射分量的计算。
步骤3:当片元着色器中获取到步骤二中光栅化的以像素为单位的电磁参数时,片元着色器先进行电磁参数的单位换算和格式换算,换算后的电磁参数按照公式(1)计算即可得出rcs散射值,公式(1)如下:
式(1)中σ表示散射场,λ表示波长,σpixels()表示细分后的像素为单位求和计算,f为幅度函数,k为波数,z′为像素深度,δs为细分后像素的投影面积,ed为绕射场分量,其中γ按照三种不同极化方式对应不同的计算公式,不同极化方式的γ计算公式如下:
其中n′x、n′y、n′z分别为法矢量在坐标轴xyz上的三个坐标分量,εr(2)、εr(1)分别为内层和外层材料的相对介电常数,μr(2)、μr(1)分别为内层和外层材料的相对磁导率,α(1)为内层材料入射角;
步骤一中搭建的协同计算框架为一个cpu和gpu并行的计算环境,所以公式(1)中每个细分后的像素的计算为互不影响的并行运算,极大地节约了rcs离散后的大量数据处理时间;
公式(1)中f如下所示:
其中l、h分别为像素的宽和高,sinc为三角函数,k为波数,
步骤4:使用opengl中的映射函数glframebuffertexture将步骤3中计算的散射场分量保存在片元着色器中,然后使用映射函数将片元着色器中的散射场分量映射到纹理缓存中,通过映射函数glbindtexture将纹理缓存中的散射场分量数据映射到cpu内存中,而后在cpu中完成求和,即可得到总散射场,并根据麦克斯韦公式计算表面电流,最终得到实时雷达散射截面积(radarcrosssection,rcs)以及模型表面动态实时的电流强度。
本发明的仿真计算模型为理想导体球体,球体直径为500mm,仿真条件为:频率8ghz,垂直极化采样间隔为0.1度,共计算180度。
首先,绘制高精度球体模型,而后导入gpu计算程序,在各个着色器中完成相应指令命令的加载,则gpu会自动完成计算直到输出最终rcs计算结果,分别使用传统的图形算法,以及不同细分规格的gpu加速算法多次计算,最终得到如图2所示结果。
图2中理论值代表的是理想导体球的理论值,可以看出,传统图形算法计算的rcs值起伏较大,且均值偏离理论值较高,加速算法(1.0)为使用gpu算法,虚拟屏幕设定以736*736为标准分辨率,像素细分倍数为1倍,加速算法(2.0)为像素细分倍数为4倍的算法,加速算法(4.0)为像素细分倍数为16倍的算法,发现加速算法计算结果起伏更小,更平稳,并且随着细分倍数的增加,计算结果起伏更小,并且均值更加贴近于理论值,由此证明本发明的正确性,同时也说明本发明明显提高了计算的精确度。
如下为计算理想导体球的时间对比表:
其中gpu计算中像素细分倍数为1倍,速度提高倍数达到35.7倍,也证明了本发明的高效性。
- 还没有人留言评论。精彩留言会获得点赞!