粒子群优化算法、多计算机并行处理方法及系统与流程
本发明涉及一种粒子群优化算法、多计算机并行处理方法及系统。
背景技术:
粒子群优化算法(pso)与遗传算法类似,是一种基于迭代的优化算法。系统初始化为一组随机解,通过迭代搜寻最优值。但是它没有遗传算法用的交叉以及变异,而是粒子在解空间追随最优的粒子进行搜索。同遗传算法比较,pso的优势在于简单容易实现并且没有许多参数需要调整其已广泛应用于函数优化、神经网络训练、模糊系统控制以及其他遗传算法的应用领域。
在实际使用时,由于精确粒子群的覆盖范围有限,容易造成精确粒子群初始值使优化算法陷入局部最优的缺陷。
技术实现要素:
本发明的目的是提供一种粒子群优化算法、多计算机并行处理方法及系统,以解决精确粒子群初始值易使优化算法陷入局部最优的问题。
为了解决上述技术问题,本发明提供了一种粒子群优化算法,包括:
步骤s1,初始化广义区间粒子群;
步骤s2,计算各个粒子的初始适应度值;以及
步骤s3,迭代更新粒子群速度和位置,直至输出全局最优解。
进一步,步骤s1中初始化广义区间粒子群的方法包括:
设本粒子群共有m个粒子,每个粒子均为一个广义区间,各个粒子的初始位置和初始速度表达式分别如下:
初始位置表达式:
其中,
初始速度表达式:
其中,
进一步,所述步骤s2中计算各个粒子的初始适应度值的方法包括:
设本粒子群优化算法的目标函数为j(α)=f(α),且分别把m个粒子的上界
进一步,第i个粒子的所述适应度值区间对应的表达式为
进一步,所述步骤s3中迭代更新粒子群速度和位置,直至输出全局最优解的方法包括:
步骤s31,根据给定的粒子速度计算下一时刻各粒子的新位置,并获得新的适应度值区间;以及
步骤s32,根据粒子i的速度更新公式获得在本时刻的粒子速度,以及根据粒子速度计算下一时刻各粒子的新位置,并获得相应新的适应度值区间;
步骤s33,重复步骤s32,直至输出全局最优解。
进一步,所述步骤s31中下一时刻各粒子的新位置的表达式:
通过适应度值区间对应的表达式,更新全局最优值tg和个体极值tp。
进一步,所述步骤s32中本时刻的粒子速度及下一时刻各粒子的新位置的表达式分别为:
本时刻的粒子速度的表达式:
下一时刻各粒子的新位置的表达式:
上式中
w为惯性权重,非负数,调节对解空间的搜索范围;
c1、c2为加速度常数,调节学习最大步长,取值范围为[0,4];
r1、r2为两个随机函数,取值范围[0,1],以增加搜索随机性
pi为粒子i个体经历过的最好位置;
pg为本粒子群所经历过的最好位置;以及
通过适应度值区间对应的表达式,更新全局最优值tg和个体极值tp。
进一步,输出全局最优解的方法包括:
若当前解满足预先设定的终止条件,迭代结束;
若不满足预先设定的终止条件,则重复按照步骤s32不断迭代,直到出现满足终止条件的解,即为全局最优解。
又一方面,本发明还提供了一种多计算机并行处理方法。
通过主机及若干分机采用所述粒子群优化算法获得全局最优解,即
各分机适于计算所分配粒子在各个时刻的位置和速度,并记录此粒子的最佳位置,并把计算结果传递给主机;
主机适于收集各个分机传递过来的各个粒子的最佳位置、当前位置和速度,计算全局最优粒子的位置,并把此信息传递给各个分机,供各个分机确定所属粒子的速度。
第三方面,本发明还提供了一种应用所述粒子群优化算法的多计算机并行计算系统。
所述多计算机并行计算系统包括:主机和若干分机,其中
各分机适于计算所分配粒子在各个时刻的位置和速度,并记录此粒子的最佳位置,并把计算结果传递给主机;
主机适于收集各个分机传递过来的各个粒子的最佳位置、当前位置和速度,计算全局最优粒子的位置,并把此信息传递给各个分机,供各个分机确定所属粒子的速度。
本发明的有益效果是,本发明的粒子群优化算法、多计算机并行处理方法及系统通过广义区间代替精确粒子的方式,大大拓展了粒子群的覆盖范围,有效解决了精确粒子群初始值易使优化算法陷入局部最优的问题,并且可以结合现有多核计算机的并行处理能力,显著提高计算结果的精度和效率。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明的粒子群优化算法的步骤流程图;
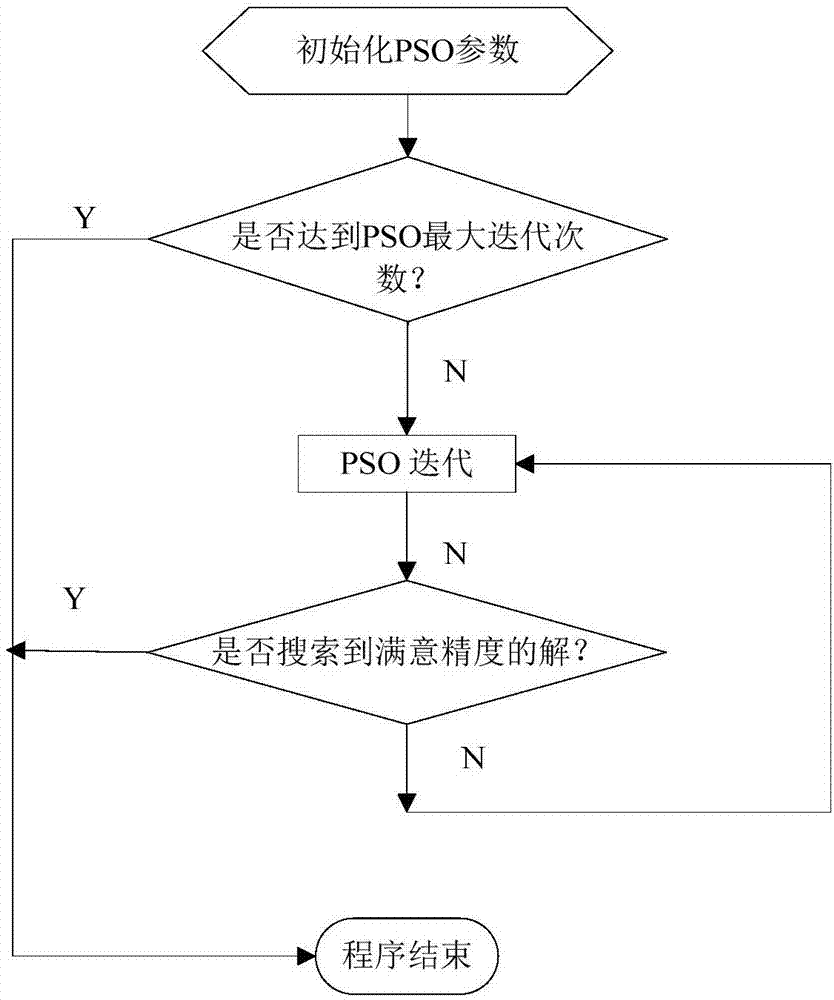
图2是本发明的粒子群优化算法流程图;
图3是本发明的多计算机并行计算系统的结构示意图;
图4是本发明的粒子群优化算法与传统粒子群优化算法的计算适应度曲线的结果对比图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
实施例1
如图1和图2所示,本实施例1提供了一种粒子群优化算法,包括:
步骤s1,初始化广义区间粒子群;
步骤s2,计算各个粒子的初始适应度值;以及
步骤s3,迭代更新粒子群速度和位置,直至输出全局最优解。
具体的,步骤s1中初始化广义区间粒子群的方法包括:
设本粒子群共有m个粒子,每个粒子均为一个广义区间,各个粒子的初始位置和初始速度表达式分别如下:
初始位置表达式:
其中,
初始速度表达式:
其中,
所述步骤s2中计算各个粒子的初始适应度值的方法包括:
设本粒子群优化算法的目标函数为j(α)=f(α),且分别把m个粒子的上界
进一步,第i个粒子的所述适应度值区间对应的表达式为
所述步骤s3中迭代更新粒子群速度和位置,直至输出全局最优解的方法包括:
步骤s31,根据给定的粒子速度计算下一时刻各粒子的新位置,并获得新的适应度值区间;以及
步骤s32,根据粒子i的速度更新公式获得在本时刻的粒子速度,以及根据粒子速度计算下一时刻各粒子的新位置,并获得相应新的适应度值区间;
步骤s33,重复步骤s32,直至输出全局最优解。
具体的,所述步骤s31中下一时刻各粒子的新位置的表达式:
通过适应度值区间对应的表达式,更新全局最优值tg和个体极值tp。
并且,所述步骤s32中本时刻的粒子速度及下一时刻各粒子的新位置的表达式分别为:
本时刻的粒子速度的表达式:
下一时刻各粒子的新位置的表达式:
上式中
w为惯性权重,非负数,调节对解空间的搜索范围;
c1、c2为加速度常数,调节学习最大步长,取值范围为[0,4];
r1、r2为两个随机函数,取值范围[0,1],以增加搜索随机性
pi为粒子i个体经历过的最好位置;
pg为本粒子群所经历过的最好位置;以及
通过适应度值区间对应的表达式,更新全局最优值tg和个体极值tp。
作为输出全局最优解的一种可选的实施方式。
输出全局最优解的方法包括:若当前解满足预先设定的终止条件,迭代结束;若不满足预先设定的终止条件,则重复按照步骤s32不断迭代,直到出现满足终止条件的解,即为全局最优解。其中,终止条件例如但不限于误差条件,也可以根据需要设定终止代数(如图3所示设置为200)。
实施例2
如图3所示,在实施例1基础上,本实施例2还提供了一种多计算机并行处理方法。
通过主机及若干分机采用如实施例1所述粒子群优化算法获得全局最优解,即
各分机适于计算所分配粒子在各个时刻的位置和速度,并记录此粒子的最佳位置,并把计算结果传递给主机;
主机适于收集各个分机传递过来的各个粒子的最佳位置、当前位置和速度,计算全局最优粒子的位置,并把此信息传递给各个分机,供各个分机确定所属粒子的速度。
实施例3
如图3所示,在实施例1基础上,本实施例3还提供了一种应用如实施例1所述的粒子群优化算法的多计算机并行计算系统。
所述多计算机并行计算系统包括:主机和若干分机,其中
各分机适于计算所分配粒子在各个时刻的位置和速度,并记录此粒子的最佳位置,并把计算结果传递给主机;
主机适于收集各个分机传递过来的各个粒子的最佳位置、当前位置和速度,计算全局最优粒子的位置,并把此信息传递给各个分机,供各个分机确定所属粒子的速度。
在实施例2和实施例3基础上,通过图4可知,本粒子群优化算法相对于传统的粒子群算法收敛更快,计算效率更高,结合现有多核计算机的并行处理能力,显著提高计算结果的精度和效率。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!