一种面向监控视频的车型识别、跟踪及矫正方法和装置与流程
本发明涉及图像处理技术领域,特别是指一种面向监控视频的车型识别、跟踪与矫正方法和装置。
背景技术:
智能交通系统(its)是集成目前大多数先进的交通技术和计算机技术的一种交通系统,它能够提高交通管理部门的工作效率,减少资源的浪费,保护环境,还能够降低交通事故的发生率。可以说,智能交通系统将对未来交通方面产生巨大的影响。目前,中国经济快速发展,城市化比例越来越高,同时人们的生活水平也越来越好,汽车的数量也越来越多。但是不断凸显的交通问题,例如交通拥堵、阻塞、频繁的交通事故,增加城市的负担,同时越来越受到社会的重视和关注。现有的交通系统和能力已经解决不了这些问题,这就需要我们大力发展智能交通系统。
计算机视觉和模式识别技术的不断发展为基于图像理解的智能交通系统提供了进入实际应用的机会。计算机视觉是使用计算机完成人视觉的功能,让计算机从现实世界中获得想要的视觉信息,再进行分析处理、理解,得出这些信息的更深层次的属性。在交通环境中的许多信息,例如车辆、交通标志和道路标志,都是从视觉导出的。
车型分类是智能交通系统的重要组成部分,车型分类需要运用计算机技术在监控视频中检测车辆并进行车型分类,将车型分类技术用到智能交通系统中,可以实时知道车型信息,车型识别用以辅助车牌识别就可以锁定具体车辆。这项技术用在停车场和收费站时,能使车辆在不停车的情况下完成对应车型的收费工作,减少了工作人员的工作,同时也减少了车辆通过的时间,减少堵车情况。也可以将这项技术用在公安部门追踪犯罪车辆、查找肇事逃逸车辆等方面。
然而,在自然场景中车辆检测、分类和跟踪都是具有挑战性的工作。其挑战主要来自于自然场景不可控的因素对车辆目标检测的影响;多种类型的车辆之间特征不明显对车型识别的影响;复杂背景和目标粘连对车辆跟踪的影响。这些挑战都会影响整个监控视频下的车型识别系统对车型识别的鲁棒性。
例如:在《使用半监督的卷积神经网络的车辆类型分类》(“vehicletypeclassificationusingasemisupervisedconvolutionalneuralnetwork”)发表于2015年的《ieeetransactionsonintelligenttransportationsystems》)文章中,作者提出了一种利用车辆前脸图片使用半监督的卷积神经网络的进行车型分类的方法。通过多任务学习与少量的标记数据进行训练获得网络的输出层的softmax分类器。对于一个给定的车辆图像,网络能够给出车辆各类型的概率。不同于传统的方法采用手工制作的视觉特征,作者的方法是能够自动学习特征并进行分类任务的。
虽然自然场景下的车型识别的正确率逐年提高,但基本都是假定在相对理想化或固定角度条件下进行的研究,缺少对周围环境变化的考虑,而环境变化的因素正是目前面临的重大问题,同样也是解决与提高车型识别正确率的关键技术的难点。对于虽然已经有研究者提出利用深度学习的方法进行目标的检测和车型分类。但是如何利用视频流信息和深度学习,完成监控场景下的车辆检测、车型识别、跟踪计数,成为业内技术人员所关注的课题。
技术实现要素:
有鉴于此,本发明的目的在于提出一种面向监控视频的车型识别、跟踪与矫正方法和装置,能够更为精确的对车辆进行监控及识别。
基于上述目的本发明提供的面向监控视频的车型识别、跟踪与矫正方法,包括:
对监控视频中的车辆进行检测,获得车辆位置信息和归属概率值;
根据车辆位置信息和归属概率值,评估并筛选出最优车辆,跟踪所述最优车辆;并且根据车辆位置信息获得所述最优车辆的前景区域,识别所述最优车辆的车型;
对所述识别车型的最优车辆进行跟踪,矫正所述最优车辆的车型。
在本发明的一些实施例中,所述对车辆进行检测获得车辆信息包括基于深度学习的ssd目标检测模型对监控视频中的车辆进行训练,获得车辆位置信息和车辆归属概率值。
在本发明的一些实施例中,根据车辆位置信息和归属概率值,评估并筛选出最优车辆,再结合kcf算法进行跟踪。
在本发明的一些实施例中,所述对最优车辆进行跟踪,包括满足两个约束:
约束1:由检测器输出的目标边界框作为跟踪器的输入,边界框中的车辆面积不变时,背景像素会随着边界框的面积增加而增加;
约束2:在车辆面积不变的条件下,为了增加车辆部位在边界框中所占比例,需要给定的框位置尽量准确;
假设在时刻t,ssd算法计算得到检测集中某一目标dobj及其所在图像位置框dbox,和所属概率值dscore,根据相似性度量公式,将之与跟踪集中的所有目标进行相似度的计算;最终得到了最佳匹配tobj,及被估计位置tbox,和概率值tscore;通过如下的目标置信度或价值判别公式,使dobj对tobj进行参数的更新:
其中,area表示目标obj位置框所占面积,score表示经过深度神经网络:计算得到目标obj类别归属概率,归一化到(0,1)之间,α为两部分衡量权重;
根据公式分别对dobj和tobj分别进行价值的判断,如果conf(dobj)>conf(tobj),此时认为检测得到的dobj是优于tobj,这时使用dobj的深度信息参数代替tobj并更新跟踪器。
在本发明的一些实施例中,利用所述跟踪算法跟踪目标,然后通过投票的方式选出当前帧的车型。
在本发明的一些实施例中,所述通过投票选出当前帧的车型,包括:
当通过检测算法获得到一个目标后,再通过跟踪算法发现它是一个新出现的目标,那么分配一个新的id;通过车型分类算法获得车型信息,第一帧的车型信息就显示车型识别算法获得的信息,并将车型信息保存在跟踪器中;新获得一帧时,通过跟踪算法找到同一id的车辆,车型识别算法给出车型信息,然后统计此id下的每种车型数量,选择数量最多的车型作为此id车辆的车型显示出来。
另外,本发明还提供了一种面向监控视频的车型识别、跟踪与矫正装置,包括:
获取单元,用于对监控视频中的车辆进行检测,获得车辆位置信息和归属概率值;
识别单元,用于根据车辆位置信息和归属概率值,评估并筛选出最优车辆,跟踪所述最优车辆;并且根据车辆位置信息获得所述最优车辆的前景区域,识别所述最优车辆的车型;
矫正单元,用于对所述识别车型的最优车辆进行跟踪,矫正所述最优车辆的车型。
在本发明的一些实施例中,所述获取单元采用基于深度学习的ssd目标检测模型来对监控视频中的车辆进行训练,获得车辆位置信息和车辆归属概率值。
在本发明的一些实施例中,所述矫正单元对最优车辆进行跟踪,包括满足两个约束:
约束1:由检测器输出的目标边界框作为跟踪器的输入,边界框中的车辆面积不变时,背景像素会随着边界框的面积增加而增加;
约束2:在车辆面积不变的条件下,为了增加车辆部位在边界框中所占比例,需要给定的框位置尽量准确;
假设在时刻t,ssd算法计算得到检测集中某一目标dobj及其所在图像位置框dbox,和所属概率值dscore,根据相似性度量公式,将之与跟踪集中的所有目标进行相似度的计算;最终得到了最佳匹配tobj,及被估计位置tbox,和概率值tscore;通过如下的目标置信度或价值判别公式,使dobj对tobj进行参数的更新:
其中,area表示目标obj位置框所占面积,score表示经过深度神经网络:计算得到目标obj类别归属概率,归一化到(0,1)之间,α为两部分衡量权重;
根据公式分别对dobj和tobj分别进行价值的判断,如果conf(dobj)>conf(tobj),此时认为检测得到的dobj是优于tobj,这时使用dobj的深度信息参数代替tobj并更新跟踪器。
在本发明的一些实施例中,所述矫正单元利用跟踪算法跟踪目标,然后通过投票的方式选出当前帧的车型,包括:
当通过检测算法获得到一个目标后,再通过跟踪算法发现它是一个新出现的目标,那么分配一个新的id;通过车型分类算法获得车型信息,第一帧的车型信息就显示车型识别算法获得的信息,并将车型信息保存在跟踪器中;新获得一帧时,通过跟踪算法找到同一id的车辆,车型识别算法给出车型信息,然后统计此id下的每种车型数量,选择数量最多的车型作为此id车辆的车型显示出来。
从上面所述可以看出,本发明提供的面向监控视频的车型识别、跟踪与矫正方法和装置,通过对监控视频中的车辆进行检测,获得车辆位置信息和归属概率值;根据车辆位置信息和归属概率值,评估并筛选出最优车辆,跟踪所述最优车辆;并且根据车辆位置信息获得所述最优车辆的前景区域,识别所述最优车辆的车型;对所述识别车型的最优车辆进行跟踪,矫正所述最优车辆的车型。从而,本发明所述面向监控视频的车型识别、跟踪与矫正方法和装置通过车辆跟踪和车型矫正能提高车型识别整体准确性,与此同时不用保证每一帧都能车型识别准确,只需要保证大部分情况下车型识别准确即可。
附图说明
图1为本发明实施例面向监控视频的车型识别、跟踪与矫正方法的流程示意图;
图2为本发明实施中的ssd目标检测网络模型的结构示意图;
图3为本发明实施中inception网络模型块的结构示意图;
图4为本发明实施中车型分类类别展示示意图;
图5为本发明实施中车辆多方向展示示意图;
图6为本发明实施中googlenet模型迭代曲线图;
图7为本发明可参考实施例面向监控视频的车型识别、跟踪与矫正方法的流程示意图;
图8为本发明实施例面向监控视频的车型识别、跟踪与矫正方法的装置结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
需要说明的是,本发明实施例中所有使用“第一”和“第二”的表述均是为了区分两个相同名称非相同的实体或者非相同的参量,可见“第一”“第二”仅为了表述的方便,不应理解为对本发明实施例的限定,后续实施例对此不再一一说明。
参阅图1所示,为本发明实施例面向监控视频的车型识别、跟踪与矫正方法的流程示意图,所述面向监控视频的车型识别、跟踪与矫正方法包括:
步骤101,对监控视频中的车辆进行检测,获得车辆位置信息和归属概率值。
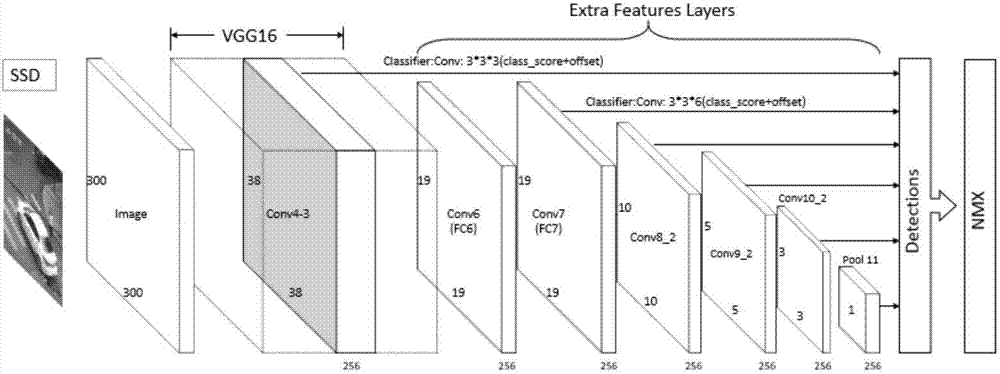
在实施例中,鉴于实际的应用场景的复杂性,可以采用基于深度学习的ssd目标检测模型来对监控视频中的车辆进行检测,其模型作为车辆检测的基础,如图2为ssd目标检测网络模型结构。
其中,ssd目标检测的网络训练图像的输入有500和300两个分辨率格式选择,分辨率越高,图像信息越多,检测结果也越准确,所以训练时采用的网络输入图像分辨率为500*500格式。voc2012关于目标检测数据集中包含了20个类目,每个类目中有11540个样本。当输入图像大小为500*500时,ssd网络模型在上可以取得73.1%的检测平均精度。为了融合从voc2012数据集中得到的有用信息,提高数据资源的利用率和模型泛用能力,较佳地采用微调(fine-tune)的方法,即在voc2012数据集已有训练的基础上,加上车辆数据并调整caffe(卷积神经网络框架)训练参数,继续进行网络模型的训练。例如:图片归一化500*500之后vgg16基础网络层包含16层的卷积层,extrafeatureslayers额外的7层为多尺度卷积层,得到目标位置。另外,nmx为非极大值抑制:筛选出位置合理的目标。在准备好训练集和验证集之后开始训练模型,优选地使用的基础学习率为0.0001,步长为150000,最大迭代次数为100000。通过在gpu上训练以获得用于车辆检测的网络模型。
步骤102,根据车辆位置信息和归属概率值,评估并筛选出最优车辆,跟踪所述最优车辆。
较佳地,基于深度学习检测反馈迭代的最优目标跟踪的方法是以基于滤波跟踪方法kcf作为目标跟踪器的核心,在实际场合中,复杂多变的背景使得跟踪漂移及失败等情况非常之多。原因正是由于车辆的形状,带来的位置框中必然包含大量的背景像素,这就会导致跟踪算法对谁是背景和目标的判断的不确定性。所以,结合目标检测算法和跟踪算法来鲁棒地区分和记录相关目标需要满足两个约束:
约束1:由检测器输出的目标边界框作为跟踪器的输入,边界框中的车辆面积不变时,背景像素会随着边界框的面积增加而增加,所以需要尽可能的缩小边界框的面积。
约束2:在车辆面积不变的条件下,为了增加车辆部位在边界框中所占比例,需要给定的框位置尽量准确。
具体的,假设在时刻t,ssd算法计算得到检测集中某一目标dobj及其所在图像位置框dbox,和所属概率值dscore,根据相似性度量公式,我们将之与跟踪集中的所有目标进行相似度的计算。最终得到了最佳匹配tobj,及被估计位置tbox,和概率值tscore。那么如何使用dobj对tobj进行相关参数的更新,为了将问题数学化,我们使用如下的目标置信度或价值判别公式:
其中,area表示目标obj位置框所占面积,score表示经过深度神经网络:计算得到目标obj类别归属概率,归一化到(0,1)之间,α为两部分衡量权重,优选地选取0.5。上式可知,目标的置信度与边界框面积成负比关系,与归属概率则成正比关系。
根据公式可以分别对dobj和tobj分别进行价值的判断,如果conf(dobj)>conf(tobj),此时认为检测得到的dobj是优于tobj,这时使用dobj的深度信息参数代替tobj并更新跟踪器。也就是说,利用上述两个约束条件,结合深度神经网络的计算结果,得到的目标边界框面积越大或类别归属概率越低,越不利于跟踪算法的处理。反之使用面积小且得分高的目标作为跟踪器的输入,会对复杂监控视频下的长时目标跟踪产生的偏移有很好的抑制和矫正作用。
步骤103,根据车辆位置信息获得所述最优车辆的前景区域,识别所述最优车辆的车型。
作为实施例,对车辆分成公交车、卡车、小轿车、面包车,已经不能满足实际要求,这就需要对车型进行更细的分类。但对于数据集庞大,需要分类的类型较多,传统通过“特征提取”+“分类器”框架进行车辆分类的方式已经不能适用。该实施例使用深度学习的方式来进行车型分类,选择caffe作为深度学习框架,使用googlenet网络模型进行分类。
其中,googlenet是2014年比赛冠军的模型。这个模型使用了很多的卷积和更深的层次。googlenet模型的基本结构和alexnet模型差不多,不过googlenet模型中间使用了一些inception的结构,如图3。inception结构在增加特征表达能力的同时减少计算量。这个网络都是以卷积神经网络为基础的,卷积神经网络的训练是有监督的,其主要是前向传播计算和误差反向计算交替进行。输入层把数据输入,然后通过网络各层计算,最后由输出层得到结果的过程称为前向传播计算。前向传播之后,将得到的结果和预设的正确结果进行比对并计算误差损失,接着网络将总体误差传递给各层的神经元结点,让其自己更新自身的权值,使得整体损失降低,这就是反向传播。
在具体的实施过程中,训练网络之前,需要准备训练样本,并且需要数量充足。本发明将监控场景下的车辆分成4大类10小类(货车类(包含卡车(truck),厢式货车(van)),巴士类(包含中型巴士(bus),公交车(publicbus)),小车类(包含面包车(microbus),小轿车(car),越野车(suv)),非四轮车类(包含摩托车(motorcycle),三轮车(tricycle),自行车(bicycle))),作为交通场景中重要部分——行人(people),算法也会将行人识别出来,也就是共分成11个类别(如图4)。监控场景中拍摄的车辆各个角度都有,为了车型分类模型的鲁棒性,必须尽量保证训练集车辆在各个角度都有,于是按照车头的大概朝向又将每一类训练集分成六个小类。分别是正前、正后、左前、左后、右前、右后(如图5)。我们将获得的训练集按照类别制作成train_lmdb和val_lmdb。googlenet的研究人员在1000类上做各种实验,已经获得了一个很好的模型。为了融合已有模型的有用信息,提高资源的利用率和模型泛化能力,我们采用fine-tune的方法进行微调网络。既在已有模型的基础上,加上本文的数据集,同时调整caffe的训练参数,集训训练网络模型。当迭代50000次之后,我们看googlenet模型迭代曲线图(如图6),发现loss已经趋于稳定,正确率也趋于稳定了,这个模型就可以用来分类了。
步骤104,对所述识别车型的最优车辆进行跟踪,矫正所述最优车辆的车型。
在具体的实施过程中,即使采用学习能力很强的卷积神经网络训练模型,也不可能使得车型分类的正确率到达100%。同一辆车在视频中会出现很多帧,每一帧车辆相对于摄像头的角度都不一样,不用保证每一帧都能分类准确,只需要保证大部分情况下分类准确就可以了。对于监控场景下,使用跟踪算法,对一辆车的车型进行投票矫正,提高了监控场景下车型分类的准确度。
利用基于深度学习检测反馈迭代的最优目标跟踪的方法,再结合车型识别结果,然后通过投票的方式选出当前帧的车型,从而提高车型识别整体准确性。具体过程是当通过检测算法获得到一个目标后,再通过跟踪算法发现它是一个新出现的目标,那么分配一个新的id;通过车型分类算法获得车型信息,第一帧的车型信息就显示车型识别算法获得的信息,并将车型信息保存在跟踪器中。新来一帧时,通过跟踪算法找到同一id的车辆,车型识别算法给出车型信息,然后统计此id下的每种车型数量,选择数量最多的车型作为此id车辆的车型显示出来,如果有多种车型数量相同,选择这一帧车型分类算法得出的车型信息作为输出信息,如此就完成了车型矫正,提高了车型识别的准确性。
作为本发明的另一个可参考的实施例,参阅图7所示,所述面向监控视频的车型识别、跟踪与矫正方法包括:
步骤701:基于深度学习的ssd目标检测模型对车辆进行检测,获得车辆位置信息和车辆归属概率值。
步骤702:根据车辆位置信息和归属概率值,评估并筛选出最优车辆,再结合kcf算法进行跟踪。具体实施过程包括:
结合目标检测算法和跟踪算法来鲁棒地区分和记录相关目标需要满足两个约束:
约束1:由检测器输出的目标边界框作为跟踪器的输入,边界框中的车辆面积不变时,背景像素会随着边界框的面积增加而增加,所以需要尽可能的缩小边界框的面积。
约束2:在车辆面积不变的条件下,为了增加车辆部位在边界框中所占比例,需要给定的框位置尽量准确。
假设在时刻t,ssd算法计算得到检测集中某一目标dobj及其所在图像位置框dbox,和所属概率值dscore,根据相似性度量公式,我们将之与跟踪集中的所有目标进行相似度的计算。最终得到了最佳匹配tobj,及被估计位置tbox,和概率值tscore。那么如何使用dobj对tobj进行相关参数的更新,为了将问题数学化,我们使用如下的目标置信度或价值判别公式:
其中,area表示目标obj位置框所占面积,score表示经过深度神经网络:计算得到目标obj类别归属概率,归一化到(0,1)之间,α为两部分衡量权重,优选地选取0.5。
根据公式可以分别对dobj和tobj分别进行价值的判断,如果conf(dobj)>conf(tobj),此时认为检测得到的dobj是优于tobj,这时使用dobj的深度信息参数代替tobj并更新跟踪器。
步骤703:根据目标检测算法获得车辆位置信息,然后得到车辆前景区域,再采用基于深度学习的googlenet分类模型对车型进行识别,获得车型识别结果。步骤704:根据对该车辆每一帧的跟踪,再结合每一帧的车型识别结果,通过投票方式矫正所述车辆的类型。具体实施过程包括:
当通过检测算法获得到一个目标后,通过跟踪算法发现它是一个新出现的目标,那么分配一个新的id;通过车型分类算法获得车型信息,第一帧的车型信息就显示车型识别算法获得的信息,并将车型信息保存在跟踪器中。新来一帧时,通过跟踪算法找到同一id的车辆,车型识别算法给出车型信息,然后统计此id下的每种车型数量,选择数量最多的车型作为此id车辆的车型显示出来,如果有多种车型数量相同,选择这一帧车型分类算法得出的车型信息作为输出信息。
在本发明的另一方面,如图8所示,所述面向监控视频的车型识别、跟踪与矫正装置,包括依次连接的获取单元801、识别单元802以及矫正单元803。其中,获取单元801对监控视频中的车辆进行检测,获得车辆位置信息和归属概率值。然后识别单元802根据车辆位置信息和归属概率值,评估并筛选出最优车辆,跟踪所述最优车辆。同时,识别单元802根据车辆位置信息获得所述最优车辆的前景区域,识别所述最优车辆的车型。最后,矫正单元803对所述识别车型的最优车辆进行跟踪,矫正所述最优车辆的车型。
较佳地,获取单元801采用基于深度学习的ssd目标检测模型来对监控视频中的车辆进行检测,其模型作为车辆检测的基础。
更进一步地,识别单元802根据车辆位置信息和归属概率值,评估并筛选出最优车辆,再结合kcf跟踪算法进行跟踪。具体实施过程包括:结合目标检测算法和跟踪算法来鲁棒地区分和记录相关目标需要满足两个约束:
约束1:由检测器输出的目标边界框作为跟踪器的输入,边界框中的车辆面积不变时,背景像素会随着边界框的面积增加而增加,所以需要尽可能的缩小边界框的面积。
约束2:在车辆面积不变的条件下,为了增加车辆部位在边界框中所占比例,需要给定的框位置尽量准确。
假设在时刻t,ssd算法计算得到检测集中某一目标dobj及其所在图像位置框dbox,和所属概率值dscore,根据相似性度量公式,我们将之与跟踪集中的所有目标进行相似度的计算。最终得到了最佳匹配tobj,及被估计位置tbox,和概率值tscore。那么如何使用dobj对tobj进行相关参数的更新,为了将问题数学化,我们使用如下的目标置信度或价值判别公式:
其中,area表示目标obj位置框所占面积,score表示经过深度神经网络的计算得到目标obj类别归属概率,归一化到(0,1)之间,α为两部分衡量权重,我们取0.5。上式可知,目标的置信度与边界框面积成负比关系,与归属概率则成正比关系。
根据公式可以分别对dobj和tobj分别进行价值的判断,如果conf(dobj)>conf(tobj),此时认为检测得到的dobj是优于tobj,这时使用dobj的深度信息参数代替tobj并更新跟踪器。
而且,识别单元802还可以根据目标检测算法获得车辆位置信息,然后得到车辆前景区域,再采用基于深度学习的googlenet分类模型对车型进行识别,获得车型识别结果。
同时,矫正单元803利用跟踪算法跟踪目标,再结合每一帧的车型识别结果,然后通过投票选出当前帧的车型,就能提高了车型识别整体准确性。具体过程是当通过检测算法获得到一个目标后,再通过跟踪算法发现它是一个新出现的目标,那么我们就给它分配一个新的id;通过车型分类算法获得车型信息,第一帧的车型信息就显示车型识别算法获得的信息,并将车型信息保存在跟踪器中。新来一帧时,通过跟踪算法找到同一id的车辆,车型识别算法给出车型信息,然后统计此id下的每种车型数量,选择数量最多的车型作为此id车辆的车型显示出来,如果有多种车型数量相同,选择这一帧车型分类算法得出的车型信息作为输出信息,如此就完成了车型矫正,提高了车型识别的准确性。
从上面的所述面向监控视频的车型识别、跟踪与矫正方法和装置,创造性地设计并实现了精确识别车辆的车型;而且,基于视频序列的车型识别,可以用来对监控视频中的车辆进行车型识别、跟踪和矫正;并且,本发明可以对每一视频帧的图像逐个标注出车辆位置的坐标,从而构建出车辆目标检测数据集,基于vggnet的ssd深度神经网络模型,在voc2012目标检测数据集上训练的模型,以fine-tune方式训练得到车辆目标检测模型;而且本发明结合上述检测结果和kcf(核相关滤波)算法,评估并筛选出最优车辆,然后对所述车辆进行跟踪。更进一步地,本发明可以将检测得到的车辆目标进行分类整理,获得车型分类数据集,将该数据集按照1:9的比例分成测试集与训练集,使用googlenet深度神经网络,在imagenet分类数据集的基础上fine-tune得到车型分类模型;同时,利用所获得的车辆目标检测模型车辆的检测,用基于深度学习检测反馈迭代的最优目标跟踪的方法对该车辆进行跟踪,再用获得的车型分类模型进行车型识别,结合跟踪和识别结果用投票的方式矫正车型,最终在监控视频中显示得到最终的车型识别信息;最后,整个所述的面向监控视频的车型识别、跟踪与矫正方法和装置简便、紧凑,易于实现。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。
另外,为简化说明和讨论,并且为了不会使本发明难以理解,在所提供的附图中可以示出或可以不示出与集成电路(ic)芯片和其它部件的公知的电源/接地连接。此外,可以以框图的形式示出装置,以便避免使本发明难以理解,并且这也考虑了以下事实,即关于这些框图装置的实施方式的细节是高度取决于将要实施本发明的平台的(即,这些细节应当完全处于本领域技术人员的理解范围内)。在阐述了具体细节(例如,电路)以描述本发明的示例性实施例的情况下,对本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下或者这些具体细节有变化的情况下实施本发明。因此,这些描述应被认为是说明性的而不是限制性的。
尽管已经结合了本发明的具体实施例对本发明进行了描述,但是根据前面的描述,这些实施例的很多替换、修改和变型对本领域普通技术人员来说将是显而易见的。例如,其它存储器架构(例如,动态ram(dram))可以使用所讨论的实施例。
本发明的实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!