一种三维手势姿态估计方法与流程
本发明涉及计算机视觉与深度学习领域,具体涉及一种三维手势姿态估计方法。
背景技术:
近几年,随着虚拟现实、增强现实技术的逐渐普及以及不可估量发展前景,作为人机交互的一种重要手段,手势识别技术一直受到计算机视觉领域的高度关注,由于人手关节较多、形状较复杂、自由度较高且容易出现遮挡现象,迅速且精确的识别出手势位置及手势动作一直是一个难题。
传统的手势姿态估计方法通常可以分成两种:基于传感器和基于图像。基于传感器的手势姿态估计技术,是指通过在人手掌及手指特定的部位固定加速度计、角速度计等传感器,以通过所穿戴的传感器设备获取人手特定部位的位置与运动状态信息,进而通过运用运动学的方法解算出人手手掌及手指的状态,从而达到手势姿态估计的目的。这种方法由于要穿戴传感器设备,对手势检测局限性很大,而且受传感器本身精度与穿戴位置变化等因素的影响,通常检测误差会较大。另一种基于图像的手势姿态估计方法,通常是通过对rgb相机拍摄到的包含人手的图像使用边缘检测、肤色检测等基于边缘或者区域检测的方法,首先确定人手在图像中的大致区域,进而通过图像分割等手段分割出手指、手腕等细节信息。由于普通相机拍摄到包含手的图片,通常只能反映场景的平面信息,如果手指间出现遮挡,便无法识别出遮挡手指的动作细节,因此也存在较大误差。
近年来,随着深度学习在计算机视觉领域的应用,也有不少人提出采用深度卷积神经网络进行手势识别的方法,但这些方法仍存在诸多缺点,例如:由于采集到的rgb图像存在手部光线强弱差别、肤色差别等,识别的准确度因此下降;所采用的卷积神经网络待训练的参数较多,训练和测试速度较慢。
技术实现要素:
本发明的主要目的在于提出一种基于深度图以及全卷积神经网络的三维手势姿态估计方法,以克服现有的采用深度卷积神经网络进行手势识别的方法所存在的识别精度不高、卷积神经网络的训练参数多、训练和测试速度慢的问题。
本发明为达上述目的而提出的技术方案如下:
一种三维手势姿态估计方法,包括以下步骤:
s1、获取多张手势深度图,并对各手势深度图进行手势前景与背景的分割,以得到多张手势前景图并随机分为训练集和测试集;
s2、按照一预定的手势模型图,构建各手势前景图的实际标签图,所述实际标签图包含手势前景图中代表人手各参考辨识点的多个坐标点,每个坐标点的值包含对应的参考辨识点的坐标值和深度值;
s3、选取训练集中的多张手势前景图输入到一全卷积神经网络中进行手势特征的训练,以提取人手辨识点及其坐标值和深度值,并对应地输出多个预测标签图;
s4、对步骤s3中选取的各手势前景图,分别将各自的所述实际标签图与所述预测标签图进行比较求偏差,并依据所述偏差更新所述全卷积神经网络的训练参数;
s5、重复步骤s3和s4以进行不断的迭代,直至所述偏差不再下降时,保存当前训练参数作为全卷积神经网络的最终参数;其中,每迭代预定次数,则选取测试集中的手势前景图输入到所述全卷积神经网络进行测试;
s6、将待估计的手势深度图输入到具有所述最终参数的全卷积神经网络中,输出所述待估计的手势深度图所对应的标签图。
本发明提出的上述三维手势姿态估计方法,将深度图用于全卷积神经网络进行训练,全卷积神经网络只包含线性的、参数少的卷积层,不包含非线性的、参数多的全连接层,本发明使用卷积层替代全连接层,使得需要训练的参数大大减少、训练速度提升,可以达到快速收敛的效果。经过步骤s1至s5的训练所得到的全卷积神经网络,即可用于三维手势姿态的估计,将待估计的手势深度图输入到该具有最终参数的全卷积神经网络中,即可输出对应的标签图,该标签图即为三维手势姿态估计的结果。因此采用本发明的三维手势姿态估计方法,能够快速、准确地进行手势识别。
更进一步地,所述估计方法还包括:将所述预测标签图输入到一反卷积神经网络中进行逆向复原,以得到对应的模拟手势深度图加入到所述训练集中;其中,所述反卷积神经网络具有与所述卷积神经网络完全对称的架构。本优选的方案中,用于训练全卷积神经网络的深度图,部分来源于反卷积神经网络所复原出的模拟手势深度图,而所复原出的模拟手势深度图具有更加简洁的特征,因此在用于全卷积神经网络的训练时,更容易提取特征,所得到的标签图更加准确,进而使得全卷积神经网络收敛得更好,如此,通过多次迭代训练全卷积神经网络和反卷积神经网络,不断更新参数,使得最终进行三维手势姿态估计时,其估计结果更加接近真实手势。
更进一步地,所述全卷积神经网络包括卷积层和池化层,所述反卷积神经网络包括反卷积层和反池化层;其中,所述卷积层与所述反卷积层具有相同的卷积核尺寸和互逆的参数;所述池化层和所述反池化层具有相同大小的池化区域和步长。本优选的方案中,通过反卷积神经网络对全卷积神经网络的输出进行复原,在经过池化层和反池化层后,可以大大减少原手势深度图中的干扰信息,从而复原的所述模拟手势深度图具有更加简洁的特征,后续再输入到全卷积神经网络中进行训练时,更容易提取特征,所得到的标签图更加准确,进而使得全卷积神经网络收敛得更好。
更进一步地,步骤s1具体包括:
s11、采用深度相机拍摄不同人的多张手势深度图并进行仿射变换处理,以使所述多张手势深度图具有相同的尺寸;
s12、对步骤s11得到的手势深度图,采用随机森林分类器进行手势前景与背景的分割,得到多张手势前景图;
s13、将步骤s12得到的多张手势前景图随机分为数量较多的训练集和数量较少的测试集。
更进一步地,步骤s5中进行测试的具体过程是:选取测试集中的部分手势前景图作为测试图片,输入到所述全卷积神经网络中,对应输出测试图片的预测标签图;将测试图片的预测标签图与对应的实际标签图进行比较求偏差,以评价全卷积神经网络当前的训练效果。事先将手势深度图分为训练集和测试集,训练集用于训练网络,而测试集用于测试网络的准确度,采用测试集中的深度图训练了一定的次数后,可以对网络进行测试,以模拟实际中使用该网络去识别新的手势深度图,从而来评价目前的网络训练效果如何,以指导后续的训练。
更进一步地,所述预定的手势模型图绘示有标注出所述参考辨识点的人手模型,所述参考辨识点至少包括手指关节点、指尖点、手腕关键点以及手掌中心点。
更进一步地,步骤s2中的所述坐标值为二维坐标值。
更进一步地,步骤s4中所述偏差为error,计算方法如下:
j'为预测标签图中坐标点ji'的集合,由(j1',j2',…,jn')构成,ji'=(xi',yi',di');
j为实际标签图中坐标点ji的集合,由(j1,j2,…,jn)构成,ji=(xi,yi,di);
上述n为坐标点的数量,i∈1,2,…,n;x、y为横、纵坐标,d为深度值;依据所述偏差更新所述全卷积神经网络的训练参数的方法为:
附图说明
图1是本发明一种优选的三维手势姿态估计方法的流程图;
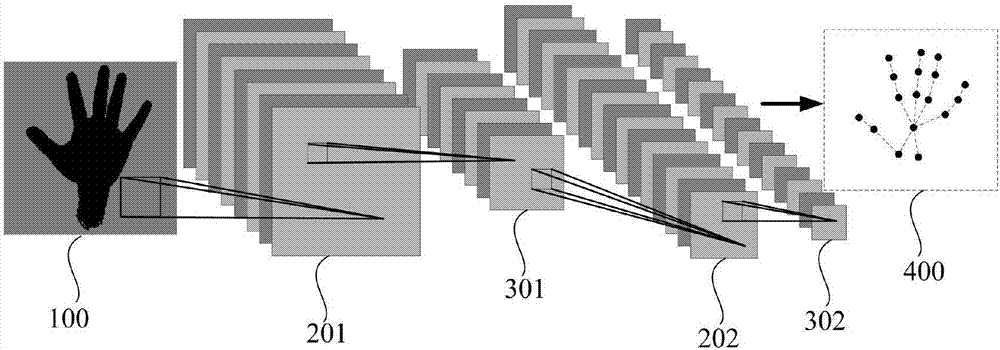
图2是本发明全卷积神经网络的示意图;
图3是本发明反卷积神经网络的示意图;
图4是手势模型图。
具体实施方式
下面结合附图和优选的实施方式对本发明作进一步说明。
本发明的具体实施方式提出了一种三维手势姿态估计方法,该估计方法包括以下步骤s1至s6:
s1、获取多张手势深度图,并对各手势深度图进行手势前景与背景的分割,以得到多张手势前景图并随机分为训练集和测试集。步骤s1的具体过程包括:采用深度相机拍摄不同人的多张手势深度图并进行仿射变换处理,以使所述多张手势深度图具有相同的尺寸;采用随机森林分类器进行手势前景与背景的分割,得到多张手势前景图;将多张手势前景图随机分为数量较多的训练集和数量较少的测试集。
s2、按照一预定的手势模型图,构建各手势前景图的实际标签图,所述实际标签图包含手势前景图中代表人手各参考辨识点的多个坐标点,每个坐标点的值包含对应的参考辨识点的坐标值和深度值。其中,预定的手势模型图的其中两种示例如图4中(a)和(b)所示,绘示有标注出所述参考辨识点10的人手模型,所述参考辨识点包括但不限于手指关节点、指尖点、手腕关键点以及手掌中心点。构建各手势前景图的实际标签图,可以采用人工标注,在每张手势前景图中按照如图4中任一种模型标注出各个参考辨识点及其坐标值和深度值,然后置于一参考坐标系中并去掉手模型的部分,只留下参考辨识点,形成所述实际标签图(实际标签图中各坐标点依据实际人手连接,即是一个人手的骨架)。
s3、选取训练集中的多张手势前景图输入到一全卷积神经网络中进行手势特征的训练,以提取人手辨识点(通过人手辨识点可大致地描绘出手势轮廓)及其坐标值和深度值,并对应地输出多个预测标签图。所述全卷积神经网络的示意图如图2所示,用于训练的手势前景图100(每次训练输入多张手势前景图)作为输入,手势前景图100进入全卷积神经网络后,依次经过卷积层201、池化层301、卷积层201、池化层302、……,卷积层和池化层的数量都不限于图2中所示的。经全卷积网络后,输出所对应的预测标签图400。
s4、对步骤s3中选取的各手势前景图,分别将各自的所述实际标签图与所述预测标签图进行比较求偏差error,并依据所述偏差更新所述全卷积神经网络的训练参数。所述偏差采用欧式距离进行量化,具体的求解方法如下:
j'为预测标签图中坐标点ji'的集合,由(j1',j2',…,jn')构成,ji'=(xi',yi',di');
j为实际标签图中坐标点ji的集合,由(j1,j2,…,jn)构成,ji=(xi,yi,di);
上述n为坐标点的数量,i∈1,2,…,n;x、y为横、纵坐标,d为深度值;
依据所述偏差更新所述全卷积神经网络的训练参数的方法为:
s5、重复步骤s3和s4以进行不断的迭代,直至所述偏差不再下降时,即网络的参数达到收敛,保存当前训练参数作为全卷积神经网络的最终参数;其中,每迭代预定次数,则选取测试集中的手势前景图输入到所述全卷积神经网络进行测试。步骤s5中进行测试的具体过程是:选取测试集中的部分手势前景图作为测试图片,输入到所述全卷积神经网络中,对应输出测试图片的预测标签图;将测试图片的预测标签图与实际标签图进行比较求偏差,以评价全卷积神经网络当前的训练效果。
s6、将待估计的手势深度图输入到具有所述最终参数的全卷积神经网络中,输出所述待估计的手势深度图所对应的标签图。经过步骤s1至s5进行网络训练后,所得到的具有所述最终参数的全卷积神经网络,即可作为本发明中进行三维手势姿态估计所用的估计模型,实际使用时,只要将待估计的手势深度图输入到该估计模型中,所输出的标签图即是估计结果,即可实现手势识别。
在一种更加优选的实施例中,所述估计方法的流程图如图1所示,还包括:将全卷积神经网络所输出的预测标签图输入到一反卷积神经网络中进行逆向复原,以得到对应的模拟手势深度图,并将这些模拟手势深度图加入到所述训练集中,也用于全卷积神经网络的训练。
其中,如图2和图3所示,所述反卷积神经网络具有与所述卷积神经网络完全对称的架构,所述全卷积神经网络包括卷积层(例如图2中的201、202)和池化层(例如图2中的301、302);具体地,进行训练时,手势前景图100经过卷积层时具有如下的变化,随之图片也以像素为单位按照一定的规则增加/删减,此为公知技术,在此不进行赘述。例如,假设输入卷积层的尺寸为l*l,选取k个尺寸相同、像素值不同的方阵作为卷积核,则卷积核的尺寸可以表示为k*c*c,其中k为卷积核的数量,c为卷积核每一维参数的个数。每张手势前景图100分别与k个卷积核进行卷积操作,分别得到k个尺寸完全相同,但像素点不完全相同的新图片。新图片具有新尺寸lc*lc大小如下公式所示:
lc*lc=(l-c+1)*(l-c+1)
如图3所示,所述反卷积神经网络包括反卷积层601、602和反池化层501、502,但图3仅是一种示例,网络层数的多少仅仅是示例性的,并不用于限制本发明的保护范围;其中,所述卷积层与所述反卷积层具有相同的卷积核尺寸和互逆的参数;所述池化层和所述反池化层具有相同大小的池化区域和步长。图片在网络经过池化层时具有如下的变化:假设图片进入池化层前的尺寸为l'*l'。池化即用一个尺寸为p*p的区域每次以f步长在图片上滑动,每次滑动,在该区域中选出一个像素代表该区域的所有像素,则每张图片经过池化层后具有新尺寸lp*lp:
lp*lp=((l'-(f-p))/f)*((l'-(f-p))/f)
从图2的全卷积神经网络输出的预测标签图400,作为输入进入图3所示的反卷积神经网络中,依次经过反池化层501、反卷积层601、反池化层502、反卷积层602、……,最终复原出模拟手势深度图700。所复原出的模拟手势深度图也加入到所述训练集中作为训练所述全卷积神经网络用的图片。所复原出的模拟手势深度图具有更加简洁的特征,因此在用于全卷积神经网络的训练时,更容易提取特征,所得到的标签图更加准确,进而使得全卷积神经网络收敛得更好,如此,通过多次迭代训练全卷积神经网络和反卷积神经网络,不断更新参数,使得最终进行三维手势姿态估计时,其估计结果更加接近真实手势。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!