一种基于GPU加速PET图像重建的方法与流程
本发明属于图像重建
技术领域:
,尤其涉及一种基于gpu加速pet图像重建的方法。
背景技术:
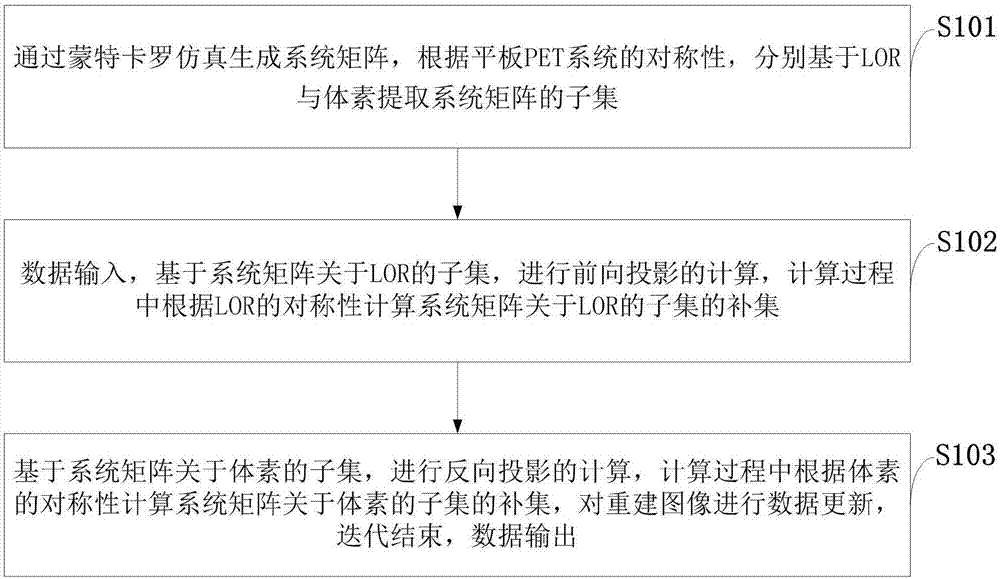
:小动物pet系统因其能在生物实验中得到高分辨率的图像而得到广泛的发展。而采用一对平板探测器的pet成像系统,由于其结构简洁,工程上易于实现,兼有开放性和可调节性,一直受到研究人员的关注。同时在诸多临床聚焦性检查和治疗中,需要针对局部部位得到高质量的pet图像。基于平板结构的系统可针对特定部位和特定应用进行系统定制和优化,在可承受的成本下获得高的灵敏度和空间分辨率。这些优势在针对特定部位肿瘤的治疗规划和疗效监测方面具有独特的潜在价值。然而当想进一步提升灵敏度时,doi效应成为了首要解决的问题。为了解决doi问题,各种基于物理与统计模型的重建方法被提出来。尽管这些方法起到了显著的作用,然而巨大的计算量不能有效的使用这些方法。doi效应的主要问题是仿真模型与实际的成像过程存在偏差,可通过更为复杂物理与统计模型来仿真系统矩阵解决此问题然而复杂的数学模型往往会使得系统矩阵的数据量更为庞大。综上所述,现有技术存在的问题是:目前解决doi效应的方法存在巨大的计算量不能有效的使用,使得系统矩阵的数据量更为庞大。技术实现要素:针对现有技术存在的问题,本发明提供了一种基于gpu加速pet图像重建的方法。本发明是这样实现的,一种基于gpu加速pet图像重建的方法,所述基于gpu加速pet图像重建的方法包括以下步骤:步骤一,通过蒙特卡罗仿真生成系统矩阵,根据平板pet系统的对称性,分别基于响应线与体素提取系统矩阵的子集;步骤二,数据输入,基于系统矩阵关于响应线的子集,进行前向投影的计算,计算过程中根据响应线的对称性计算系统矩阵关于响应线的子集的补集;步骤三,基于系统矩阵关于体素的子集,进行反向投影的计算,计算过程中根据体素的对称性计算系统矩阵关于体素的子集的补集,对重建图像进行数据更新,迭代结束,数据输出。进一步,所述基于gpu加速pet图像重建的方法包括以下步骤:步骤一,获得系统矩阵,通过蒙特卡罗仿真生成系统矩阵,拥有80×104×208个体素,以保证系统矩阵中拥有对称性的响应线穿过相同个数的体素;步骤二,数据输入,从扫描的γ射线获得符合数据,经过预处理后,由cpu读入到内存中,再由内存导入显存中;将系统矩阵基于响应线的子集读入显存,循环系统矩阵基于响应线子集中的响应线,循环过程中为每条与子集中响应线平行的响应线分配一个block来执行,每层重建图像中的体素后插入与其有对称关系的三个体素,并导入gpu的纹理内存中;步骤三,反向投影,将系统矩阵基于体素的子集读入显存,循环前40层,若每层所需视野范围为80×160个体素,则需要为每层40×80个体素分配至gpu中的单独block来执行,重建所需前向投影数据的每个数据后插入与其有对称关系的其它七个数据,并存储在gpu的纹理内存中;步骤四,数据更新,对重建图像每个体素进行更新,若迭代未结束,重复前向投影的计算,迭代结束,数据输出。进一步,所述步骤一中:基于体素的系统矩阵子集为探测器中心晶体所对应的前40层所有体素40×16个及穿过这些体素的响应线,从平板探测器大小为52×104个晶体的所组成的pet系统对应的系统矩阵中提取基于体素的系统矩阵子集。进一步,所述步骤二中:线程分配过程如下:(1)根据gpu的特性设置每个block的尺寸;(2)根据系统矩阵子集中的响应线的位置计算平行响应线的个数;(3)根据平行响应线的个数设置block的个数;(4)按照所述线程块设置执行内核程序。进一步,所述(4)中每个block计算与子集中平行的响应线的同时,计算与平行响应线存在对称关系的另外三条响应线,四条响应线拥有相同的权值,且相同权值的体素位置对称。进一步,所述步骤三中:线程分配过程如下:(1)根据gpu的特性设置每个block的尺寸;(2)根据所需视野范围设置所述block的个数;(3)按照所述block设置执行内核程序。进一步,所述(3)中每个block计算当前体素及其穿过的响应线的同时计算与其拥有对称关系的七个体素,穿过八个体素的响应线拥有对称关系,且权值相同。本发明的另一目的在于提供一种应用所述基于gpu加速pet图像重建的方法的pet成像系统。本发明的另一目的在于提供一种应用所述基于gpu加速pet图像重建的方法的平板pet系统。本发明的优点及积极效果为:使用的系统矩阵由蒙特卡洛(mc)仿真而成,它包含3百万的lor和1百万的体素。这给系统矩阵的存储与使用带来了极大的困难;cheng-yingchou等使用系统矩阵基于lor的子集,再基于lor的对称性来重建的方法使这个问题的到了极大的改善(choucy,dongy,hungy,etal.acceleratingimagereconstructionindual-headpetsystembygpuandsymmetryproperties.[j].plosone,2012,7(12):e50540.),但基于lor的系统矩阵在反向投影的计算中使用极为不便。与使用基于lor的系统矩阵相类似,系统矩阵基于体素的子集,在前向投影的计算中也有同样的问题;而本发明将两种算法结合起来,使得重建速度进一步提高。本发明能够有效的减少pet图像重建的时间,提高算法效率,适用于平板pet系统;针对复杂的数学模型带来的巨大计算量的问题,能有效减少pet图像重建的时间;同时在相同的时间内本发明迭代次数更多,能够有效的提升重建图像的灵敏度;本发明使用ml-em算法来进行重建,ml-em算法是一种迭代重建算法,迭代重建算法越接近收敛状态,重建效果越好,灵敏度也越高。相同的时间内本发明迭代次数更多,更接近收敛状态。本发明适用于平板pet系统,能够为研究小动物体内代谢过程以及生物体局部代谢状态提供更为精确的功能信息;在更短时间内成像可以实现对一些动态的生理过程的实时观测。同时高分辨率的pet图像在确定肿瘤的生物靶区方面能提供精确的信息,从而帮助医生规划更为精确的治疗方案;另外高灵敏度和高分辨率的pet成像能对早期复发的微小病灶进行检测,为制定下一步治疗方案提供重要信息。加速前后前向投影与反向投影单次迭代时间对比,其前向投影加速了125倍,反向投影加速了98倍,单次迭代时间加速了111倍。附图说明图1是本发明实施例提供的基于gpu加速pet图像重建的方法流程图。图2是本发明实施例提供的基于cpu的pet图像重建结果示意图。图3是本发明实施例提供的基于gpu的pet图像加速重建结果示意图。图4是本发明实施例提供的图2、图3pet图像重建结果取中心一列像素的对比曲线示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。下面结合附图对本发明的应用原理作详细的描述。如图1所示,本发明实施例提供的基于gpu加速pet图像重建的方法包括以下步骤:s101:通过蒙特卡罗仿真生成系统矩阵,根据平板pet系统的对称性,分别基于lor与体素提取系统矩阵的子集;s102:数据输入,基于系统矩阵关于lor的子集,进行前向投影的计算,计算过程中根据lor的对称性计算系统矩阵关于lor的子集的补集;s103:基于系统矩阵关于体素的子集,进行反向投影的计算,计算过程中根据体素的对称性计算系统矩阵关于体素的子集的补集,对重建图像进行数据更新,迭代结束,数据输出。下面结合具体实施例对本发明的应用原理作进一步的描述。本发明的实施例结合每个平板探测器拥有(26×52)个晶体的平板pet系统为例进行描述;具体包括以下步骤:步骤1,获得系统矩阵通过蒙特卡罗仿真生成系统矩阵,拥有80×104×208个体素,以保证系统矩阵中拥有对称性的lor穿过相同个数的体素。基于lor的系统矩阵子集为一探测器边角晶体与另一探测器所有晶体所连接lor的集合,共计26×52条。对所有系统矩阵子集中lor所穿过的体素进行坐标变换,变换后所有体素位于80×204×308的体素空间内,以保证对lor进行平移运算时,其体素不超过视野范围。基于体素的系统矩阵子集为探测器中心晶体所对应的前40层所有体素(40×16个)及穿过这些体素的lor,为保证通过对称性可得到完整的系统矩阵,应从平板探测器大小为(52×104)个晶体的所组成的pet系统对应的系统矩阵中提取基于体素的系统矩阵子集,使得通过平移性计算其它体素所穿过的lor时没有缺失,同时为保证其与基于lor计算得到的系统矩阵拥有相同的视野范围,应对体素子集中的体素进行坐标变换。步骤2,前向投影数据输入,从扫描的γ射线获得符合数据,经过预处理后,由cpu读入到内存中,再由内存导入显存中。将系统矩阵基于lor的子集读入显存,循环系统矩阵基于lor子集中的lor,循环过程中为每条与子集中lor平行的lor分配一个block来执行,每层重建图像中的体素后插入与其有对称关系的三个体素,并导入gpu的纹理内存中,其中线程分配过程如下:(1)根据gpu的特性设置每个block的尺寸;(2)根据系统矩阵子集中的lor的位置计算平行lor的个数;(3)根据平行lor的个数设置block的个数;(4)按照所述线程块设置执行内核程序;步骤(4)中每个block计算与子集中平行的lor的同时,计算与平行lor存在对称关系的另外三条lor,四条lor拥有相同的权值,且相同权值的体素位置对称。步骤3,反向投影将系统矩阵基于体素的子集读入显存,循环前40层,若每层所需视野范围为(80×160)个体素,则需要为每层(40×80)个体素分配至gpu中的单独block来执行,超过所需视野范围的体素不计算,重建所需前向投影数据的每个数据后插入与其有对称关系的其它七个数据,并存储在gpu的纹理内存中,其中线程分配过程如下:(1)根据gpu的特性设置每个block的尺寸;(2)根据所需视野范围设置所述block的个数;(3)按照所述block设置执行内核程序;步骤(3)中每个block计算当前体素及其穿过的lor的同时计算与其拥有对称关系的七个体素,穿过八个体素的lor拥有对称关系,且权值相同。步骤4,数据更新对重建图像每个体素进行更新,若迭代未结束,重复前向投影的计算,迭代结束,数据输出。下面结合对比对本发明的应用效果作详细的描述。通过蒙特卡罗仿真十二个同样大小的点源,直径为0.5mm,活度为1μci,得到前向数据,所用的平板pet系统每个平板探测器拥有(26×52)个晶体,每个晶体表面大小为(2㎜×2㎜),重建体素大小为(0.5㎜×0.5㎜×0.5㎜)。对仿真的前向数据分别使用加速前的算法与加速后的算法重建,对比起重建结果与重建时间。图2是加速前迭代30次的重建图像。图3是加速后迭代30次的重建图像。图4对比加速前后的重建图像,取重建图像中心一列像素做对比,两条曲线完全重合。表1是加速前后前向投影与反向投影单次迭代时间对比,其前向投影加速了125倍,反向投影加速了98倍,单次迭代时间加速了111倍。表1加速前后前向投影与反向投影时间对比前向投影(s)前向投影(s)合计(s)加速前182.078159.346341.424加速后1.4531.6123.065本发明能够直接应用到pet成像领域。特别是在复杂的数学模型导致系统矩阵计算量巨大的情况之下,加速效果尤为明显。适用于平板pet系统,能够为研究小动物体内代谢过程以及生物体局部代谢状态提供更为精确的功能信息。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1