一种基于压缩型卷积神经网络的图像去噪方法与流程
本发明涉及数字图像领域,具体涉及一种基于压缩型卷积神经网络的图像去噪方法。
背景技术:
在图像去噪技术上,有传统的去噪方式,也有新兴的利用深度卷积神经网络去噪的方法。本发明基于两项背景技术:1.最新的去噪卷积神经网络dncnn,该网络利用20或17层左右深度的卷积神经网络对高斯加性噪声进行去噪,据dncnn的文献(zhangk,zuow,cheny,etal.beyondagaussiandenoiser:residuallearningofdeepcnnforimagedenoising[j].arxivpreprintarxiv:1608.03981,2016)中所指出的,该方法可以达到目前最好的去噪水平,但是该网络的参数量巨大,对硬件要求较高。2.一种网络压缩技术,即低秩矩阵分解(low-rankmatrixdecomposition,lrd),该技术将权值矩阵分解成两个低秩的矩阵,从而降低了网络需要保存的参数数量。基于这两种技术,本发明构造了一种有效的精简的压缩型去噪卷积神经网络。
1.去噪卷积神经网络(dncnn)
dncnn的残差学习策略采用了resnet中的方式。cnn的残差学习一开始是被提出来解决深度卷积网络(dnn)中的退化问题的,也就是说,随着网络层数的增加,训练的精度(分类问题中)反而会下降。通过假设神经网络中的残差映射比原始映射更加容易学习,残差网络直接为几个堆叠的卷积层学习残差映射。
如图1所示,假设原始映射为h(x),让这些非线性的层学习另外的映射f(x):=h(x)-x,那么就可以间接的得到原始映射。而该假设也被实验证明是正确的。有了这样的一种学习策略,即使是非常深的网络也容易被训练,且能在图像分类和物体检测中提高精度。
dncnn模型同样采用了残差学习方式。但是与resnet不同的是,它没有采用许多个小型的残差单元,而是用整个网络来构成一个大的残差单元,以此来预测残差图像(也就是噪声图像)。假设dncnn的输入是一个有加性噪声的样本y=x+v,dncnn将会学习到一个函数r(y)≈v,这样就可以恢复原始图像x=y-r(y)。因此,dncnn是一个用于解决回归问题的网络,其代价函数是残余图像和估计出的噪声图像的均方差:
式(1)中θ表示网络的参数,这里
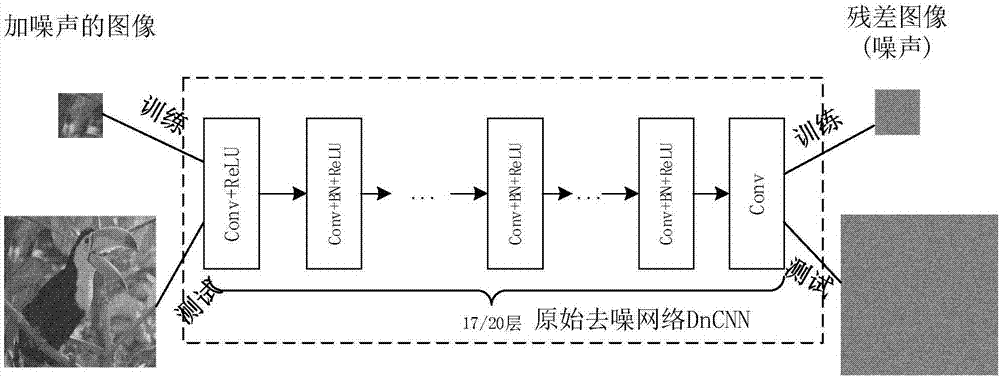
第一种卷积块是conv+relu构成了第一层,也就是对输入图像卷积,而后使用校正线性单元(relu)。第二种也就是中间的2~(d-1)层使用了conv+bn+relu的组合,也就是在卷积层和relu之间加了一层batchnormalization,这是一个比较重要的层,dncnn极大的受益于残差学习和batchnormalization的结合。在使用批量的sgd进行网络的学习时,使用batchnormalization可以减缓训练过程中非线性输入单元的输入分布的变化,从而加快训练的收敛。而最后一种卷积块内仅仅使用卷积层来重建输出层。在dncnn中深度d被设置为17和20,卷积核大小为3×3×nchannel×nout,按照原始的17层的网络结构计算,整个网络约有0.56m参数,如果按照单精度浮点数来存储(占4个字节)的话,在训练过程中将会至少存储4.48mb参数,而在测试过程中也将会存储至少2.24mb的参数。尽管dncnn取得了比较好的去噪结果,但是同传统的去噪方法,例如基于空间域的滤波和基于变换域的滤波去噪相比,它也付出了较多的空间代价。而本发明正好可以解决这种问题。
2.低秩矩阵分解技术
低秩矩阵分解技术(lrd)有多种实现方式,有提倡使用奇异值分解(svd)的,也有采用矩阵因子分解的,也就是简单来说,假设权值矩阵为
假设wα表示在位置域中的某个子集
其中kα是一个矩阵,元素值(kα)ij=k(i,j),λ是一个正则化系数。
技术实现要素:
为了克服现有技术中存在的不足,本发明提出了一种基于压缩型卷积神经网络的图像去噪方法。所构造的网络不仅可以得到同样好的去噪效果,而且相比于原始的去噪神经网络,它具有更小的网络规模,更少的参数量。
为实现上述目的,本发明采用的技术方案为:
一种基于压缩型卷积神经网络的图像去噪方法,包括:构造训练数据集;构造去噪卷积神经网络模型;利用训练数据集对网络模型进行训练;将有噪声的图像输入到训练好的网络中,并用所述有噪声的图像减去网络的输出图像得到清晰的去噪图像;其中,所述神经网络模型包括若干压缩型卷积层,所述压缩型卷积层将卷积单元的四维的权值参数矩阵
作为优选,对二维矩阵w进行低秩矩阵分解时直接构造低秩矩阵u,u的元素uij满足如下区间的均匀分布:
其中,r表示压缩率。
作为优选,训练数据集为被噪声污染过的图像和污染噪声的集合,表示为
本发明中的去噪卷积神经网络的卷积层使用了低秩矩阵分解的压缩技术,使得在取得优秀去噪效果的同时能够大幅压缩网络层数。与现有技术相比,本发明的有益效果是:图像去噪效果优良,即使是将原始网络参数压缩掉75%,去噪后视觉效果与与现有去噪卷积神经网络技术dncnn相比也无明显差异。同时,该网络对硬件要求大大降低,只需要有4gb显存的显卡即可。
附图说明
图1为残差学习单元示意图。
图2为原始去噪网络dncnn示意图。
图3为本发明的压缩型去噪卷积神经网络dncnn结构的示意图;其中
lrdconv表示基于低秩矩阵分解技术压缩过的卷积层。
图4为标准dncnn-s对于σ=25的高斯噪声去噪效果图;其中从左往右依次为原图、噪声污染图和去噪后效果图,psnr为30.63。
图5为本发明的压缩型dncnn-s对于σ=25的高斯噪声去噪效果图;其中(a)压缩比r=1/2,psnr为30.58(b)压缩比r=1/4,psnr为30.42(c)压缩比r=1/8,psnr为30.06(d)压缩比r=1/16,psnr为29.87(e)压缩比r=1/32,psnr为29.25;图(a)~(e)中从左往右依次是原图,噪声污染图,去噪后图像。
图6为标准dncnn-b用于盲去噪的去噪效果图;其中(a)噪声强度为15(b)噪声强度为25(c)噪声强度为50;图(a)~(c)中从左往右依次是原图、加相应噪声的图像、去噪后图像。
图7为本发明的压缩型dncnn-b(压缩比为1/4)的盲去噪效果图;其中(a)噪声强度为15(b)噪声强度为25(c)噪声强度为50;图(a)~(c)中从左往右依次是原图、加相应噪声的图像、去噪后图像。
具体实施方式
下面对本发明技术方案结合附图和实施例进行详细说明。
如图3所示,本发明实施例公开的一种基于压缩型去噪卷积神经网络的图像去噪方法,主要包括:1、构造训练数据集;2、构造基于低秩矩阵分解的压缩型去噪卷积神经网络模型;3、利用训练数据集对网络模型进行训练;4、训练完毕后用加噪声的图像输入到网络中,输出与原图尺寸一样的噪声图像,然后将被噪声污染过的图像减去该输出图像即可得到去噪后的图像。
所构造的压缩型去噪卷积神经网络对原始的去噪神经网络dncnn缩减层数。原始的dncnn有两种用于不同目的的网络,其结构基本一样,一个是用于已知特定强度高斯噪声的图像去噪网络dncnn-s,有17层;还有一个是20层的dncnn-b,用于盲去噪。为使得网络能够在4gb的显存空间得以训练,本发明将这两种网络统一缩减为12层,如果网络层数大于12层,那么4gb的显存则不够用,但理论上层数越多,去噪效果会更好些,并采取同样的卷积结构。如果硬件条件允许,则不必采取某个固定的层数,可以调节网络层数,使得去噪后图像清晰即可。
将dncnn中的每个卷积层conv层的权值参数都应用低秩矩阵分解技术(lrd)分解为两个低秩的矩阵,从而压缩权值参数,压缩率记为r,矩阵的秩由压缩率控制,而压缩率可以人为的调节。具体来说,将cnn中的四维权值张量
在进行lrd分解时,本发明实施例并不采用文献中推荐的一般做法,即使用核岭回归的方法构造u矩阵,考虑到去噪应用的具体特性,本发明令u的元素uij满足如下区间的均匀分布,直接构造低秩矩阵u:
由于u矩阵是固定的,因此训练好的去噪网络可以不用保存u矩阵,待测试时直接在线生成u矩阵即可,采用这种方法后,需要保存的网络参数被进一步的减少。
实验条件:现选取一台计算机进行网络训练,该计算机的配置有intel(r)处理器(3.2ghz)和32gb随机存取存储器(ram),ubuntu14.0464位操作系统,nvidiagtx970(4gb)显卡;软件环境为深度学习框架torch7。
实验对象:训练数据集来自berkeleysegmentationdataset,我们挑选了其中的400幅图像,然后截取了180×180像素的区域。在网络训练时所用的测试数据集同样来自该数据集,但是会与训练数据集严格区分。训练图像中包含了人、自然、城市等许多类型的图片。我们使用标准的测试图像来进行去噪测试。
实验步骤:
我们提出的压缩型去噪卷积神经网络具体构造如表1所示:
表1压缩型去噪卷积神经网络dncnn的网络结构
(1)训练阶段:
步骤1:构造实验数据集。利用训练图像生成64×2000幅小的40×40的采样图像块,采样间隔为20个像素。这里为了进行高斯去噪,我们还将训练集所采用的图像块加上噪声级别为σ=25的高斯随机噪声,需要说明的是这里可以加上任意强度的噪声,这里的标签就相当于是对应的高斯噪声图像,因此网络的输入为
步骤2:利用torch7构造新的卷积层,压缩型卷积层lrdconv。这里利用低秩矩阵分解技术,将权值参数矩阵w分解成uv,需要注意的是原始的
步骤3:构造网络。按照表1所示的方式堆叠网络的不同层,这里需要注意的是我们只用了12层。这是出于精简网络的考虑,但是如果用更多的层数用来去噪,也是可行的。在训练当中,采用adam优化方式,初始学习速率设为0.001,batchsize设为64,权值系数采用l2正则化方式,系数设为0.0001,adam的beta1参数设为0.99,beta2参数设为0.999,epsilon设为1e-8,学习率衰减率设为0.001。一共训练30个epoch即可。
(2)测试阶段
步骤1:将训练后得到的网络的最后一层mse层移走。这样,网络的输出将是和输入一样大小的图像。
步骤2:标准测试图像加上强度为25的高斯噪声得到图像y,将其输入到步骤1中的网络中,得到输出v,然后用图像y减去图像v即可得到去噪后的图像x。对于特定强度的噪声去噪,其效果如图5所示。对于盲去噪效果,其效果如图7所示。
对比图4和图5,图6和图7可知本发明的有效性,而且与原始的去噪卷积神经网络dncnn相比,较少了至少75%的参数。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!