一种分布式存储系统中数据分布的方法及装置与流程
本发明涉及数据存储技术领域,特别涉及一种分布式存储系统中数据分布的方法及装置。
背景技术:
在分布式存储系统中,文件的数据内容以块为粒度进行切分并将其分散存储在不同的存储节点中,已成为一种通常的处理手段(以下简称分布式的处理手段)。块的尺寸可根据系统中普遍的文件尺寸进行设置,典型的块大小为4kb至4mb不等。相较于集中式的处理手段,分布式的处理手段通过数据块分散存储在不同节点,可以充分地发挥存储系统的并发处理能力。例如读取同一个尺寸为64mb的文件,集中式的处理手段产生的时延为一次读取64mb的时延,而分布式的处理手段产生的时延仅为64路并发读取1mb的时延,显然分布式的处理手段大幅降低了读取操作的时延。
因此,文件的数据内容在以块为粒度切分之后,如何分布在各存储节点中,成为当前分布式存储系统领域的重要技术热点。一般地,评价一种数据分布方法的优劣,主要从均衡性、可靠性以及计算量方法进行考量。
现有的数据分布方法包括:
1.随机选取方法。该种方式在为数据块分配节点时完全随机,从宏观上来说,对于大规模的存储系统而言,各节点的数据块将会十分均衡;计算量也很小;但这种完全随机的方法无法显性地控制数据的各副本不在同一个故障域中,一种极端的情况甚至是同一文件的各数据块及副本被分配到同一节点中。另外,在小规模的存储系统中,各节点的均衡性难以保证。
2.固定分段选取方法。该种方式根据故障域进行分段,在段内进行随机选取节点,这种方式提供了较好的可靠性,计算量也不大,但是由于故障域是固定的,因此分段也是固定的,数据分布结果的可能性十分有限;同时,在节点数量无法被段数整除的情况下,亦无法保证各段的节点数量相等,因此均衡性难以得到满足。
3.哈希选取方法。该种方式为每一个切片分配一个全局唯一的号码,并通过某种计算规则求得散列值,然后对节点数进行求余操作,其余数即为切片所存储的节点。该种方法具有较好的均衡性,但计算量较大,可靠性略差。
由上可见,现有技术中的数据分布存储方法,均无法同时满足均衡性高、可靠性强、计算量小的评价指标。
技术实现要素:
本发明的目的在于提供一种分布式存储系统中数据分布的方法及装置,能够同时满足均衡性高、可靠性强、计算量小的评价指标。
为实现上述目的,本发明提供一种分布式存储系统中数据分布的方法,所述方法包括:当所述分布式存储系统初始化时,加载初始化信息;其中,所述初始化信息包括所述分布式存储系统中的节点总数、单文件分配节点数以及文件块尺寸;当在所述分布式存储系统中写入目标文件时,根据所述目标文件的尺寸以及所述文件块尺寸,将所述目标文件划分为多个切片;在所述分布式存储系统中的节点中确定逻辑起始点,并根据所述节点总数和所述单文件分配节点数,确定逻辑分组长度;将所述分布式存储系统中的节点按照逻辑分组长度划分为多个逻辑组,并在各个逻辑组中分别选取一个偏移节点;基于所述逻辑起始点、各个偏移节点以及所述节点总数,确定物理分组;其中,所述物理分组中的节点的数量与所述偏移节点的数量相同;将根据所述目标文件划分得到的所述多个切片依次存放于所述物理分组内的各个节点中。
进一步地,按照下述公式将所述目标文件划分为多个切片:
其中,n表示切片的数量,k表示所述目标文件的尺寸,blocksize表示所述文件块尺寸。
进一步地,所述逻辑分组长度按照下述公式确定:
其中,l表示所述逻辑分组长度,nodenum表示所述节点总数,m表示所述单文件分配节点数,
进一步地,所述物理分组中的各个节点按照下述公式确定:
si=(lstart+li)%nodenum
其中,si表示所述物理分组中第i个节点在所述分布式存储系统中的节点编号,lstart表示所述逻辑起始点在所述分布式存储系统中的节点编号,li表示第i个偏移节点在所述分布式存储系统中的节点编号,nodenum表示所述节点总数,%表示取余运算。
进一步地,所述初始化信息中还包括文件副本个数,并且所述文件副本个数为大于或者等于2的整数;相应地,在确定物理分组之后,所述方法还包括:
将所述物理分组继续划分为与所述文件副本个数相匹配的物理子分组,并分别将各个文件副本存储至相应的物理子分组中。
为实现上述目的,本申请还提供一种分布式存储系统中数据分布的装置,所述装置包括:初始化信息加载单元,用于当所述分布式存储系统初始化时,加载初始化信息;其中,所述初始化信息包括所述分布式存储系统中的节点总数、单文件分配节点数以及文件块尺寸;切片划分单元,用于当在所述分布式存储系统中写入目标文件时,根据所述目标文件的尺寸以及所述文件块尺寸,将所述目标文件划分为多个切片;逻辑分组长度确定单元,用于在所述分布式存储系统中的节点中确定逻辑起始点,并根据所述节点总数和所述单文件分配节点数,确定逻辑分组长度;偏移节点确定单元,用于将所述分布式存储系统中的节点按照逻辑分组长度划分为多个逻辑组,并在各个逻辑组中分别选取一个偏移节点;物理分组确定单元,用于基于所述逻辑起始点、各个偏移节点以及所述节点总数,确定物理分组;其中,所述物理分组中的节点的数量与所述偏移节点的数量相同;切片存放单元,用于将根据所述目标文件划分得到的所述多个切片依次存放于所述物理分组内的各个节点中。
进一步地,所述切片划分单元按照下述公式将所述目标文件划分为多个切片:
其中,n表示切片的数量,k表示所述目标文件的尺寸,blocksize表示所述文件块尺寸。
进一步地,所述逻辑分组长度确定单元按照下述公式确定所述逻辑分组长度:
其中,l表示所述逻辑分组长度,nodenum表示所述节点总数,m表示所述单文件分配节点数,
进一步地,所述物理分组确定单元按照下述公式确定所述物理分组中的各个节点:
si=(lstart+li)%nodenum
其中,si表示所述物理分组中第i个节点在所述分布式存储系统中的节点编号,lstart表示所述逻辑起始点在所述分布式存储系统中的节点编号,li表示第i个偏移节点在所述分布式存储系统中的节点编号,nodenum表示所述节点总数,%表示取余运算。
进一步地,所述初始化信息中还包括文件副本个数,并且所述文件副本个数为大于或者等于2的整数;相应地,所述装置还包括:
物理子分组划分单元,用于将所述物理分组继续划分为与所述文件副本个数相匹配的物理子分组,并分别将各个文件副本存储至相应的物理子分组中。
由上可见,本申请在分布式存储系统中写入目标文件时,可以将目标文件划分为多个切片,然后通过设置逻辑组合物理分组的方法,能够保证写入数据时在各个节点中的均衡性。此外,在确定逻辑组和物理分组时,采用的都是极其简单的运算方法,从而有效地减少了系统的运算量。由于系统的运算量减小,从而保证系统能够避免处于高负载的状态,从而也提高了系统的可靠性。
附图说明
图1是本申请中分布式存储系统中数据分布的方法流程图;
图2是本申请中目标文件的写入示意图;
图3是本申请中分布式存储系统中数据分布的装置功能模块图。
具体实施方式
为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施方式中的附图,对本申请实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本申请一部分实施方式,而不是全部的实施方式。基于本申请中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施方式,都应当属于本申请保护的范围。
请参阅图1,本申请提供一种分布式存储系统中数据分布的方法,所述方法包括:
s1:当所述分布式存储系统初始化时,加载初始化信息;其中,所述初始化信息包括所述分布式存储系统中的节点总数、单文件分配节点数以及文件块尺寸;
s2:当在所述分布式存储系统中写入目标文件时,根据所述目标文件的尺寸以及所述文件块尺寸,将所述目标文件划分为多个切片;
s3:在所述分布式存储系统中的节点中确定逻辑起始点,并根据所述节点总数和所述单文件分配节点数,确定逻辑分组长度;
s4:将所述分布式存储系统中的节点按照逻辑分组长度划分为多个逻辑组,并在各个逻辑组中分别选取一个偏移节点;
s5:基于所述逻辑起始点、各个偏移节点以及所述节点总数,确定物理分组;其中,所述物理分组中的节点的数量与所述偏移节点的数量相同;
s6:将根据所述目标文件划分得到的所述多个切片依次存放于所述物理分组内的各个节点中。
在本实施方式中,按照下述公式将所述目标文件划分为多个切片:
其中,n表示切片的数量,k表示所述目标文件的尺寸,blocksize表示所述文件块尺寸。
在本实施方式中,所述逻辑分组长度按照下述公式确定:
其中,l表示所述逻辑分组长度,nodenum表示所述节点总数,m表示所述单文件分配节点数,
在本实施方式中,所述物理分组中的各个节点按照下述公式确定:
si=(lstart+li)%nodenum
其中,si表示所述物理分组中第i个节点在所述分布式存储系统中的节点编号,lstart表示所述逻辑起始点在所述分布式存储系统中的节点编号,li表示第i个偏移节点在所述分布式存储系统中的节点编号,nodenum表示所述节点总数,%表示取余运算。
在本实施方式中,所述初始化信息中还包括文件副本个数,并且所述文件副本个数为大于或者等于2的整数;相应地,在确定物理分组之后,所述方法还包括:
将所述物理分组继续划分为与所述文件副本个数相匹配的物理子分组,并分别将各个文件副本存储至相应的物理子分组中。
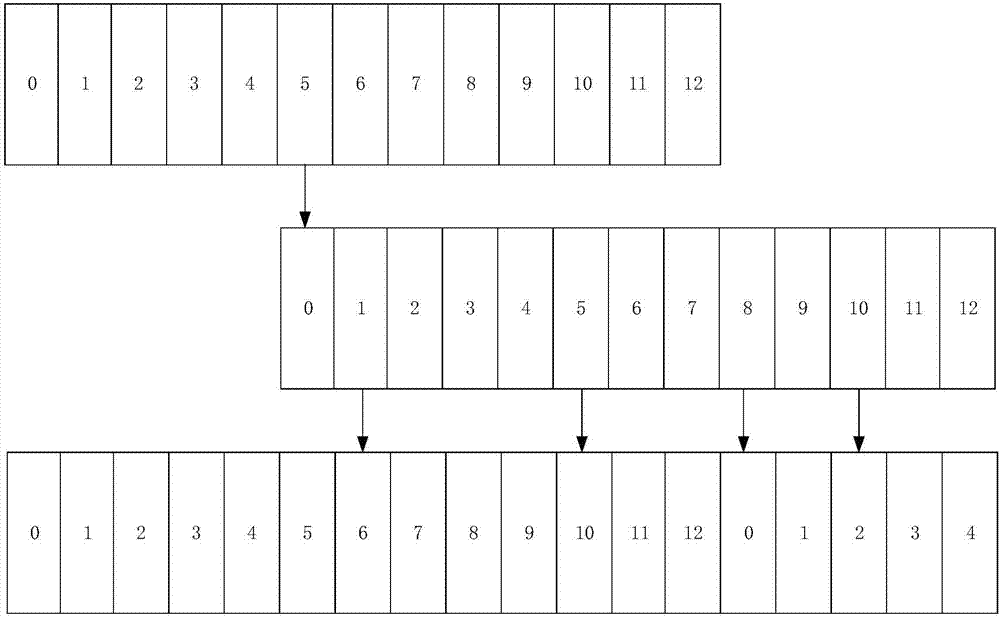
具体地,请结合图2,在单副本的场景中可以包括以下步骤。
步骤101:在该存储系统中有13个存储节点,节点编号为0-12,单文件分配节点数为4,块尺寸为1mb。
步骤102:当写入一个尺寸为7mb的文件时,将该文件切分为7个切片。
步骤103:在13个节点中使用随机函数,选取编号为5的节点为逻辑起始值。
步骤104:将13个节点分成4个逻辑组,其中逻辑组1包含节点0、1、2;逻辑组2包含节点3、4、5;逻辑组3包含节点6、7、8;逻辑组4包含节点9、10、11、12。
步骤105:从4个逻辑组中使用随机函数,分别选取1、5、8、10组成逻辑偏移组。
步骤106:计算物理分组:第一个节点为(5+1)%13=6,第二个节点为(5+5)%13=10,第三个节点为(5+8)%13=0,第四个节点为(5+10)%13=2。
步骤107:将该文件的7个切片存储到物理分组(6、10、0、2)的节点中:第1个切片存储到编号为6的节点中,第2个切片存储到编号为10的节点中,第3个切片存储到编号为0的节点中,第4个切片存储到编号为2的节点中,第5个切片存储到编号为6的节点中,第6个切片存储到编号为10的节点中,第7个切片存储到编号为0的节点中。
在另一个场景中,一个文件可以存在多个副本,在这种情况下,可以按照以下步骤实现:
步骤201:在该存储系统中有121个存储节点,节点编号为0-120,副本个数为4,单文件分配节点数为20,块尺寸为128kb。
步骤202:当写入一个尺寸为1mb的文件时,将该文件切分为8个切片。
步骤203:在121个节点中随机选取99,作为逻辑起始编号。
步骤204:将121个节点分成20个逻辑组,其中逻辑组1包含节点0-5;逻辑组2包含节点6-11;以此类推,逻辑组19包含节点108-113;逻辑组20包含114-121。
步骤205:在20个逻辑组中分别使用随机函数,选取4、7、16、22、26、30、39、46、52、56、64、67、77、80、89、93、100、105、112、119组成逻辑偏移组。
步骤206:计算物理分组:104、107、113、120、3、9、16、25、28、35、43、45、55、56、65、72、79、83、89、94。
步骤207:将第1副本的8个切片存储到物理分组一(104、107、113、120、3):第1个切片存储到编号为104的节点中,第2个切片存储到编号为107的节点中,第3个切片存储到编号为113的节点中,第4个切片存储到编号为120的节点中,第5个切片存储到编号为3的节点中,第6个切片存储到编号为104的节点中,第7个切片存储到编号为107的节点中,第8个切片存储到编号为113的节点中。
步骤208:将第2副本的8个切片存储到物理分组二(9、16、25、28、35):第1个切片存储到编号为9的节点中,第2个切片存储到编号为16的节点中,第3个切片存储到编号为25的节点中,第4个切片存储到编号为28的节点中,第5个切片存储到编号为35的节点中,第6个切片存储到编号为9的节点中,第7个切片存储到编号为16的节点中,第8个切片存储到编号为25的节点中。
步骤209:将第3副本的8个切片存储到物理分组三(43、45、55、56、65):第1个切片存储到编号为43的节点中,第2个切片存储到编号为45的节点中,第3个切片存储到编号为55的节点中,第4个切片存储到编号为56的节点中,第5个切片存储到编号为65的节点中,第6个切片存储到编号为43的节点中,第7个切片存储到编号为45的节点中,第8个切片存储到编号为55的节点中。
步骤210:将第4副本的8个切片存储到物理分组四(72、79、83、89、94):第1个切片存储到编号为72的节点中,第2个切片存储到编号为79的节点中,第3个切片存储到编号为83的节点中,第4个切片存储到编号为89的节点中,第5个切片存储到编号为94的节点中,第6个切片存储到编号为72的节点中,第7个切片存储到编号为79的节点中,第8个切片存储到编号为94的节点中。
请参阅图3,本申请还提供一种分布式存储系统中数据分布的装置,所述装置包括:
初始化信息加载单元100,用于当所述分布式存储系统初始化时,加载初始化信息;其中,所述初始化信息包括所述分布式存储系统中的节点总数、单文件分配节点数以及文件块尺寸;
切片划分单元200,用于当在所述分布式存储系统中写入目标文件时,根据所述目标文件的尺寸以及所述文件块尺寸,将所述目标文件划分为多个切片;
逻辑分组长度确定单元300,用于在所述分布式存储系统中的节点中确定逻辑起始点,并根据所述节点总数和所述单文件分配节点数,确定逻辑分组长度;
偏移节点确定单元400,用于将所述分布式存储系统中的节点按照逻辑分组长度划分为多个逻辑组,并在各个逻辑组中分别选取一个偏移节点;
物理分组确定单元500,用于基于所述逻辑起始点、各个偏移节点以及所述节点总数,确定物理分组;其中,所述物理分组中的节点的数量与所述偏移节点的数量相同;
切片存放单元600,用于将根据所述目标文件划分得到的所述多个切片依次存放于所述物理分组内的各个节点中。
在本实施方式中,所述切片划分单元按照下述公式将所述目标文件划分为多个切片:
其中,n表示切片的数量,k表示所述目标文件的尺寸,blocksize表示所述文件块尺寸。
在本实施方式中,所述逻辑分组长度确定单元按照下述公式确定所述逻辑分组长度:
其中,l表示所述逻辑分组长度,nodenum表示所述节点总数,m表示所述单文件分配节点数,
在本实施方式中,所述物理分组确定单元按照下述公式确定所述物理分组中的各个节点:
si=(lstart+li)%nodenum
其中,si表示所述物理分组中第i个节点在所述分布式存储系统中的节点编号,lstart表示所述逻辑起始点在所述分布式存储系统中的节点编号,li表示第i个偏移节点在所述分布式存储系统中的节点编号,nodenum表示所述节点总数,%表示取余运算。
在本实施方式中,所述初始化信息中还包括文件副本个数,并且所述文件副本个数为大于或者等于2的整数;相应地,所述装置还包括:
物理子分组划分单元,用于将所述物理分组继续划分为与所述文件副本个数相匹配的物理子分组,并分别将各个文件副本存储至相应的物理子分组中。
由上可见,本申请在分布式存储系统中写入目标文件时,可以将目标文件划分为多个切片,然后通过设置逻辑组合物理分组的方法,能够保证写入数据时在各个节点中的均衡性。此外,在确定逻辑组和物理分组时,采用的都是极其简单的运算方法,从而有效地减少了系统的运算量。由于系统的运算量减小,从而保证系统能够避免处于高负载的状态,从而也提高了系统的可靠性。
上面对本申请的各种实施方式的描述以描述的目的提供给本领域技术人员。其不旨在是穷举的、或者不旨在将本发明限制于单个公开的实施方式。如上所述,本申请的各种替代和变化对于上述技术所属领域技术人员而言将是显而易见的。因此,虽然已经具体讨论了一些另选的实施方式,但是其它实施方式将是显而易见的,或者本领域技术人员相对容易得出。本申请旨在包括在此已经讨论过的本发明的所有替代、修改、和变化,以及落在上述申请的精神和范围内的其它实施方式。
本说明书中的各个实施方式均采用递进的方式描述,各个实施方式之间相同相似的部分互相参见即可,每个实施方式重点说明的都是与其他实施方式的不同之处。
虽然通过实施方式描绘了本申请,本领域普通技术人员知道,本申请有许多变形和变化而不脱离本申请的精神,希望所附的权利要求包括这些变形和变化而不脱离本申请的精神。
- 还没有人留言评论。精彩留言会获得点赞!