一种无人机路径规划方法及其装置与流程
本发明属于无人机
技术领域:
,涉及一种无人机路径规划方法,尤其是一种通过自适应进化博弈粒子群优化算法求解无人机全局路径规划方法;本发明还涉及一种无人机路径规划装置,该装置基于上述无人机路径规划方法实现无人机全局路径规划。
背景技术:
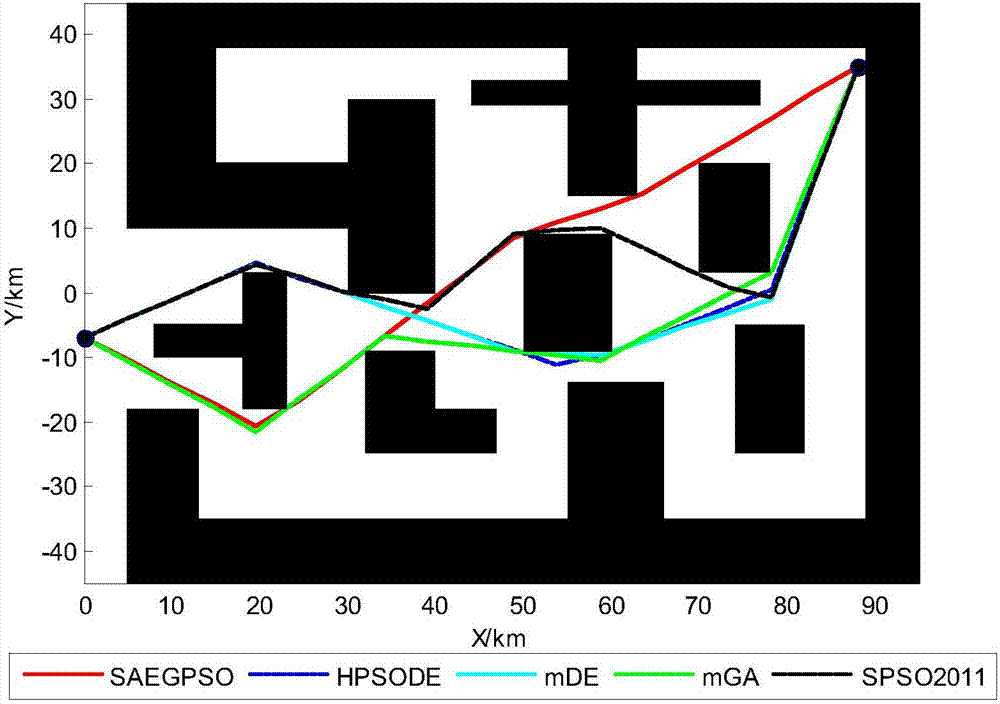
:在过去的几十年里,无人机已经被广泛应用在军事和民用领域去执行一些重要的无人驾驶任务,如救援,搜索和监控。作为无人机任务规划系统的一个关键的问题,路径规划问题是为无人机在一个复杂的环境中从起始位置到终点位置规划出一条可飞行的最优或者次优的安全路径。然而,复杂环境下的无人机路径规划问题已经被证明是一个non-deterministicpolynomial-timehard(np-hard)问题[1,2],即在有限时间多项式里面,为该问题找到一个最优解是十分困难的。这种np-hard特性给无人机路径规划的求解带来了巨大的挑战[3]。因此,在无人机路径领域,高效的优化算法总是极度需要的。作为一种最典型的进化算法,由于它的简单性和快速收敛特性,粒子群(pso)算法在最近十年内被广泛地应用到求解路径规划问题上。通过广大学者对粒子群算法展开的大量研究表明,虽然传统粒子群算法具有较强的收敛速度,但是传统粒子算法也具有两个典型的缺陷。这两个典型的缺陷严重阻碍了粒子算法的优化效率。传统粒子群算法的第一个缺陷是在迭代的过程中粒子容易过早陷入迭代停滞。第二个缺陷是传统粒子群算法不能较好地调节粒子的全局和局部搜索能力。为了提高粒子群算法的性能,这两个基本缺点必须尽量克服。技术实现要素:本发明提供了一种无人机路径规划方法,解决了在路径规划的迭代过程中粒子容易过早陷入迭代停滞、不能较好的调节粒子的全局和局部搜索能力的问题,提高了路径搜索的优化效率。本发明还提供了一种无人机路径规划装置,该装置应用于无人机上,提高了无人机在相对运动空间内的路径规划时效。本发明的技术方案是,一种无人机路径规划方法,包括以下步骤:步骤1,对无人机运动空间进行建模,并且在空间模型的基础上规划问题模型,得到无人机在起始位置到最终位置之间的多条可执行路径;步骤2,生成无人机运动空间的初始粒子群,得到粒子的个体最优位置、粒子群的全局最优位置,并确定基于该粒子的超球面;步骤3,按照spso2011更新每个粒子的速度和位置,计算粒子群在迭代时刻的进化稳定策略,并且根据每个粒子的饱和策略改进每个粒子的位置;步骤4,计算每个粒子的适应值和约束违反度;步骤5,基于可行性原则更新每个粒子的个体最优位置,以及更新粒子群的群体全局最优位置,并且基于可行性原则在待选路径中选择最优路径;步骤6,循环执行步骤3-5,得到无人机在该运动空间内的最优的可执行路径。更进一步的,本发明的特点还在于:其中步骤2的具体过程是:通过粒子的当前位置、粒子的个体最优位置和粒子群的全局最优位置确定一个超球面。其中步骤2中获取每个粒子的重心。其中在每个粒子的超球面中随机产生一个位置点,并且以spso2011方式更新该位置点上粒子的速度和位置。其中步骤3中还包括按照自适应方法调整超球面上粒子的控制参数。其中步骤3中还包括通过进化博弈论收益矩阵计算每一个迭代时刻的进化稳定策略,以及该稳定策略中每个策略的比重。其中步骤4中还包括简化每个粒子的动态系统。其中步骤2中迭代次数达到最大值。本发明还提供了一种无人机路径规划装置,包括建模模块,该模块对无人机的运动空间进行建模,并在此基础上规划问题模型;空间粒子及粒子群更新模块,对运动空间内粒子及粒子群基于饱和策略和可行性原则更新粒子个体最优位置和粒子群的群体的全局最优位置,并最终得到粒子群的群体的全局最优位置的集合;输出模块,将粒子群的群体的全局最优位置的集合转化为该运动空间内的可执行路径,并输出至无人机。更进一步的,本发明的特点还在于:其中空间粒子及粒子群更新模块采用spso2011方式对粒子更新位置和速度。与现有技术相比,本发明的有益效果是:该方法在寻找无人机全局最优路径方面优于hpsode、mga、spso2011和mde等方法,并且该方法更新粒子的位置和速度、粒子的个体最优位置和粒子群的群体的全局最优位置时的计算时间短,提高了路径规划的计算速度,节省了时间。基于该方法的无人机路径规划装置,该装置能够应用在无人机装置或其他飞行器上,保障无人机或其他飞行器能够在运动空间内快速的进行路径规划的计算,并且得到最优路径,保障飞行安全,提高飞行效率。附图说明图1为本发明中运动空间的建模示意图;图2为本发明中第一仿真实例的生成路径图;图3为第一仿真实例中通过本发明的方法得到的最优路径的迭代曲线图;图4为本发明中第二仿真实例的生成路径图;图5为第二仿真实例中通过本发明的方法得到的最优路径的迭代曲线图;图6为本发明中第三仿真实例的生成路径图;图7为第三仿真实例中通过本发明的方法得到的最优路径的迭代曲线图。具体实施方式本发明提供了一种无人机路径规划方法,该方法包括以下步骤:步骤1,对无人机运动空间进行建模,并且在空间模型的基础上规划问题模型,得到无人机在起始位置到最终位置之间的多条可执行路径;建立全局坐标系o-xy,其中st和ta分别表示无人机在坐标系内的起始和最终位置;在o-xy中,线段st-ta被ns个航点等分为ns+1段,其中ns是一个预定义的常数参数;在通过这些航点画出ns条垂直线,得到一系列线l1,l2,...,lm。那么,无人机的任意一条待选路径ph=[st,w1,...,wns,ta]可以在这些垂直线上随机产生。其中在空间模型的基础上规划问题模型如下:本方法中解决无人机的路径规划问题的表达式:其中w0和wns+1分别表示无人机的起始和最终位置;jl和js分别表示路径长度和平滑度;δ1和δ2是表征路径长度和平滑相对重要性的两个权重系数;ψi表示待选路径的第i个路径段的偏航角;lmax和ψmax分别代表无人机的最大飞行距离约束和最大偏航角约束;xi和yi分别是导航点wi的x轴和y轴值;||wi,wi+1||是导航点wi和wi+1之间的欧氏距离。该问题模型的约束条件表示为:jl≤lmax;ψi≤ψmax,1≤i≤ns;wiwi+1∈半自由运动空间,0≤i≤ns。其中步骤2,生成无人机运动空间的初始粒子群,得到粒子的个体最优位置、粒子群的全局最优位置,并确定超球面:hp(bci(t),||bci(t)-xi(t)||),其中t是当前的迭代次数,bci(t)为超球面的质心,表示为其中c1和c2分别表示粒子的认知和社会加速度系数。步骤3,在每个粒子的超球面hp(bci(t),||bci(t)-xi(t)||)中随机产生一个位置点xi'(t),并且该位置点按照spso2011的方式进行更新,具体如下:其中ω是给定的惯性权重值,x(t)和v(t)分别表示粒子的位置和速度。为避免迭代过程中粒子容易过早陷入迭代停滞和不能较好的调节粒子的全局和局部搜索能力不足的问题,该过程还包括采用自适应方法对c1、c2和ω的调整,具体为:其中下标“s”和“f”分别表示对应控制参数的起始和终止值,tmax表示种群的最大迭代次数,δ设定为1e-10,c1s>c1f,c2s<c2f,zi(t)(i=1,2,3)表示迭代次数为t时,第i个策略所占的比重。zi(t)的计算过程为:定义在t次迭代时刻的进化稳定策略为ess(t)=[z1(t),z2(t),z3(t)],该稳定策略的条件为然后定义ess(t)=[z1(t),z2(t),z3(t)]中每个策略所占的比重为其中ei是第t次迭代时刻的三个控制参数,e1(t)=ω(t),e2(t)=c1(t),e3(t)=c2(t),p为t时刻的进化稳定策略,p(t)=ess(t),k为收益矩阵。收益矩阵k为基于进化博弈论,表示为:其中f(ei)(i=1,2,3)表示粒子采用策略ei得到的收益,即代价函数值,表达式为其中f(x(t1-1))表示粒子在迭代次数(t1-1)时的适应值。zi(t1-1)是在迭代次数(t1-1)时的第i个策略所占的比重。步骤4,基于步骤1中获得的路径规划问题表达式:及该问题的约束条件表达式:jl≤lmax;ψi≤ψmax,1≤i≤ns;wiwi+1∈半自由运动空间,0≤i≤ns;计算每个粒子的适应值f(x(t))。计算每个粒子的约束违反度,首先计算每个粒子m的总约束违反度:tdm=dsm+dfm+dym;其中dsm,dfm,dym分别是粒子m违反路径安全、飞行距离和偏航角的程度;dsm的计算过程是:其中nob表示工作环境中的障碍;dfm的计算过程是:其中lmax表示无人机最大飞行距离约束,lm表示路径总长度;dym的计算过程是:其中ns是步骤3中的预定义参数,ψi指粒子m所代表的待选路径的第i个航迹段的偏航角。步骤5,基于可行性原则更新每个粒子的个体最优位置,以及更新粒子群的群体全局最优位置,并且基于可行性原则在待选路径中选择最优路径。步骤6,循环执行步骤3-5,得到无人机在该运动空间内的最优的可执行路径。本发明还提供了一种无人机路径规划装置,包括建模模块,该模块对无人机的运动空间进行建模,并在此基础上规划问题模型;空间粒子及粒子群更新模块,采用spso2011方式对粒子更新位置和速度;对运动空间内粒子及粒子群基于饱和策略和可行性原则更新粒子个体最优位置和粒子群的群体的全局最优位置,并最终得到粒子群的群体的全局最优位置的集合;输出模块,将粒子群的群体的全局最优位置的集合转化为该运动空间内的可执行路径,并输出至无人机。本发明的具体实施方式以及与该方法与hpsode,mga,spso2011和mde方法的性能比较,具体过程如下:具体实施例如下:如图1所示:对无人机的运动空间进行建模,并且建立全局坐标系o-xy,其中st和ta分别表示无人机的起始和最终位置;在o-xy中,线段st-ta被ns个航点等分为ns+1段,其中ns是一个预定义的常数参数。在通过这些航点画出ns条垂直线,得到一系列线l1,l2,...,lm。那么,无人机的任意一条待选路径ph=[st,w1,...,wns,ta]可以在这些垂直线上随机产生。令w0和wns+1分别表示无人机的起始和最终位置,解决无人机路径规划问题可以数学表示如下:则该问题的约束条件表示为:jl≤lmax,ψi≤ψmax,1≤i≤ns,wiwi+1∈半自由运动空间,0≤i≤ns;其中其中jl和js分别表示路径长度和平滑度;δ1和δ2是表征路径长度和平滑相对重要性的两个权重系数;ψi表示待选路径的第i个路径段的偏航角;lmax和ψmax分别代表无人机的最大飞行距离约束和最大偏航角约束;xi和yi分别是导航点wi的x轴和y轴值;||wi,wi+1||是导航点wi和wi+1之间的欧氏距离。在如图1所示的垂线l1,l2,...,lm上随机产生的导航点w1,...,wns的x坐标已经确定,这些导航点的y坐标表示为导航点的坐标用来在运动空间模型中编码粒子的位置,在图1中和分别是无人机的起始和最终的y轴值。当粒子的位置搜索到工作环境之外时,利用饱和机制来修正设计变量饱和机制为:其中width表示无人机运动空间的坐标系的宽度;首先计算每个粒子的m的总约束违反度tdm=dsm+dfm+dym,其中dsm,dfm,dym分别是粒子m违反路径安全、飞行距离和偏航角的程度。其中dsm的计算为:其中nob为无人机载运动空间内的障碍;dfm的计算为:其中lmax为无人机给定的最大飞行距离约束,lm为路径的总长度;dym的计算为:其中ψmax为无人机最大偏航角约束,ns是预定义参数的路径线段参数。ψi指粒子m所代表的待选路径的第i个航迹段的偏航角。以上为确定无人机在如图1所示的运动空间内的建模以及,确定无人机路径规划约束条件;然后需要对运动空间内的每个粒子计算适应值f(x(t))并计算粒子群在迭代时刻的进化稳定策略,并根据每个粒子的饱和机制改进每个粒子的位置。具体过程是:首先遍历确定运动空间中每个粒子的当前位置xi(t),粒子的个体最优位置pbesti(t)和群体的全局最优位置gbest(t);从而确定基于每个粒子的质心bci(t)确定超球面hp(bci(t),||bci(t)-xi(t)||),其中t为当前最大的迭代次数,质心的计算公式为:其中c1和c2分别表示粒子的认知和社会加速度系数。在每个粒子的超球面hp(bci(t),||bci(t)-xi(t)||)中随机产生一个位置点xi'(t),该位置点按照spso2011方法进行更新位置,过程为其中ω是惯性权重,x(t)和v(t)分别表示粒子的位置和速度。为避免迭代过程中粒子容易过早陷入迭代停滞和不能较好地调节粒子的全局和局部搜索能力,使用自适应方法对c1、c2和ω这三个控制参数进行调整,调整过程为其中c1、c2和ω的调整公式中下标带有“s”和“f”分别表示对应控制参数的起始和终止值,tmax表示种群的最大迭代次数,设定δ=1e-10,定c1s>c1f,c2s<c2f;zi(t)(i=1,2,3),表示在迭代次数为t时,第i个策略所占的比重。计算粒子群在迭代时刻的进化稳定则略的具体过程是:首先定义第t次迭代时刻的进化稳定策略为ess(t)=[z1(t),z2(t),z3(t)],其条件为定义ess(t)=[z1(t),z2(t),z3(t)]中每个策略所占的比重为其中ei是第t次迭代时刻的三个控制参数,e1(t)=ω(t),e2(t)=c1(t),e3(t)=c2(t),p为t时刻的进化稳定策略,p(t)=ess(t)。k为收益矩阵,求解可得zi(t)。其中k为基于进化博弈论的收益矩阵,表示为其中f(ei)(i=1,2,3)表示该粒子采用策略ei得到的收益,即代价函数值,表示为其中f(x(t1-1))表示粒子在迭代次数(t1-1)时的适应值。zi(t1-1)是在迭代次数(t1-1)时的第i个策略所占的比重。然后将每个粒子简化为动态系统,表示为其中x(t)和v(t)分别表示粒子的位置和速度,当动态系统收敛时,且满足条件时,确定每个粒子的动态系统收敛性的参数选择原则为根据上述获取到根据饱和机制改进的每个粒子的位置,以及每个粒子的适应值和每个粒子的约束违反度,基于可行性原则更新每个粒子的pbest粒子个体最优位置和粒子群的gbest群体的全局最优位置,最后输出所有粒子群的gbest群体的全局最优位置为该无人机的全局最优路径。将上述实施过程不同的仿真环境中与hpsode,mga,spso2011和mde四种方法进行路径优越性和时间等性能比较;在每个仿真实例中,每种算法的最优路径在40个粒子经过800次迭代后输出;本发明的方法的仿真参数设置如下:ωs=0.9,ωf=0.1,c1s=c2f=2.5,c1f=c2s=0.1;其他对比方法的仿真参数为:mga方法,pe=0.5;mde方法,fm=0.5,cr=0.9;spso2011方法,ω=0.9,ωmin=0.,4,c1=c2=1.1931,ωmax=0.9,c1f=c2s=2;hpsode方法,c1f=c2s=0.1。第一个仿真实例如图2所示,该工作环境为95km×95km,并设置了6种不同形状的规则的障碍物,结合该环境的信息及无人机的物理约束给定如下:st=[0,-7],ta=[88,35],ns=18,lmax=200,ψmax=19π/36。如图3所示,本发明的方法及其他方法得到最优路径和迭代曲线,图中可以看出本发明的方法得到的粒子适应值最低,且计算时间相对较短,具体如下表所示:从上表可知本发明的方法能够获得更低的粒子适应值,并且计算时间也相对更低,处理速度更快。第二个仿真实例如图4所示,该工作环境为100km×100km,并设置了11种不同形状的规则的障碍物,结合该环境的信息及无人机的物理约束给定如下:st=[0,-50],ta=[100,50],ns=20,lmax=300,ψmax=19π/36。如图5所示,本发明的方法及其他方法得到最优路径和迭代曲线,图中可以看出本发明的方法得到的粒子适应值最低,且计算时间相对较短,具体如下表所示:方法适应值计算时间(s)本发明2.071849.37hpsode2.592857.40mde2.687253.15mga2.985954.44spso20112.990345.36从上表可知本发明的方法能够获得更低的粒子适应值,并且计算时间也相对更低,处理速度更快。第三个仿真实例如图6所示,该工作环境为95km×95km,并设置了6种不同形状的规则的障碍物,结合该环境的信息及无人机的物理约束给定如下:st=[0,-35],ta=[95,45],ns=20,lmax=195,ψmax=4π/9。如图5所示,本发明的方法及其他方法得到最优路径和迭代曲线,图中可以看出本发明的方法得到的粒子适应值最低,且计算时间相对较短,具体如下表所示:方法适应值计算时间(s)本发明0.896944.36hpsode1.476451.124mde2.154048.32mga2.375349.46spso20112.964940.45从上表可知本发明的方法能够获得更低的粒子适应值,并且计算时间也相对更低,处理速度更快。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1