一种基于多特征融合的短文本相似度计算方法与流程
本发明涉及自然语言处理技术,尤其涉及一种基于多特征融合的短文本相似度计算方法。
背景技术:
空间向量模型(vsm)将短文本中的特征词项转化成能被计算机识别的数字形式,并且在一定程度上反映出特征词项在短文本中的重要程度。
基于词频的特征提取是指在原始的词项集合中,根据特定的特征评估函数计算挑选出最能反映短文本特征的特征词项集合的过程。词频-逆向文档频率(tf-idf)和互信息(mi)是比较常用的两种词频特征提取方法。信息熵(ie)的概念来源于统计热力学,用于度量体系的混乱程度,它本身并不直接用于文本的特征提取,但是经常融入到其它短文本词频特征提取方法中。
基于语法的特征提取既可以利用语言模型直接从词语上下文环境考察,从而提取短文本的语法性特征;也可以利用神经网络对短文本中给定上下文条件下后续词语的分布建模,即利用深度学习方法提取短文本的语法性特征。word2vec的skip_gram训练模型是神经网络语言模型(nnlm)的一个实现,它省略了nnlm的非线性隐藏层,以牺牲训练精度的方法快速提高词语的预测过程,并通过增加训练语料的方式弥补训练精度,从而使得训练模型能够有效且快速地生成词向量。skip_gram训练模型通过当前词预测其上下文生成的概率,得到不同概率的特征词,从而保留了特征词之间的语法关系。
词对主题模型(btm)是比较常用的一种短文本语义特征提取模型,它是一元混合模型和主题模型的完美结合:首先,为了解决数据稀疏问题,btm结合一元混合模型的优点:所有短文本共享一个主题分布;然后,为了消除每个短文本只有一个主题的弊端,btm在整个语料库上的共现词对上建模;最后,将短文本映射到相应的语义空间(或主题空间),从而对短文本语义进行分析和判断。如果用数学语言描述,主题表示特征词集合中特征词的条件概率分布,特征词的条件概率值大小反映它与主题之间的关系密切程度。
短文本相似度计算可以定义为:对于给定的短文本集合,在研究短文本结构的基础上,提取多种短文本特征(比如词频、语法、语义特征)并量化,从而用数据反映短文本之间的相同点及不同点,相同点越多,相似程度越高,反之,相似程度越低。js距离以一种常用的短文本相似度计算方法,适用于短文本特征以概率形式呈现的情况,可以反映同样的概率空间中两个概率分布的差异情况,它基于kl距离,并改进kl距离的结果不满足非负性、对称性等缺点。
短文本相似度计算是自然语言处理(nlp)乃至机器学习领域的难点和热点,它是nlp中一个重要任务,既可以当成一个单独的任务,又可以作为其它nlp应用的基础。迄今为止,在短文本相似度计算领域,学者们大多偏向于提取词频或语义的单一维度特征,很少有对跨维度的短文本特征进行提取并融合,因此,得到的特征是片面的、不完全的,利用这些特征得到的相似度精度也不会太高。此外,在词频维度特征组合方面,目前的研究大多以特征池或二维特征空间的方式进行组合,缺乏深层次的整合;在语义维度特征提取方面,目前的研究方向通常直接在原始短文本集合上应用btm,即直接利用原始短文本集合丰富的词对信息进行特征提取,这样可能会放大噪音特征产生的不利影响。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种基于多特征融合的短文本相似度计算方法。
本发明解决其技术问题所采用的技术方案是:一种基于多特征融合的短文本相似度计算方法,包括:
(1)获取待计算短文本集合d中的文本数量|m|以及主题数量|k|,通过词频、语法和语义的三维特征提取和融合过程(即过程(a))得到短文本-主题矩阵s;
1.1)对短文本集合d进行短文本词频特征提取;
1.2)对短文本集合d进行短文本语法特征提取;
1.3)短文本语义融合:
首先,获取词频和语法特征融合的权重矩阵w′;然后,在由w′中三元元素<特征项t,短文本d,融合权重w′>组成的共现二元对上利用btm建模;最后,通过计算得到短文本的主题分布概率,即得到短文本的语义融合结果短文本-主题矩阵s;
(2)按公式(10)将短文本-主题矩阵s转化为短文本向量集合z,初始化相似度计算结果矩阵y;
(3)不重复选取集合z中的短文本向量d1,如果集合z中没有可选取的短文本,转到步骤(6);
(4)不重复选取集合z中的短文本向量d2,如果集合z中没有可选取的短文本,转到步骤(3);
(5)计算短文本d1和d2之间的相似度,将结果记录到相似度结果矩阵y中,转到步骤(4);
(6)得到短文本相似度结果矩阵y。
按上述方案,所述步骤1.1)中设短文本集合d中的文本数量为|m|,词典中不重复特征项数量为|n|,采用hti方法计算权值矩阵,具体步骤如下:
1.1.1):初始化特征项索引i和短文本索引j的值为0,初始化权值矩阵w为零矩阵;
1.1.2):统计计算特征项ti在短文本dj中出现的频率并赋值给tf(ti,dj);
1.1.3):计算特征项局部因子,采用的计算公式为:
localt(ti,dj)=log(tf(ti,dj)+β)(1)
其中,tf(ti,dj)表示特征项ti在短文本dj中出现的频率,β为常数因子(一般取经验值1)。
1.1.4):计算特征项ti和短文本dj的相关性因子,采用的计算公式为:
其中,p(ti,dj)表示特征项ti和短文本dj同时出现的概率,p(ti)表示特征项ti在短文本集中出现的概率,p(dj)表示短文本dj在短文本集中出现的概率。
1.1.5):计算特征项全局因子,采用的计算公式为:
其中,n是短文本的总数量,c(ti,dj)表示特征项ti和短文本dj的相关性因子,α是常数因子(一般取经验值1)。
1.1.6):计算特征项-短文本对(ti,dj)的hti值,并赋值给wij,hti权值计算公式:
hti(ti,dj)=localt(ti,dj)×globalt(ti,dj)(4)
其中localt(ti,dj)表示特征项局部因子,globalt(ti,dj)表示特征项全局因子;
1.1.7):对于每一个特征项-短文本对(ti,dj),重复1.1.2)至1.1.6)的操作,得到短文本集合d的hti权值矩阵w。
按上述方案,所述步骤1.2)中短文本语法特征提取是利用word2vec的skip_gram模型训练短文本集合d得到词向量集合x:
x=(x1,x2,...,xi)(5)
其中,xi表示特征项ti的词向量。
按上述方案,所述步骤1.3)中短文本语义融合的具体步骤如下:
1.3.1):根据步骤1.2)获得的词向量集合x的每一个词向量xi,计算词向量归一化因子:
其中,m表示预定的词向量的维数,k表示词向量xi第k维的值。
1.3.2):对于hti权值矩阵w中的每一个三元元素<特征项t,文本d,hti权重w>,计算权重归一化因子:
其中,hti(ti,dj)表示短文本dj中特征词项ti的hti权重w。
1.3.3):利用词向量归一化因子和权重归一化因子计算融合权重,并用融合权重替换矩阵w中每一个三元元素的hti权重w,得到新的词频和语法融合权重矩阵w′。融合权重计算公式:
nl(ti,dj)=f(ti,dj)×g(i)(8)
1.3.4):在融合权重矩阵w′上利用btm生成语料库b(或称共现二元对集合b)
1.3.5):为集合b中的每个共现二元对b=(ci,cj)随机初始化主题,初始化迭代次数i=0;
1.3.6):对集合b中的每个共现二元对b=(ci,cj)计算状态转移概率:
1.3.7):重复执行步骤1.3.6),同时更新状态转移概率公式(9)中的频数ns、
1.3.8):利用btm计算整个短文本集的主题分布θs和特定主题下的三元元素c的分布φc|s,从而得到每个短文本的主题概率分布,即获得短文本-主题矩阵s。
按上述方案,所述步骤2)中短文本向量的计算如下:
短文本集合d经过hsbm模型后,得到短文本-主题分布矩阵s,s中的每一个元素都是一个条件概率,对矩阵s中的每一列,将其转化为短文本的向量形式:
di=(p(s1|di),p(s2|di),p(s3|di),...,p(s|k||di))(10)
其中,p(si|di)表示短文本di被分配到主题si下的条件概率值,|k|表示主题的数量;
基于公式(10),将短文本-主题分布矩阵s转化为短文本向量集合z。
按上述方案,所述步骤6)中计算短文本d1和d2之间的相似度采用以下公式:
kl距离和js距离的计算公式为:
其中,d1、d2为短文本的概率分布向量,d1(k)、d2(k)分别表示概率分布向量d1、d2中第k个的概率。
本发明产生的有益效果是:
(1)本方法在剖析tf-idf、互信息两种词频特征提取方法的基础上,结合信息熵的概念,对其进行有效融合,提出短文本词频特征提取方法hti,实现词频维度多种特征的深层次整合。
(2)本方法基于btm构建短文本的语义特征提取模型hsbm,不再直接对短文本语料库中的词对生成过程建模,而是先获取短文本-特征词融合权重矩阵w′,然后在由w′中三元元素<特征项t,文本d,融合权重w′>组成的共现二元对上建模,一定程度上去除了噪音特征带来的不利影响。
(3)本方法从词频、语法、语义多个维度提取特征,有效地提高短文本相似度计算精度。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的hsbm的模型结构图;
图2是本发明实施例的mfsm的模型结构图;
图3是本发明实施例的基于多特征融合的短文本相似度计算方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,图1是hsbm(hti-skip_gram-btmfusionmodel)的模型结构图,其中,参数说明如下:
过程(i)中,圆角矩形(例如“hti”)表示特征提取方法或模型,六边形表示短文本集合;圆圈表示权重矩阵:w是通过hti方法得到的hti权重矩阵,x是通过skip_gram训练模型得到的特征词向量集合,w′是hti权重矩阵w和特征词向量集合x进行归一化操作(nl)得到的短文本-特征词融合权重矩阵;|m|代表短文本集合中的总文本数量,|n|代表特征词项的数量。
过程(ii)中透明圆圈(例如“θ”)表示隐含参数,阴影圆圈(例如“ci”)表示可通过采样直接获取的变量;α是dirichlet分布θ的超参,β是dirichlet分布
如图3所示,本发明方法的基本步骤如下:
假如短文本集合d中的文本数量为|m|,主题数量为|k|
(1)通过词频、语法和语义的三维特征提取和融合过程(即过程(a))得到短文本-主题矩阵s;
(2)按公式(10)将短文本-主题矩阵s转化为短文本向量集合z,初始化相似度计算结果矩阵y;
(3)不重复选取集合z中的短文本向量d1,如果集合z中没有可选取的短文本,转到步骤(6);
(4)不重复选取集合z中的短文本向量d2,如果集合z中没有可选取的短文本,转到步骤(3);
(5)按公式(11)和公式(12)计算短文本d1和d2之间的相似度,将结果记录到相似度结果矩阵y中,转到步骤(4);
(6)得到短文本相似度结果矩阵y。
词频、语法和语义的三维特征提取和融合过程
词频、语法和语义的三维特征提取和融合过程主要利用本专利设计的hsbm模型实现,它的基本步骤是:首先从词频和语法两个维度分别提取出短文本特征,然后在语义维度进行有机融合。因此,实施过程分为三个阶段:短文本词频特征提取阶段;短文本语法特征提取阶段;短文本语义融合阶段。下面会对这三个阶段分别进行介绍。
短文本词频特征提取阶段
短文本词频特征提取阶段主要利用本专利设计的hti(hybridtf-idf)方法实现,该方法利用mi以及ie的概念对tf-idf进行改进,保留tf对短文本特征提取的重要作用,同时优化idf的结构,使其更加准确地反映特征词在所有短文本中的分布情况以及重要程度,从而更有效地调整特征词的权值,提高相似度计算的精度。
假如短文本集合d中的文本数量为|m|,词典中不重复特征项数量为|n|,hti方法计算权值矩阵的基本步骤:
第一步:初始化特征项索引i和短文本索引j的值为0,初始化权值矩阵w为零矩阵;
第二步:统计计算特征项ti在短文本dj中出现的频率并赋值给tf(ti,dj);
第三步:计算特征项局部因子,它的计算公式为:
localt(ti,dj)=log(tf(ti,dj)+β)(1)
其中,tf(ti,dj)表示特征项ti在短文本dj中出现的频率,β为常数因子(一般取经验值1)。
第四步:计算特征项ti和短文本dj的相关性因子,它的计算公式为:
其中,p(ti,dj)表示特征项ti和短文本dj同时出现的概率,p(ti)表示特征项ti在短文本集中出现的概率,p(dj)表示短文本dj在短文本集中出现的概率。
第五步:计算特征项全局因子,它的计算公式为:
其中,n是短文本的总数量,c(ti,dj)表示特征项ti和短文本dj的相关性因子,α是常数因子(一般取经验值1)。
第六步:计算特征项-短文本对(ti,dj)的hti值,并赋值给wij,hti权值计算公式:
hti(ti,dj)=localt(ti,dj)×globalt(ti,dj)(4)
其中localt(ti,dj)表示特征项局部因子,globalt(ti,dj)表示特征项全局因子。
第七步:对于每一个特征项-短文本对(ti,dj),重复步骤二~六的操作,得到短文本集合d的hti权值矩阵w。
短文本语法特征提取阶段
短文本语法特征提取阶段主要利用word2vec的skip_gram模型训练短文本集合d得到词向量集合x:
x=(x1,x2,...,xi)(5)
其中,xi表示特征项ti的词向量。
短文本语义融合阶段
在hsbm模型中,短文本语义融合阶段的实施是:首先,获取词频和语法特征融合的权重矩阵w′;然后,在由w′中三元元素<特征项t,短文本d,融合权重w′>组成的共现二元对上利用btm建模;最后,通过计算得到短文本的主题分布概率,即得到短文本的语义融合结果。该阶段的具体步骤(图1中过程(i)包含步骤一~三,过程(ii)包含步骤四~八):
第一步:对于式(5)中词向量集合x的每一个词向量xi,计算词向量归一化因子:
其中,m表示预定的词向量的维数,k表示词向量xi第k维的值。
第二步:对于hti权值矩阵w中的每一个每一个三元元素<特征项t,文本d,hti权重w>,计算权重归一化因子:
其中,hti(ti,dj)表示短文本dj中特征词项ti的hti权重w。
第三步:利用词向量归一化因子和权重归一化因子计算融合权重,并用融合权重替换矩阵w中每一个三元元素的hti权重w,得到新的词频和语法融合权重矩阵w′。融合权重计算公式:
nl(ti,dj)=f(ti,dj)×g(i)(8)
第四步:在融合权重矩阵w′上利用btm生成语料库b(或称共现二元对集合b)
第五步:为集合b中的每个共现二元对b=(ci,cj)随机初始化主题,初始化迭代次数i=0;
第六步:对集合b中的每个共现二元对b=(ci,cj)计算状态转移概率:
第七步:重复执行步骤六,同时更新状态转移概率公式(9)中的频数ns、
第八步:利用btm计算整个短文本集的主题分布θs和特定主题下的三元元素c的分布φc|s,从而每个短文本的主题概率分布,即获得短文本-主题矩阵s。
基于多特征融合的短文本相似度计算方法的实现
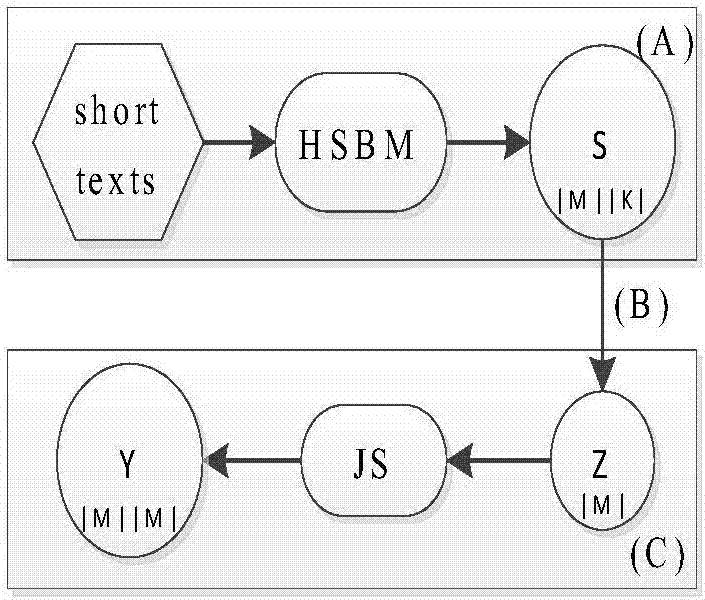
基于多特征融合的短文本相似度计算方法的基本思想是:首先分别从词频、语法和语义维度提取出短文本特征,然后对其进行有机融合,并将融合结果量化,从而计算短文本之间的相似度。该方法主要利用本专利设计的mfsm模型实现,如图2所示,图2是mfsm(multi-featurebasedsimilarity-calculationmodel)的模型结构图,其中,s是短文本集合通过hsbm模型得到的短文本-主题分布矩阵,z是短文本向量集合,y是短文本相似度结果矩阵,|m|代表短文本集合中的文本数量,|k|代表主题数量,js表示对短文本向量集合z进行处理的相似度计算方法(即js距离)。方法的具体实现主要分为3个过程:(a)词频、语法和语义的三维特征提取和融合;(b)短文本向量的计算;(c)短文本相似度的计算。其中,过程(a)在前文中已实现。下面先对过程(b)和过程(c)进行介绍,然后阐述本方法的基本步骤。
短文本向量的计算
短文本集合d经过hsbm模型后,得到短文本-主题分布矩阵s,s中的每一个元素都是一个条件概率,对矩阵s中的每一列,将其转化为短文本的向量形式:
di=(p(s1|di),p(s2|di),p(s3|di),...,p(s|k||di))(10)
其中,p(si|di)表示短文本di被分配到主题si下的条件概率值,|k|表示主题的数量。
显然,短文本已经映射到相应的语义空间(即主题空间)。基于公式(10),将短文本-主题分布矩阵s转化为短文本向量集合z(即图2中过程(b)),可作为过程(c)中短文本相似度计算的输入。
短文本相似度的计算
由于短文本向量集合z中的每一个短文本向量都以概率的形式呈现,因此,本方法利用js距离计算短文本之间的相似度,它基于kl距离,并改进kl距离的结果不满足非负性、对称性等缺点。kl距离和js距离的计算公式为:
其中,d1、d2为短文本的概率分布向量,d1(k)、d2(k)分别表示概率分布向量d1、d2中第k个的概率。
目前,短文本相似度计算所利用的短文本特征的维度比较单一,大多偏向于提取词频或语义的单一维度特征,很少有对跨维度的短文本特征进行提取并融合,因此,得到的特征是片面的、不完全的,利用这些特征得到的相似度精度也不会太高。本专利提出一种基于多特征融合的短文本相似度计算方法,首先,设计hti方法提取短文本的词频特征,其次,利用已有的word2vec的skip_gram训练模型提取短文本的语法特征,然后,设计hsbm模型在语义维度上对词频和语法特征进行有机融合,最后,设计mfsm模型计算将融合结果向量化,并计算短文本之间的相似度。本专利从多个维度提取短文本的特征,因此能有效地提高短文本相似度计算精度。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!