基于信源自适应动态选择的高效融合识别方法与流程
【
技术领域:
】本发明属于目标识别
技术领域:
,具体涉及一种基于信源自适应动态选择的高效融合识别方法。
背景技术:
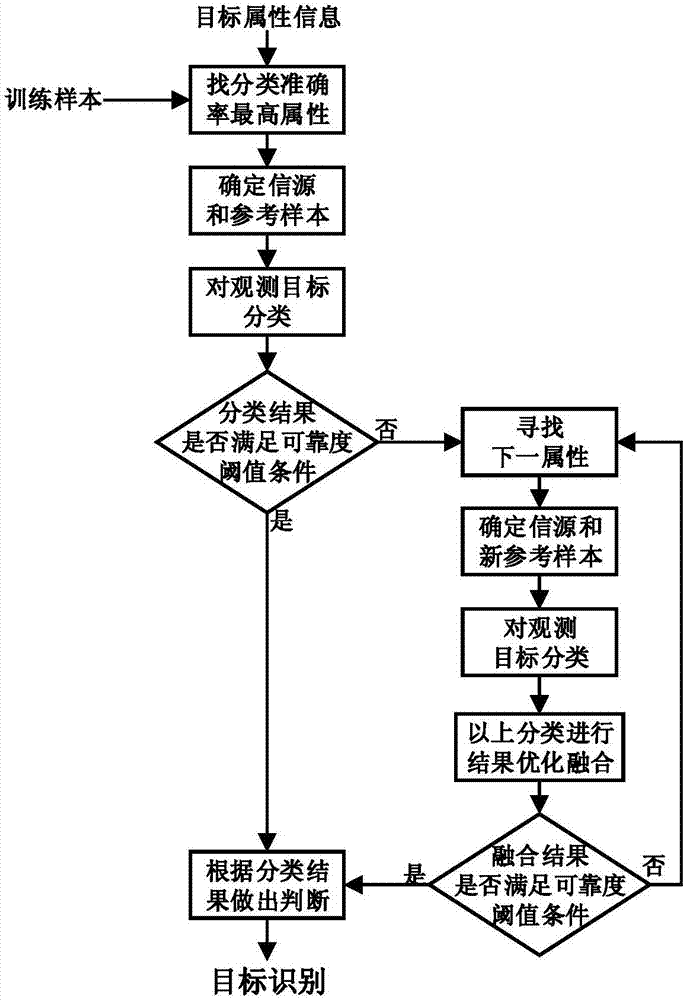
:随着现代科学技术的飞速发展及其在军事领域内日益广泛的应用,传统的作战思想、作战方式已发生根本性的变化。战略预警已成为一个国家安全和战略军事行动的重要保障,是国家战略防御和威慑力量不可缺少的重要基础。目标识别技术是雷达智能化、信息化的重要技术支撑手段。在现代化战争中,目标识别技术在预警探测、精确制导、战场指挥和侦察、敌我识别等军事领域都有广泛的应用前景,已受到了世界各国的关注。在错综复杂的战场环境下,由于外界环境干扰、人为对抗欺骗以及传感器自身性能等诸多因素的影响,信源(传感器获得的目标属性信息)一般具有很大的不确定性和高冲突性。然而在jq多平台多传感器融合识别时,由于每个移动平台(如无人机)携带的燃料(电源)有限,为了延长航时,需要提高传感器观测信息利用效率,在保证识别率的同时要尽量降低冗余或无效传感器观测,也就是要用尽量少的信源来获取尽可能高的识别准确度。并且,在多源信息融合识别系统中,由于各信源间存在数据属性差异,可靠度差异,同时也存在信息冗余,因此并非信源越多,融合识别准确度就越高,相反选择利用部分互补程度高的信源则可得到较高的识别准确率。在此背景下,如何自适应动态选择有效信源信息以获得较高的识别准确率成为一个越来越重要的问题,因此迫切需要研究性能更为优越的融合方法。目前在高层信息融合领域,关于如何自适应动态选择信源信息进行高效融合识别还没有见诸文献报道。技术实现要素:本发明的目的是提供一种基于信源自适应动态选择的高效融合识别方法,以解决信源获取过程中耗费代价太大、鲁棒性差、优化过程的非局部最优的问题。本发明采用以下技术方案:基于信源自适应动态选择的高效融合识别方法,具体包括以下步骤:步骤一、通过多个传感器对训练样本集进行采集数据,并对采集到的数据进行预处理和特征提取,对训练样本集中的每个训练样本,均将其属性划分为n个属性集;步骤二、通过每个属性集对训练样本集进行交叉验证,并得出使训练样本集分类准确率最高的属性集;步骤三、根据步骤二中得出的属性集对目标进行分类,得出分类结果;步骤四、判断分类结果的可靠度是否满足阈值要求:当满足时,按照满足阈值要求的分类结果对目标进行目标识别,方法结束;当不满足时,在剩余的属性集中找到下一属性集,并对目标进行分类,得出新的分类结果;步骤五、将步骤三中得出的分类结果和步骤四中得出的分类结果进行优化融合,并得出融合后的分类结果;步骤六、根据步骤五中得出的融合后的分类结果重复执行步骤四,直至分类结果的可靠度满足阈值要求或所有属性集均被用完为止,当所有属性集均被用完时,使用最终得到的分类结果对目标进行目标识别。进一步地,步骤四中计算分类结果可靠度的方法为:步骤4.1、根据当前分类结果对应的属性集al,在训练样本集中选择与目标y距离最近的k个训练样本作为参考样本,其中al∈{a1,a2,…,an},{a1,a2,…,an}为步骤一中的n个属性集;步骤4.2、根据步骤4.1中的属性集al对目标y进行分类并得到分类结果ml,且对k个参考样本xl,1,xl,2,…,xl,k进行分类,得到分类结果ml,1,ml,2,…,ml,k,xl,k是针对属性集al选出的第k个参考样本;步骤4.3、计算每个参考样本xl,k的重要度αl,k:其中,γl为当属性集选取al时,两两参考样本间的平均距离;dl,k为当属性集选取al时,参考样本xl,k到目标y的欧式距离,且γl、dl,k均通过以下公式得出:式中,z是训练样本集中训练样本的总数,xl,i、xl,j分别为k个参考样本中第i个、第j个训练样本,且有0<i≤k,有0<j≤k;步骤4.4、计算目标y的分类结果对应的可靠度:其中,当每个参考样本的分类结果ml,k与目标y的分类结果ml相同,则δ1(k)=1,否则δ1(k)=0;当每个参考样本的分类结果与目标y的分类结果相同且分类正确,则δ2(k)=1,否则δ2(k)=0。进一步地,当步骤五中融合后的分类结果的可靠度满足阈值要求,且共用了l个属性集时,则目标y融合后的分类结果及其可靠度具体获得方法为:计算目标y的融合后的分类结果对应的可靠度r:其中,当参考样本优化融合后的分类结果mds,k与目标y融合后的分类结果相同,则δ1(k)=1,否则δ1(k)=0;当参考样本优化融合后的分类结果与目标y融合后的分类结果相同且分类正确时,则δ2(k)=1,否则δ2(k)=0;其中,β={β1,…,βl}是权重系数,l=2,…,n,βl为分类结果ml的优化权重,αds,k为优化融合时第k个参考样本的重要度;mds,k表示第k个参考样本优化融合后的分类结果;ml,k表示第l个选出的属性集对应的第k个参考样本的分类结果。进一步地,βl通过以下方法获得:其中,tk为每个参考样本的已知标签则有,进一步地,当第一次选择属性集时,k的取值为20~40。本发明的有益效果是:通过信源自动快速选择方法,有效减少所需信源的数量,节约了成本;通过动态融合识别结果准确度估计方法,既保证了分类效果的准确又增强了算法本身鲁棒性;融合权重通过逐级局部优化来获得,有效避免全局优化对特定目标识别的局限性;本方法在进行融合时对目标属性信息进行有选择的获取,并对分类结果进行可靠度评估,从而降低了信源获取花费又提高了目标识别的鲁棒性能。【附图说明】图1为本发明中动态融合识别结果可靠度估计流程图;图2为本发明中参与融合信源自动选择流程图。【具体实施方式】下面结合附图和具体实施方式对本发明进行详细说明。本发明公开了自适应动态选择信源信息进行高效融合识别方法,结合图1、图2所示,具体包括以下步骤:步骤一、通过多个传感器对训练样本集采集数据,并对采集到的数据进行预处理和特征提取,针对训练样本集中的每个训练样本,均将其属性按相同的规则划分为n个属性集,即{a1,a2,…,an},其中,n为大于0的整数,an表示第n个属性集。步骤二、通过每个属性集对训练样本集进行交叉验证,并得出使训练样本集分类准确率最高的属性集。步骤三、根据步骤二中得出的属性集对观测目标进行分类,得出分类结果。步骤四、判断分类结果的可靠度是否满足阈值要求,阈值为预设值,当计算出的可靠度大于阈值时,认为可靠度满足阈值要求:当满足时,按照满足阈值要求的分类结果对目标进行目标识别;当不满足时,在剩余的属性集中找到下一属性集,并对目标进行分类,得出新的分类结果。可靠度通过动态融合识别结果准确度估计方法计算得出,具体方法如下:步骤4.1、根据当前分类结果对应的属性集al,在训练样本集中选择与目标y距离最近的k个训练样本作为参考样本,其中al∈{a1,a2,…,an},{a1,a2,…,an}为步骤一中的n个属性集;当使用第一次选择的属性集得出的分类结果的可靠度满足阈值要求时,参考样本k的值优选为20~40,当需要使用第二次选择的属性集选择参考样本时,参考样本的数量选择为0.8k,以此类推,当需要使用第l次选择的属性集时,参考样本的数量选择为0.8l-1k。步骤4.2、根据步骤4.1中的属性集al训练分类器,并根据该分类器对目标y进行分类并得到分类结果ml,且对k个参考样本xl,1,xl,2,…,xl,k进行分类,得到分类结果ml,1,ml,2,…,ml,k,xl,k是针对属性集al选出的第k个参考样本;步骤4.3、计算每个参考样本xl,k的重要度αl,k:其中,γl为当属性集选取al时,两两参考样本间的平均距离,dl,k为当属性集选取al时,参考样本xl,k到目标y的欧式距离,dl,k越小,则xl,k越重要,xl,k是针对第l个选出的属性集选出的第k个参考样本,且γl、dl,k均通过以下公式得出:式中,z是训练样本集中训练样本的总数,xl,i、xl,j分别为k个参考样本中第i个、第j个训练样本,且有0<i≤k,有0<j≤k;步骤4.4、计算目标y的分类结果对应的可靠度r:其中,当每个参考样本的分类结果ml,k与目标y的分类结果ml均相同,则δ1(k)=1,否则δ1(k)=0;当每个参考样本的分类结果与目标y的分类结果相同且分类正确,则δ2(k)=1,否则δ2(k)=0。判断得出的可靠度是否满足预设阈值的要求:当满足时,按照满足阈值要求的分类结果对目标进行目标识别;当不满足时,在剩余的属性集中找到下一属性集,并对目标y进行分类,得出新的分类结果;在寻找下一属性集时,对于上面的参考样本,分别计算在其他n-1个属性集对参考样本的分类结果。然后根据分类结果计算参考样本分别在其他n-1个属性上得到总票数,所有参考样本在属性集ag上得票总数记为vg。对于一个属于ωi类的参考样本,vg,k是在属性集ag上得票数目,即支持其属于ωi类的数目。其中,ag就是我们要寻找的下一属性集,同时也要寻找训练样本的新的参考样本(根据该属性集在k个近邻中找到目标的k2=0.8*k1个近邻),并对目标y在该属性集下进行分类。融合后的分类结果的可靠度满足阈值要求,且共用了l个属性集时,则目标y融合后的分类及其可靠度通过如下方法获得:计算目标y的融合后的分类结果对应的可靠度:其中,当参考样本优化融合后的分类结果mds,k与目标y融合后的分类结果相同,则mds,k,否则δ1(k)=0;当参考样本优化融合后的分类结果与目标y融合后的分类结果相同且分类正确时,则δ2(k)=1,否则δ2(k)=0;β={β1,…,βl}是权重系数,l=1,…,l,l=2,…,n,αds,k为优化融合时第k个参考样本的重要度;mds,k表示第k个参考样本优化融合后的分类结果;ml,k表示第l个选出的属性集对应的第k个参考样本的分类结果,βl为分类结果ml的优化权重。分类结果间相互融合的权重,通过对优化函数进行优化来获取,也就是优化出来的参数就是融合时的权重系数,即βl通过以下方法获得,优化函数fun构造如下式:其中,l是信源数目,即使用的属性集的数目,则有,β为包含有优化权重β1,β2,…,βl的向量,由于原始分类标签为1,2,......为了构造优化函数,需要将原始标签重新改为向量的形式,则tk为每个参考样本的已知标签步骤五、将步骤三中得出的分类结果和步骤四中得出的分类结果进行优化融合,并得出融合后的分类结果。步骤六、根据步骤五中得出的融合后的分类结果重复执行步骤四,直至分类结果的可靠度满足阈值要求或所有属性集均被用完为止,当所有属性集均被用完时,使用最终得到的分类结果对目标进行目标识别。针对自适应动态选择信源信息进行高效融合识别方法的有效性,通过用三种不同的分类器(支持向量机,朴素贝叶斯,证据最近邻)和12个数据集对不同方法(平均值法(mv),加权平均法(wds),证据推理(ds),加权证据推理(wds),优化证据推理(owds),提出的新方法(new))进行了对比实验验证。实验数据集的基本信息如表1,实验结果如表2,表3,表4,实验结果包括每种方法所用平均属性数(attributes)和平均正确率(accuracy)。dataclassesattributesinstancesvehicle(veh)418946sonar(so)260208seeds(se)37210vowel(vo)1113990page(pa)5105473satimage(sa)6366435pima(pi)28768movement-libras(ml)1590455wisconsin(wis)29683wdbc(wd)230569whitewinequality(wwq)7114898redwinequality(rwq)6111599表1表2表3表4最后,做出信源探测代价与识别贡献的性价比评估;因为每个信源的获取都是需要付出代价的,这个代价不仅仅是资金意义上的成本代价,它泛指在特定条件下执行任务所需的一切资源。这个特定的条件包括,特殊的任务、有限的能源,有限的时间,有限的资金等等。要想达到这个效果,必须确保所获取的信源的充分有效性,以避免获取太多无用的信源所付出的那部分代价。因此我们必须考虑信源探测代价与对识别贡献的性价比评估。这里定义性价比的评估方法如下:其中,n是传感器总数,也就是实验中的属性集数目,ρ是正确率,n是实际所用的信源数目,ci是获取每个信源的代价,它需要根据具体工程实际来确定,本实施例中默认为其皆相等且为1。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1