一种基于压缩感知的目标识别方法与流程
本发明涉及图像识别技术领域,尤其涉及一种基于压缩感知的目标识别方法。
背景技术:
在图像中进行目标识别是采用各种程序算法将图像中特定的目标区分出来的过程,并且将区分出的目标作为进行下一步处理提供基础,在信息化网络化的今天,可以广泛应用到许多领域。人眼在进行识别某个特定目标时速度往往较慢,并且对于同类目标进行长时间识别划分,也会造成审美疲劳逐渐产生大量错误识别,而采用机器识别代替人眼识别,利用计算机计算量代替人眼的用脑量可以提高速度与降低能耗,对于图像识别领域而言是非常有利的,例如:对一千幅十字路口的视频帧图片进行识别,要求找出通过的车流量,明显采用机器识别远远有利于人眼识别;同样的,若给机器人加上图像目标识别系统,则相当于给机器人添加了“眼睛”,对于发展人工智能技术也是非常有利的。目前本领域技术人员在目标识别方面做出了很多贡献,人们不仅将图像识别技术应用于人脸识别,物品识别等方面,还将其应用在了手写识别等方面,极大地方便了人们的生活。
而目前常用的图像目标识别技术一般缺点是耗时较长、速度较慢,原因是传统图像目标识别技术需要以下流程:图像预处理、图像分割、特征提取和特征识别或匹配;即需要对采样得到的图像信息量进行多次处理才能将所需的目标识别出来,并且现有的图像识别将图像采集过程与目标识别过程分开,不利于速度的提高。
以上背景技术内容的公开仅用于辅助理解本发明的构思及技术方案,其并不必然属于本专利申请的现有技术,在没有明确的证据表明上述内容在本专利申请的申请日已经公开的情况下,上述背景技术不应当用于评价本申请的新颖性和创造性。
技术实现要素:
为解决上述技术问题,本发明提出一种基于压缩感知的目标识别方法,能够提高在图像中目标识别的速度,并可以实现多目标识别。
为了达到上述目的,本发明采用以下技术方案:
本发明公开了一种基于压缩感知的目标识别方法,包括以下步骤:
s1:获取至少两类目标的标准样本图;
s2:根据各类所述目标的标准样本图,采用特征原子提取方法得到各类所述目标的特征原子;
s3:将每类所述目标的各个所述特征原子分别对角排列组成每类所述目标的字典ψp,并将各类所述目标的字典并列排列组成综合的字典ψ;
s4:采用测量矩阵φ对待识别的原始图像x进行压缩采样,得到压缩的采样信号y;
s5:结合综合的字典ψ、测量矩阵φ和采样信号y,通过重构计算得到待识别的所述原始图像的稀疏系数θ;
s6:将稀疏系数θ进行处理得到系数图,根据所述系数图中连通域所处的行数以及大小进行分类识别和计数,以实现对所述原始图像中的各类所述目标的识别。
优选地,步骤s1具体包括:根据图像或视频流中已知存在的至少两类所述目标,提取出各类所述目标的目标图像,将每类所述目标的多个所述目标图像分别进行加权计算得到每类所述目标的标准样本图。
优选地,其中提取出各类所述目标的目标图像具体为:采用图像形态学方法或人工识别分割方法来提取出各类所述目标的目标图像。
优选地,步骤s4还包括将采样信号y作为数据存储在存储器中。
优选地,步骤s5具体包括:根据综合的字典ψ和测量矩阵φ的乘积得到感知矩阵a=φ*ψ,结合采样信号y,通过omp算法的重构计算公式y=a*θ计算得到所述原始图像的稀疏系数θ。
优选地,所述目标识别方法还包括步骤s7:将稀疏系数θ与综合的字典ψ相乘,得到采集的重构图像x1=ψ*θ。
优选地,步骤s2中的特征原子提取方法具体采用mod算法或k-svd算法来提取所述目标的特征原子。
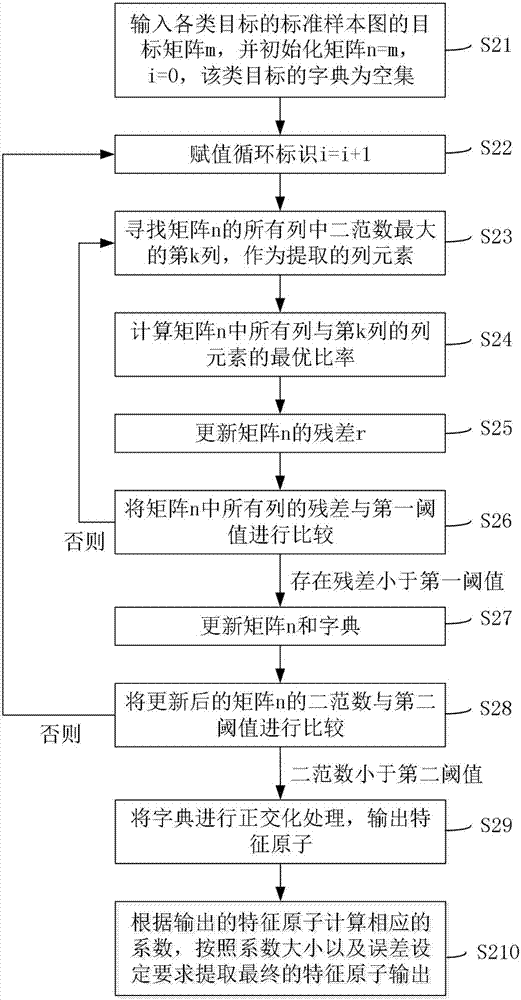
优选地,步骤s2中的特征原子提取方法具体包括:
s21:输入各类所述目标的标准样本图的目标矩阵m,并进行初始化:将矩阵n初始化为n=m,循环标识i=0,初始的所述目标的字典ψp为空集;
s22:赋值循环标识i=i+1;
s23:寻找矩阵n的所有列中二范数最大的第k列,作为提取的列元素λi,其中
s24:计算矩阵n中所有列与第k列的列元素λi的最优比率t,其中
s25:更新矩阵n的残差r,残差r中各列的残差rj的计算公式为rj=nj-λi*tj;
s26:将矩阵n中所有列的残差rj与第一阈值ξ1进行比较,若存在rj<ξ1,执行步骤s27,否则返回步骤s23;
s27:矩阵n更新为n=r,并删除nj,字典ψp更新为ψp=[ψp,λi];
s28:将更新后的矩阵n的二范数与第二阈值ξ2进行比较,若||n||<ξ2,执行步骤s29,否则返回步骤s22;
s29:将字典ψp进行正交化处理,输出特征原子。
优选地,步骤s2中还包括s210:将输出的特征原子结合目标矩阵m进行omp重构计算得到相应的系数,将相应的系数每行计算二范数按照大小排列,按照系数大小以及误差设定要求判断前n行有效,则相应判断提取的特征原子对应的前n列作为最终的特征原子输出。
优选地,步骤s29中正交化处理具体采用史密斯正交化处理;优选地,ξ1≤ξ2。
与现有技术相比,本发明的有益效果在于:本发明的目标识别方法中,首先通过特征原子提取方法得到各类目标的特征原子,将每类目标的各个特征原子分别对角排列组成每类目标的字典,再将各类目标的字典并列排列组成综合的字典,通过将特征原子进行这样的特定排列,结合稀疏系数得到系数图,直接在系数数据中识别计数,即可分门归类地区分出每类目标各有多少个目标,从而可以同时进行多个目标的识别处理;另外相比传统的目标识别方法,无需提取感兴趣区域进行匹配计算来进行分类识别,直接通过设定特定的字典便可获得不同类目标分别处于不同系数区域,即在系数数据中进行识别计数,处理过程简单,计算量小,提高了在图像中目标识别的速度。
在进一步的方案中,在进行目标识别的同时还可并行获得重构图像,并行计算互不影响,将图像采集与目标识别过程合二为一,在图像采集信号中进行目标识别,更进一步提高了在图像中目标识别的速度,并且提高了数据的存储效率与降低硬件的消耗。在更进一步的方案中,结合了压缩感知理论中的有限等距性等原则,针对所需识别目标与背景环境可区分性的特点设计了特定的特征原子提取方法,并通过将特征原子经过合理的组合形成字典,用这个字典与测量矩阵结合计算得到的系数矩阵,可以获得更好的目标识别效果。
附图说明
图1是本发明优选实施例的基于压缩感知的目标识别方法的流程示意图;
图2是本发明优选实施例的特征原子提取方法的流程示意图。
具体实施方式
下面对照附图并结合优选的实施方式对本发明作进一步说明。
如图1所示,本发明的优选实施例公开了一种基于压缩感知的目标识别方法,包括以下步骤:
s1:获取至少两类目标的标准样本图;
根据一些图像或视频流中已知存在的至少两类目标,通过图像心态学方法提取出目标图像,或者人工识别分割出图像中的目标图像;然后将每类目标的多个目标图像分别进行加权计算得到每类目标的标准样本图。
s2:根据各类目标的标准样本图,采用特征原子提取方法得到各类目标的特征原子;
其中特征原子提取方法可以采用mod算法或k-svd算法来提取各类目标的特征原子,更进一步地,特征原子提取方法也可采用后文讲述的方法。
s3:将每类目标的各个特征原子分别对角排列组成每类目标的字典ψp,并将各类目标的字典并列排列组成综合的字典ψ;
s4:采用测量矩阵φ对待识别的原始图像x进行压缩采样,得到压缩的采样信号y,并将采样信号y作为数据存储在存储器中;
s5:结合综合的字典ψ、测量矩阵φ和采样信号y,通过重构计算得到待识别的原始图像的稀疏系数θ;
具体地,根据综合的字典ψ和测量矩阵φ的乘积得到感知矩阵a=φ*ψ,结合采样信号y,通过omp算法的重构计算公式y=a*θ计算得到原始图像的稀疏系数θ。
s6:将稀疏系数θ处理得到系数图,根据系数图中连通域所处的行数以及大小进行分类识别和计数,以实现对原始图像中的各类目标的识别;
具体地,将稀疏系数θ进行滤波二值化等处理得到系数图。
在进一步的实施例中,步骤s5中还包括将原始图像的稀疏系数θ复制一份;步骤s6中为将其中一份的稀疏系数θ进行处理得到系数图;该目标识别方法还包括步骤s7:将另外一份稀疏系数θ与综合的字典ψ相乘,得到采集的重构图像x1=ψ*θ,其中步骤s7与步骤s6可以同时进行。通过步骤s7得到的重构图像与传统nyquist方法采集得到的图像相比不失真,可以替代原始图像进行相关处理。
为了提高目标识别速度与降低图像采集的数据量,本发明采用随机高斯或伯努利测量矩阵进行数据压缩采集,则可收集到相比原始图像较少的数据存储到存储器中,这样在同样的存储量下可以采集多几倍的图像信息;然后,将采集到的信号在需要时从存储器中用omp算法重构出来,由于所选择的字典是自行设计的算法所生成的原子经过特定排列组成的(每类目标的字典中各个特征原子呈对角线排列方式,然后每类目标的字典并列排列组成综合的字典),因此计算得到的稀疏系数稍经处理便分门归类地区分出每类目标各有多少个目标,同时计算得到的稀疏系数直接与所选择的字典相乘便可得到与原始图像质量接近的重构图像,并且获得重构图与归类识别可以进行并行处理互不影响。
在更进一步的实施例中,步骤s2中的的特征原子提取方法具体包括:
s21:输入各类目标的标准样本图的目标矩阵m,并进行初始化:将矩阵n初始化为n=m,循环标识i=0,初始的目标的字典ψp为空集;
s22:赋值循环标识i=i+1,该步骤是记载目标的字典ψp已经包含了多少列;
s23:寻找矩阵n的所有列中二范数最大的第k列,作为提取的列元素λi,其中
s24:计算矩阵n中所有列与第k列的列元素λi的最优比率tj,其中
s25:更新矩阵n的残差r,其中残差r中各列的残差rj的计算公式为rj=nj-λi*tj,该步骤是将矩阵n中所有列删去影响最大的列,使得每列得到的结果最小(二范数);
s26:将矩阵n中所有列的残差rj与第一阈值ξ1进行比较,若存在rj<ξ1,执行步骤s27,否则返回步骤s23;
s27:矩阵n更新为n=r,并删除nj,字典ψp更新为ψp=[ψp,λi];
步骤s26和步骤s27中是通过计算每列删去后的残差与第一阈值作比较,判断是否是影响较大的列,如果是则可作为一个特征原子存在字典ψp中,否则重新挑选。
s28:将更新后的矩阵n的二范数与第二阈值ξ2进行比较,若||n||<ξ2,执行步骤s29,否则返回步骤s22,其中ξ1≤ξ2;
s29:将字典ψp进行正交化处理(可以采用史密斯正交化处理),输出特征原子;
步骤s28和步骤s29是判断是否挑选完所有特征原子,若已经挑选完,则将得到的字典ψp正交作为特征原子输出,否则继续挑选。
s210:将输出的特征原子结合目标矩阵m进行omp重构计算得到相应的系数,将相应的系数每行计算二范数按照大小排列,按照系数大小以及误差设定要求判断前n行有效,则相应判断提取的特征原子对应的前n列作为最终的特征原子输出。
本发明的目标识别方法中,首先通过特征原子提取方法得到各类目标的特征原子,将每类目标的各个特征原子分别对角排列组成每类目标的字典,再将各类目标的字典并列排列组成综合的字典,通过将特征原子进行这样的特定排列,结合稀疏系数得到系数图,直接在系数数据中识别计数,即可分门归类地区分出每类目标各有多少个目标,从而可以同时进行多个目标的识别处理;另外相比传统的目标识别方法,无需提取感兴趣区域进行匹配计算来进行分类识别,直接通过设定特定的字典便可获得不同类目标分别处于不同系数区域,处理过程简单,计算量小,提高了在图像中目标识别的速度。其中本发明还结合了压缩感知理论中的有限等距性等原则,针对所需识别目标与背景环境可区分性的特点设计了特定的特征原子提取方法,并通过将特征原子经过合理的组合形成字典,用这个字典与测量矩阵结合计算得到的系数矩阵,可以获得更好的目标识别效果,并可以同时获得重构质量较好的重构图,识别计数与获得重构图像可以并行计算且互不影响,节约时间。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!