基于正视的人机交互方法与系统与流程
本发明涉及人机交互技术领域,特别是涉及基于正视的人机交互方法与系统。
背景技术:
人机交互是指人与设备之间使用某种对话语言,以一定的交互方式,为完成确定任务的人与设备之间的信息交换过程。
随着科学技术的发展,人机交互技术的应用领域越来越宽广,小如收音机的播放按键,大至飞机上的仪表板、或是发电厂的控制室,用户都可以通过人机交互界面与系统交流,并进行操作。目前在人机交互技术中,主流的人机交互方式主要包括3种,第一种是传统按键方式;第二种是特定语音词激活方式,如:在对话前先说“小冰你好”,设备才识别后面所听到的语音;第三种是“举手发言”,即先用一个特定手势动作来让设备启动语音识别。
上述人机交互方式,虽然在一定程度上可以实现人机交互功能,但是由于交互方式单一,需要预先设定一定特定手势动作,交互过程并不十分自然,在一定程度上给用户操作带来不便。
技术实现要素:
基于此,有必要针对一般人机交互方式单一且不自然给用户带来不便操作的问题,提供一种人机交互方式多样,且交互过程自然,给用户带来便捷操作的基于正视的人机交互方法与系统。
一种基于正视的人机交互方法,包括步骤:
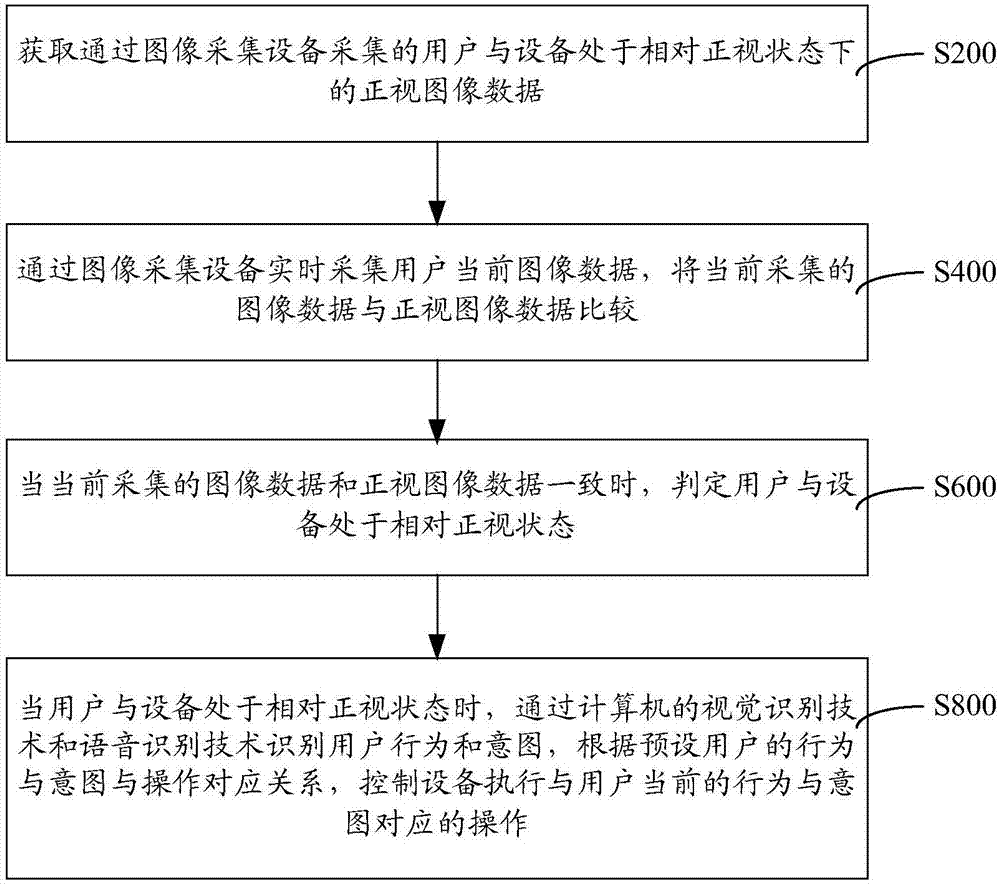
获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据;
通过图像采集设备实时采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较;
当当前采集的图像数据和正视图像数据一致时,判定用户与设备处于相对正视状态;
当用户与设备处于相对正视状态时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作,所述计算机的视觉识别技术和语音识别技术包括人脸识别、语音识别、语义理解、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、人脸跟踪、瞳孔识别以及虹膜识别。
一种基于正视的人机交互系统,包括:
获取模块,用于获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据;
比较模块,用于通过图像采集设备实时采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较;
判定模块,用于当当前采集的图像数据和正视图像数据一致时,判定用户与设备处于相对正视状态;
控制模块,用于当用户与设备处于相对正视状态时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作,所述计算机的视觉识别技术和语音识别技术包括人脸识别、语音识别、语义理解、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、人脸跟踪、瞳孔识别以及虹膜识别。
本发明基于正视的人机交互方法与系统,获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据,采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较,当一致时,判定用户与设备处于相对正视状态,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。整个过程中,基于图像采集设备采集的图像数据进行正视判定,并以用户与设备的正视状态判定作为人机交互前提条件,确保当前用户确实有人机交互需求,整个人机交互过程自然,另外采用包括人脸识别、语音识别、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、瞳孔识别以及虹膜识别的多种动作识别方式识别用户下一步动作,能够实现多样式人机交互,给用户带来便捷操作。
附图说明
图1为本发明基于正视的人机交互方法第一个实施例的流程示意图;
图2为本发明基于正视的人机交互方法第二个实施例的流程示意图;
图3为本发明基于正视的人机交互系统第一个实施例的结构示意图;
图4为本发明基于正视的人机交互方法与系统具体应用场景示意图。
具体实施方式
如图1所示,一种基于正视的人机交互方法,包括步骤:
s200:获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据。
设备具体来说可以为电视机、空调、电脑以及机器人等,另外设备还可以包括车载设备等。用户与设备处于相对正视状态是指用户正视设备,例如当设备为电视机时,用户正视电视机的状态即为用户与电视机处于相对正视状态。由于图像采集设备一般是无法设置于设备正中心的,所以图像采集设备采集用户与设备处于相对正视状态下图像时,从图像采集设备角度看去用户眼睛或用户人脸并不是正对图像采集设备的,一般会呈现一定的角度。为了有利于后续精准判定正视状态,先获取图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据。具体来说,用户与设备处于相对正视状态下的正视图像数据可以是历史记录中采集好的数据,也可以是当场采集的数据。图像采集设备可以是摄像头等设备,在这里,用户与设备处于相对正视状态下的正视图像数据是通过图像采集设备采集的图像采集设备可以设置于设备上,还可以设置设备的辅助设备或外围设备上,例如当设备为电视机时,图像采集设备可以设置于电视,也可以设置于与电视配套的机顶盒上。更具体来说,摄像头拍摄的用户与设备处于相对正视状态下的正视图像数据,进行图像处理和图像目标坐标换算之后即可确定设备和用户人脸相对位置,即可以获取用户与设备处于相对正视状态下用户的人脸图像数据。判定用户与设备处于相对正视状态可以选择采用头部姿态估计(headposeestimation)或者视线跟踪(gazetracking)等技术来实现。
s400:通过图像采集设备实时采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较。
通过步骤s200中相同的图像采集设备实时采集用户当前图像数据,并且将实时采集的图像数据与步骤s200获取的正视图像数据比较,以判断当前用户与设备是否处于相对正视状态。
s600:当当前采集的图像数据和正视图像数据一致时,判定用户与设备处于相对正视状态。
当步骤s200获取的正视图像数据与步骤s400实时采集的图像数据一致时,即表明当前用户与设备处于相对正视状态。
s800:当用户与设备处于相对正视状态时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作,所述计算机的视觉识别技术和语音识别技术包括人脸识别、语音识别、语义理解、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、人脸跟踪、瞳孔识别以及虹膜识别。
用户与设备处于相对正视状态的前提下,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。即只有判定用户与设备处于相对正视状态的前提下,设备才会启动响应用户操作,这样,一方面避免误操作,例如可以避免电视机错误启动、错误切换电视机节目等;另一方面,由于用户与设备处于相对正视状态时,即有极大可能性用户对设备进行操作,给用户带来便利。具体来说,计算机的视觉识别技术和语音识别技术主要可以包括人脸识别、人脸检测、人脸跟踪、语音识别、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、瞳孔识别以及虹膜识别等。采用上述丰富的计算机的视觉识别技术和语音识别技术能够从人脸、语音、瞳孔、手势等方面实现人机交互,更进一步丰富用户生活,给用户带来便捷操作。
本发明基于正视的人机交互方法,获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据,采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较,当一致时,判定用户与设备处于相对正视状态,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。整个过程中,基于图像采集设备采集的图像数据进行正视判定,并以用户与设备的正视状态判定作为人机交互前提条件,确保当前用户确实有人机交互需求,整个人机交互过程自然,另外采用包括人脸识别、语音识别、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、瞳孔识别以及虹膜识别的多种动作识别方式识别用户下一步动作,能够实现多样式人机交互,给用户带来便捷操作。
如图2所示,在其中一个实施例中,步骤s800包括:
s820:对用户与设备处于相对正视状态的时间进行计时。
s840:当用户与设备处于相对正视状态的时间大于预设时间时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。
预设时间是事先设定的好的时间阈值,具体可以根据实际情况的需要进行设定,例如可以设定为2秒、3秒、5秒等。当步骤s600判定用户与设备处于相对正视状态下时,开始对用户与设备处于相对正视状态的时间进行计时,当用户与设备处于相对正视状态的时间大于预设时间时,表明很大概率用户当前需要对显示设定进行下一步操作,此时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作,例如启动设备。可以采用人脸识别、瞳孔识别以及虹膜识别等技术确定用户与设备保持着相对正视状态,即保持正视状态也属于用户动作的一种。非必要的,在启动设备之后,采用人脸识别技术,识别用户身份,查找与用户身份匹配的视频图像数据,控制设备显示查找到的视频图像数据。在实际应用中,当设备为电视机时,计时用户与电视机保持相对正视状态的时间,即计时用户正视电视机屏幕的时间,当用户正视电视机的时间大于预设时间(例如2秒)时,启动电视机,并识别用户身份,查找与当前用户喜好的电视机节目,控制电视机切换至该电视节目播放。
具体来说,在实际应用场景中,上述实施例为:“正视状态”+时间,即用户“正视”电视机达到一定时间,比如2秒钟,可以认为用户想看电视节目,电视机可以从待机开启播放节目;电视机也可以跟用户主动打招呼交流。还可以是:“正视状态”+时间+“人脸识别”,即知道这个用户是谁,可以播放这个用户喜欢的节目;电视机还可以主动呼叫用户,主动跟用户交流。
在其中一个实施例中,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作的步骤包括:
步骤一:对用户进行语音识别和唇语识别。
步骤二:当语音识别结果和唇语识别结果一致时,控制设备响应用户的语音操作。
对设备前处于“正视状态”的用户进行唇语识别,同时对检测到的语音信息进行语音识别。将唇语识别结果与语音识别结果比对,如果结果一致,可以判定该正视状态用户是在跟设备(电视机)对话,控制设备作出相应的响应,如果结果不一致,则设备不响应。
通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作的步骤包括:
步骤一:对所述用户进行语音识别和语义理解。
步骤二:当语音识别结果和语义理解的结果与设备当前场景相符时,控制设备响应所述用户的语音操作。
在本实施例中,还需要对用户进行语音识别和语义理解,理解用户意图,当语音识别结果和语义理解的结果与设备当前场景相符时,控制设备响应所述用户的语音操作。例如用户在看电视时,如果说的话是:“我明天休息”,显然不是操作电视机的,电视机不响应。如果用户说的是“中央一台”,则显然是要切换到中央一台。
在实际应用中,以设备为电视机为例对用户a进行语音识别和唇语识别,即一方面采集用户a发出的语音信息,另一方面基于正视状态,对用户a进行唇语识别,当语音识别和唇语识别结果一致时,判定用户a是在跟电视机交互,控制电视机做出相应的响应,例如切换电视节目,调节电视音量等操作。
在其中一个实施例中,所述当所述当前采集的图像数据和所述正视图像数据一致时,判定用户与设备处于相对正视状态的步骤之前还包括:
步骤一:当侦测到用户时,定位所述用户的面部位置为音源位置;
步骤二:将声音采集设备正对所述音源位置;
所述通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作的步骤包括:
通过所述声音采集设备采集用户声音数据,当采集的用户声音数据中携带有语音操作指令时,提取所述语音操作指令,控制设备执行与所述语音操作指令对应操作。
当侦测到用户时,将用户面部位置定位为声源位置,让声音采集设备正对该声源位置,准备采集用户声音数据。具体来说,这个过程具体可以是基于人脸检测和跟踪技术检测到用户人脸的位置,定位该位置为音源位置。在后续操作中,在判定当前用户与设备处于相对正视状态时,采集用户语音数据,进行语音识别,当采集的用户语音数据中携带有语音操作指令时,提取语音操作指令,控制设备执行与语音操作指令对应操作。另外,侦测用户可以通过人脸检测、人脸跟踪、人体检测等侦测方法侦测,当侦测到人脸位置时,将用户的面部位置设定为声源位置。在实际应用中,声音采集设备可以为阵列麦克风,将阵列麦克风正对音源位置,采集用户语音数据,当采集的用户语音数据中携带有语音操作指令(例如“下一频道”)时,提取语音操作指令,控制设备执行与语音操作指令对应操作。更具体来说,在实际应用场景中,比如有几个人看电视时,几个人都是正视电视,如果几个人同时说话,将来的阵列麦克风(像雷达一样可以跟踪多个目标)可以对多个音源录音。通过人脸检测等方式侦测用户数量和位置,即为目标音源的数量和位置,给阵列麦克风提供目标音源的位置信息,结合人脸身份识别,可以实现同时采集多人的声音,并区分是谁说的内容,当有用户发出的声音数据中携带有“下一频道”的操作指令时,控制电视机切换至下一频道。另外,还可以结合人脸身份识别针对用户身份合法性进行识别,只有合法(拥有控制权的)用户发出的声音数据才会被采集,并进行后续操作。
本发明基于正视的人机交互方法,以正视状态作为后续处理的“开关”,只有判定用户与设备处于相对正视状态,才会进行后续包括开启录音、或者开启语音识别、或开启语音识别结果在内的操作。
另外,在其中一个实施例中,所述当所述当前采集的图像数据和所述正视图像数据一致时,判定用户与设备处于相对正视状态的步骤之后还包括:
步骤一:接收用户输入的操作指令,所述操作指令包括非正视状态操作指令和正视状态操作指令。
步骤二:当侦测到用户不再处于所述正视状态时,响应用户输入的非正视状态操作指令。
步骤三:当侦测到用户再次进入所述正视状态时,响应用户输入的正视状态操作指令。
在实际应用中电视机接收用户输入的操作指令,具体可以是用户通过遥控器或直接触碰按键又或是点击电视机上设置的触摸显示区域输入操作指令,该操作指令分为非正视状态操作指令和正视状态操作指令,当侦测到用户不再处于所述正视状态时,响应用户输入的非正视状态操作指令;当侦测到用户再次进入所述正视状态时,响应用户输入的正视状态操作指令。例如通过语音指令或其它方式,让电视机进入“录背影”状态,人从正视电视机转为侧视,电视机自动开启录像模式,人旋转一圈,再正视电视机时停止录像,并开启视频播放模式,播放刚才所录视频。
在其中一个实施例中,通过图像采集设备实时采集用户当前图像数据的步骤之后还包括:
步骤一:获取用户正视设备时的图像数据。
步骤二:比较用户正视设备时的图像数据和当前采集的图像数据。
步骤三:当用户正视设备时的图像数据和当前采集的图像数据一致时,启动计算机的视觉识别技术和语音识别技术、和/或预设操作。
具体来说,只有当检测到用户正视设备时,才启动预设对应的计算机的视觉识别和语音识别技术功能。检测用户是否正视设备可以采用比较用户正视设备时的图像数据和当前采集的图像数据的方式进行,当一致时,表明当前用户正视设备,启动计算机的视觉识别和语音识别技术功能(例如手势识别、人脸识别以及语音识别等);当不一致时,表明当前用户尚未正视设备,不启动计算机的视觉识别和语音识别技术功能。在实际应用中,以设备为空调为例,通过摄像头实时采集用户当前图像数据,获取用户正视空调时的图像数据;比较用户正视空调时的图像数据和当前采集的图像数据,当两者一致时,表明当前用户正视于空调,启动语音识别技术和人脸识别技术、手势识别技术,语音识别技术用于识别用户语音指令,人脸识别技术用于识别用户身份,手势识别技术用于识别用户手势指令。
如图3所示,一种基于正视的人机交互系统,包括:
获取模块200,用于获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据。
比较模块400,用于通过图像采集设备实时采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较。
判定模块600,用于当当前采集的图像数据和正视图像数据一致时,判定用户与设备处于相对正视状态。
控制模块800,用于当用户与设备处于相对正视状态时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作,计算机的视觉识别技术和语音识别技术包括人脸识别、语音识别、手势识别、唇语识别、声纹识别、表情识别、年龄识别、卡片识别、瞳孔识别以及虹膜识别。
本发明基于正视的人机交互系统,获取模块200获取通过图像采集设备采集的用户与设备处于相对正视状态下的正视图像数据,比较模块400采集用户当前图像数据,将当前采集的图像数据与正视图像数据比较,当一致时,判定模块600判定用户与设备处于相对正视状态,控制模块800通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。整个过程中,基于图像采集设备采集的图像数据进行正视判定,并以用户与设备的正视状态判定作为人机交互前提条件,确保当前用户确实有人机交互需求,整个人机交互过程自然,另外采用包括人脸识别、语音识别、手势识别、唇语识别、瞳孔识别以及虹膜识别的多种动作识别方式识别用户下一步动作,能够实现多样式人机交互,给用户带来便捷操作。
在其中一个实施例中,控制模块800包括:
计时单元,用于对用户与设备处于相对正视状态的时间进行计时,当用户与设备处于相对正视状态的时间大于预设时间时,通过计算机的视觉识别技术和语音识别技术识别用户行为和意图,根据预设用户的行为与意图与操作对应关系,控制设备执行与用户当前的行为与意图对应的操作。
在其中一个实施例中,控制模块800还包括:
查找控制单元,用于查找预设与用户身份匹配的视频图像数据,控制设备显示查找到的视频图像数据。
在其中一个实施例中,控制模块800包括:
识别单元,用于对用户进行语音识别和唇语识别;
控制单元,用于当语音识别结果和唇语识别结果一致时,控制设备响应用户的语音操作。
在其中一个实施例中,控制模块800包括:
定位单元,用于当侦测到用户时,定位用户的面部位置为音源位置;
调节单元,用于将声音采集设备正对音源位置,采集用户声音数据;
提取控制单元,用于当采集的用户声音数据中携带有语音操作指令时,提取语音操作指令,控制设备执行与语音操作指令对应操作。
为了更进一步详细解释本发明基于正视的人机交互方法与系统的技术方案,下面将采用多个具体应用实例,模拟不同实际应用场景,并结合图4进行说明,在下述应用实例中设备均为电视机。
获取通过如图4所示的摄像头采集的用户与电视机处于相对正视状态下的正视图像数据。
通过如图4所示的摄像头实时采集当前图像数据,将实时采集的数据与用户与电视机处于相对正视状态下的正视图像数据比较。
当一致时,判定用户与电视机处于相对正视状态。
应用实例一、正视状态+时间
用户正视电视机达到一定时间,比如2秒钟,可以认为用户想看电视节目,电视机可以从待机开启播放节目,也可以跟用户主动打招呼交流。
应用实例二、正视状态+时间+人脸识别
知道这个用户是谁,可以播放这个用户喜欢的节目;电视机还可以主动呼叫用户,主动跟用户交流。
应用实例三、正视状态+人脸身份识别+表情识别
显然,知道用户是谁,而且知道他的表情,可以主动跟该用户交流,甚至提供相应的服务。如果是一个小孩对着电视机哭,电视机可以自动拨打妈妈的视频电话,电视机上很快就可以出现妈妈的视频,让宝宝跟妈妈视频交流。
应用实例四、正视状态+人脸识别+语音识别
人脸识别确认现场只有一个用户时,电视机可以把语音识别的结果视为该用户对电视机所说,电视机作出相应回复和反馈。
应用实例五、正视状态+人脸识别+唇语识别+语音识别
人脸识别确认现场有多个用户时,判断用户是否“正视状态”,检测“正视”用户的嘴唇变化,对正视用户进行唇语识别;同时对检测到的语音信息进行语音识别。将唇语识别结果与语音识别结果比对,如果结果一致,可以判定该正视用户是在跟电视机对话,电视机作出相应的回应;如果结果不一致,则电视机不回应。
应用实例六、正视状态+阵列麦克风+人脸识别(或者声纹识别)
比如有几个人看电视时,几个人都是正视电视。如果几个人同时说话,将来的阵列麦克风(像雷达一样可以跟踪多个目标)可以对多个音源录音。正视识别可以确定目标有几个,给阵列麦克风提供目标音源的位置信息,结合人脸身份识别,可以实现同时采集多人的声音,并区分是谁说的内容。
应用实例七、应用于空调
用户望着空调,空调管理系统通过头部姿态估计确认用户为“正视”状态,空调启动人脸识别——知道用户是谁,打开并调节到用户喜欢的状态;空调启动手势识别——可以接受用户的手势操作;空调启动录音和语音识别--可以接受用户的语音指令操作。
以上实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!