一种图像深度估计方法和系统与流程
本发明属于计算机视觉领域,更具体地,涉及一种图像深度估计方法和系统。
背景技术:
图像深度估计被广泛应用到智能车避障,机器人控制,汽车辅助驾驶,增强现实等应用领域。道路场景下基于视觉的图像深度估计,利用计算机视觉技术,通过处理摄像头捕捉的图像,获得引导信息。与其他引导技术相比,基于视觉的方法不必增加其他的传感器设施,易于对采集设备进行扩展。随着我国车辆拥有数量的增加和道路状况的日益复杂以及对辅助驾驶功能的更高要求,基于视觉的图像深度估计也被广泛地应用到智能辅助驾驶之中。
目前道路场景下基于计算机视觉的深度估计方法主要分为两种:1)基于双目图像的深度估计方法;2)基于单目图像的深度估计方法。
基于双目图像的道路场景深度估计方法是通过安装在两个不同角度的摄像机对同一个场景从不同的视角拍摄,然后通过两幅图像以及两幅图像之间的基本几何关系恢复场景的三维信息,从而获得场景中每个像素点的深度估计值。在智能辅助驾驶中,利用获得的深度值对前方障碍物进行预警。但是,基于双目图像的道路场景深度估计方法存在大量的问题。如双目摄像机在车辆行驶过程中的自标定问题,双目相机的计算量大问题等。这些问题造成了基于双目相机的道路场景深度估计的不准确和不实用。
基于单目图像的道路场景深度估计方法又可以分为非基于学习的方法和基于学习的方法。非基于学习的方法通常是给定一部分的道路场景图像以及场景图像所对应的深度图像作为参考图像集合,然后根据拍摄的当前帧图像与参考的图像集合中的道路场景图像中的图像匹配结果,获得道路场景的深度信息。方法的计算复杂度非常高,检测图像和参考图像集合中进行匹配的过程一般非常缓慢。并且,方法一般要求参考图像集合中的图像与拍摄的图像具有相似的空间结构,并且需要花费极大的存储空间维护一个数据庞大的参考图像集合。基于学习的道路场景深度估计方法一般是以场景图像以及图像的深度作为输入,学习道路场景图像与深度图像之间的对应关系,获得深度模型。然后利用深度模型对输入的图像中场景深度进行预测,获得场景中目标或者像素的深度信息。当前大部分的基于学习的道路场景图像深度估计方法是通过深度学习的方法进行的。但是,大部分的基于深度学习的深度估计方法是针对单幅图像或者双目图像中的左右立体图像而言的,并且往往需要光流等信息作为辅助进行输入计算,不能直接实现端对端的深度估计计算,同时也造成了深度估计计算不准确等问题。另外一个问题是当前的基于深度学习方法的深度估计是将深度估计问题看作分类问题来处理,采用全连接层,最终得到的结果不能够直接输出与输入图像相同尺度大小的深度图,即得到的结果是非致密的,需要后期进一步的上采样才能够得到最终的输出结果。同时,网络层数过深,使得运算速度非常慢,要实现像素级的深度估计需要大量的运存。
由此可见,现有技术存在精确度低、效率低、且最终得到的深度图是非致密的技术问题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种图像深度估计方法和系统,其目的在于构建深度估计网络,利用训练样本训练深度估计网络,得到训练好的深度估计网络;采集测试图像输入深度估计网络,得到深度图,由此解决现有技术存在精确度低、效率低、且最终得到的深度图是非致密的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种图像深度估计方法,包括:
(1)构建深度估计网络,深度估计网络包括:编码部分、卷积连接部分和解码部分,解码部分的反卷积层与编码部分的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层;
(2)选取样本图像中的两张连续图像和其中一张图像的深度图作为训练样本,利用训练样本训练深度估计网络,得到训练好的深度估计网络;
(3)采集测试图像,提取测试图像的当前帧图像和当前帧图像的前一帧图像;将当前帧图像和前一帧图像的颜色通道输入训练好的深度估计网络,得到当前帧图像的深度图。
进一步的,步骤(1)包括以下子步骤:
(1-1)编码部分由若干层卷积块组成,上一卷积块与下一卷积块之间通过最大池操作连接,每个卷积块中包含若干个卷积层;
(1-2)卷积连接部分包含若干层卷积层,对每层卷积层进行防止过拟合操作;
(1-3)解码部分包含若干层反卷积层,将每层反卷积层与编码部分中的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层;
(1-4)利用编码部分、卷积连接部分和解码部分构建深度估计网络。
进一步的,步骤(2)还包括对训练样本进行预处理,使得训练样本具有泛化性。
进一步的,步骤(3)还包括对当前帧图像和前一帧图像进行直方图均衡化处理。
进一步的,步骤(3)还包括利用高斯滤波对深度图进行平滑处理。
按照本发明的另一方面,提供了一种图像深度估计系统,包括:
构建深度估计网络模块,用于构建深度估计网络,深度估计网络包括:编码部分、卷积连接部分和解码部分,解码部分的反卷积层与编码部分的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层;
训练深度估计网络模块,用于选取样本图像中的两张连续图像和其中一张图像的深度图作为训练样本,利用训练样本训练深度估计网络,得到训练好的深度估计网络;
在线深度估计模块,用于采集测试图像,提取测试图像的当前帧图像和当前帧图像的前一帧图像;将当前帧图像和前一帧图像的颜色通道输入训练好的深度估计网络,得到当前帧图像的深度图。
进一步的,构建深度估计网络模块包括:
构建编码部分子模块,用于构建编码部分,编码部分由若干层卷积块组成,上一卷积块与下一卷积块之间通过最大池操作连接,每个卷积块中包含若干个卷积层;
构建卷积连接部分子模块,用于构建卷积连接部分,卷积连接部分包含若干层卷积层,对每层卷积层进行防止过拟合操作;
构建解码部分子模块,用于构建解码部分,解码部分包含若干层反卷积层,将每层反卷积层与编码部分中的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层;
构建深度估计网络子模块,用于利用编码部分、卷积连接部分和解码部分构建深度估计网络。
进一步的,训练深度估计网络模块还包括对训练样本进行预处理,使得训练样本具有泛化性。
进一步的,在线深度估计模块还包括对当前帧图像和前一帧图像进行直方图均衡化处理。
进一步的,在线深度估计模块还包括利用高斯滤波对深度图进行平滑处理。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明利用深度估计网络实现图像深度的快速估计,并且能够直接得到致密的场景深度图,同时使得构造的深度估计网络具有较小的体积,容易实现在移动端系统中的快速部署,另外,本发明使用连续帧图像作为训练样本,增加了训练样本的信息量,同时加入了编码部分到解码部分之间的跳跃连接,提升了深度图估计的准确性和致密性,且效率高。
(2)将每层反卷积层与编码部分中的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层,实现深度估计网络的全卷积跳跃连接,进而能够实现端对端的致密深度估计,同时减少深度估计网络的参数训练量,缩小深度估计网络参数的存储空间,使得最终的深度图更加准确。
(3)优选的,对训练样本进行预处理,能够有效的解决训练样本数量过少而造成的深度估计网络的欠拟合,增强训练样本的种类和泛化性。
(4)优选的,对当前帧图像和前一帧图像进行直方图均衡化处理,能够提升深度估计网络中输入图像的对比度,提升最终深度估计的效果。
(5)优选的,对最终的深度估计图进行平滑处理,能够有效减少深度估计图中的空洞出现,提升深度估计图中的有效像素数,使深度图中前景目标和背景之间深度值平滑过渡。
附图说明
图1是本发明实施例提供的一种图像深度估计方法的流程图;
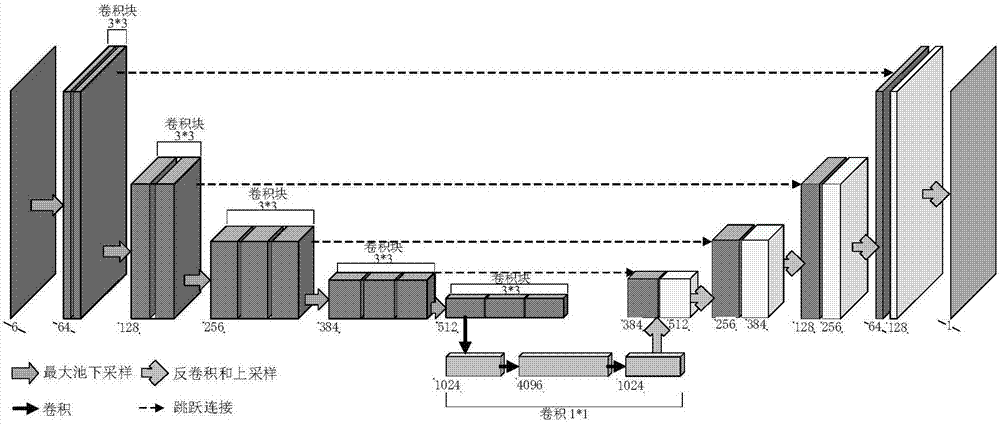
图2是本发明实施例提供的深度估计网络结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,一种图像深度估计方法,包括:
(1)构建深度估计网络,深度估计网络包括:编码部分、卷积连接部分和解码部分,解码部分的反卷积层与编码部分的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层;
(2)选取样本图像中的两张连续图像和其中一张图像的深度图作为训练样本,利用训练样本训练深度估计网络,得到训练好的深度估计网络;
(3)采集测试图像,提取测试图像的当前帧图像和当前帧图像的前一帧图像;将当前帧图像和前一帧图像的颜色通道输入训练好的深度估计网络,得到当前帧图像的深度图。
进一步的,深度估计网络为全卷积跳跃连接的深度学习网络,如图2所示。
进一步的,步骤(1)包括以下子步骤:
(1-1)编码部分由若干层卷积块组成,上一卷积块与下一卷积块之间通过最大池操作连接,通过最大池操作将下一卷积块的尺度下采样为上一卷积块尺度的1/2,优选地,在本发明实施例中卷积块的数量为5个;每个卷积块中包含若干个卷积层,同一个卷积块中的卷积层尺度相同,卷积层中包含的通道数相同,同一个卷积块中的相邻卷积层通过卷积核与上一层卷积层卷积获得,相邻两个卷积层之间不使用最大池操作进行下采样,优选地,本发明中第1个卷积块中包含2层卷积层,每层卷积层中通道数量为64个;第2个卷积块中包含2层卷积层,每层卷积层中通道数量为128个;第3、4、5个卷积块各包含3层卷积层,这三个卷积块中的卷积层中包含的通道数量分别为256个、384个和512个;所有卷积层之间采用的卷积核为3×3大小,层与层之间使用校正线性单元(rectifiedlinearunits,relu)作为激活函数;
(1-2)卷积连接部分包含若干层卷积核为1×1的卷积层,每层卷积层之后跟随防止过拟合(dropout)操作,并使用relu进行激活,优选地,本发明中卷积连接部分中卷积层的数量为3层,每层卷积连接层中包含的通道数量分别为1024个、4096个和1024个;
(1-3)解码部分包含若干层反卷积层,下一反卷积层的尺度为上一反卷积层尺度的2倍;优选地,本发明中反卷积层的数目为4层,1到4层反卷积层中包含的通道数目分别为512、384、256和128;将每层反卷积层与编码部分中的尺度相同的卷积块中的最后一层卷积层相连接,形成最终的反卷积层,优选地,最终反卷积层中,1到4层包含的通道数目分别是896、640、384和192;
(1-4)利用编码部分、卷积连接部分和解码部分构建深度估计网络。
进一步的,深度估计网络中采用的损失函数为l2损失函数,定义为:
其中,y和
进一步的,步骤(2)还包括对训练样本进行预处理,使得训练样本具有泛化性。
进一步的,步骤(2)包括以下子步骤:
(2-1)利用随机函数随机[1,3]内的随机数r;
(2-2)根据随机数r对训练样本进行相应的处理,当r=1时,对训练样本随机旋转同一角度。当r=2时,对训练样本在一定概率条件下进行翻转。当r=3时,对两张连续图像中rgb三个颜色通道分别乘以一个随机数,两张连续图像的同一个颜色通道所乘的随机数相同,深度图保持不变,优选地,对图像进行旋转的角度范围为-5°到5°;图像是否翻转的概率为0.5;图像颜色变化所采用的随机数范围为0.8到1.2之间。
进一步的,步骤(3)还包括对当前帧图像和前一帧图像进行直方图均衡化处理,削弱当前帧图像和前一帧图像中因为光照变化、运动模糊等因素对深度估计的影响。
进一步的,步骤(3)还包括将预先处理后的当前帧图像和前一帧图像合并,将合并后的rgb颜色6个通道输入训练网络,得到当前帧图像所对应的深度图;利用高斯滤波对深度图进行平滑,优选地,高斯滤波的核函数大小为5×5;将平滑后的深度图归一化到[0,255]灰度间间,并输出。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!