一种基于遗传算法改进的多模式污染物集成预报方法与流程
本发明属于气象预报技术领域,尤其是一种基于遗传算法改进的多模式污染物集成预报方法。
背景技术:
随着大气污染问题日益严峻,大气污染物预报已经成为科学研究的重点。目前大气污染预报方法主要分为统计预报和数值预报,统计预报是利用数理统计方法针对大气污染物进行预报。数值预报是根据大气实际情况,在一定条件下用计算机作数值计算进行预测。国内针对大气污染物的预报研究大多采用数值预报模式且已经得到广泛应用。但由于各个数值模式化学参数化方案、动力框架等方面存在差异,使得各个模式在预报能力上存在不同,多模式集成技术正是利用各模式中心预报的结果减少模式系统性的偏差,现已作为大气污染物预报的一个重要发展方向。
迄今为止,人们已经提出许多集成预报方法。陈焕盛等采用多元线性回归方法集成各空气质量模式预报大气污染物浓度,试验结果表明集成预报模式优于单个预报模式。张伟建立了神经网络预报模型,结果表明预报精度相对较高。秦珊珊提出基于人工智能优化神经网络模型,对pm2.5的浓度进行预报。zhangping等用改进的bp人工神经网络并结合地理信息评价pm2.5的预报效果,结果显示当隐含层神经元数量为20时有较高的精度。潘璇等构建遗传算法模型针对气象因素进行预测,预报结果显示平均误差相对较小。sun等通过实验验证了基于svm的空气质量预报模型(pm2.5)能有效应用于大气污染物浓度预测,但在极端情况下预报精度有所下降。
总的来说,多模式集成预报的研究成果多采用线性回归、机器学习等方法进行预报。线性回归模型无法很好地解决非线性问题,而神经网络能较好地解决非线性关系问题,非线性拟合能力较强,但其中bp神经网络算法缺陷是学习速度较慢、训练过程会陷入局部最小及不能确定隐层的神经元个数问题;而遗传算法缺陷是训练时间较长,训练过程中容易出现早熟,不能收敛到最优解问题。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种设计合理、性能稳定且精度高的基于遗传算法改进的多模式污染物集成预报方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种基于遗传算法改进的多模式污染物集成预报方法,包括以下步骤:
步骤1、对原始样本进行数据整理并处理极大、极小及缺失数据;
步骤2、对处理后的样本进行显著性检验,采用偏差、相关性选取单模式;
步骤3、引入遗传算子改进极限学习机;
步骤4:采用极限学习机改进遗传算法进行大气污染物集成优化预报。
进一步,所述步骤1的具体方法为:在分季节预报基础上找到预报时刻最近30天的历史数据作为训练样本,使得待集成数据所对应训练样本均为滚动更新,每个样本的实况值为网络训练的输出,输出层神经元为1。
进一步,所述步骤2的具体方法为:针对不同季节分别进行单模式的选取,所用方法在满足显著性检验基础上,针对不同模式以及实况值通过相对偏差sd和相关系数r进行筛选,计算公式如下:
式中,cp为模式模拟值,co为观测值,
进一步,所述步骤3的具体方法为:设问题有n维决策变量,则输入节点为n+2,种群适应度为adapt,随机数为random,父代种群为
进一步,所述步骤4的具体方法为:
首先,随机生成单模式权重并用实数编码组成染色体,形成初始种群;
然后,子种群一部分由遗传算法通过最优保留选择方式、选择算术交叉方式、动态变异方式的遗传三算子操作生成下一代种群;子种群另一部分由已经训练好的极限学习机进化机制来生成下一代种群;两种机制根据计算得到的种群适应度adapt的优劣来判断下一代子种群的分配比例,具体定义规则如下:
设问题有n维决策变量,输入节点为n+2,种群适应度为adapt,随机数为random,父代种群为
其中,i为集成预报成员模式;t为预报时间点;m为成员个数;n为一次预报时间点数目;e为集成结果与实际数据的均方误差;wi,t为第i个成员模式在第t个时间点上的权重系数;ri,t为该污染物第i个成员模式在第t个时间点的预报值;ri,t为第i个模式在预报时间点t的实况值;
根据两种方法适应度对子种群分配比例p进行调整,两种算法的适应度分别为adapt1和adapt2,子种群分配比例p的计算公式如下:
在本步骤中,迭代终止条件为均方根误差达到平衡,迭代到最优解不再发生变化即终止迭代。
本发明的优点和积极效果是:
本发明采用多种单模式预报作为算法输入层,引入遗传算子改进极限学习机训练模型,利用改进极限学习机优秀的非线性映射能力改进遗传算法迭代速度慢,容易早熟的缺点;随后,利用训练好的模型改进遗传算法迭代策略,在不断迭代过程中改进子代种群的搜索方向,加快搜索速度,达到精度高、收敛快的效果,可以较好发挥大气污染物预报作用,其作为一种非线性、多模式的集成方法,不仅具有最优的预报精度,而且有效降低了遗传算法的迭代次数,缩短了时间成本。本发明在污染物浓度预报,包括温度预报,降水预报,雾霾分析预报等领域,都具有较好的应用价值。
附图说明
图1为本发明的实现流程图;
图2为本发明在实验中涉及到co冬季各单模式方案筛选对比图;
图3为本发明在实验中涉及到co夏季各单模式方案筛选对比图;
图4为六种大气污染物采用本发明方法及对比单模式和其他集成算法时的均方根误差对比图;
图5为三种大气污染物冬季、春季单月污染物浓度实况值与本发明及其他集成算法的预报值对比图;
图6为另三种大气污染物冬季、春季单月污染物浓度实况值与本发明及其他集成算法的预报值对比图。
具体实施方式
以下结合附图对本发明实施例做进一步详述:
本发明的设计原理为:采用多种单模式预报作为算法输入层,引入遗传算子改进极限学习机训练模型,利用改进极限学习机优秀的非线性映射能力改进遗传算法迭代速度慢,容易早熟的缺点;随后,利用训练好的模型改进遗传算法迭代策略,在不断迭代过程中改进子代种群的搜索方向,加快搜索速度,达到精度高、收敛快的效果。以下是两种算法概述:
遗传算法作为一种全局优化算法,遗传算法即通过对染色体上的基因进行操作从而寻找优良的染色体作为最优解的问题。基本原理是取n维向量x=[x1,x2,...,xn]表示成由xi(i=1,2,...,n)所组成的符号串,符号串中每一个xi看作成一个遗传基因,则x作为由n个遗传基因所组成的染色体链,多个染色体构成的种群叫做初始种群。将假设的染色体置于问题中,首先设定目标函数对每个个体进行评价,给出适应度以评判染色体的优劣程度。按照适者生存的原则,选出适应度较高的个体进行复制、交叉以及变异,产生适应度更好的新一代种群,个体x适应度越大,越趋近于最优解。随后,根据适应度选取一定的个体作为下一代种群继续进化,如此进行多次后,算法收敛于最好的染色体。
elm(extremelearningmachine)是一种新型神经网络算法。主要为克服传统的前馈神经网络算法学习步长难确定、迭代次数多、容易陷入局部最优的缺点。elm网络机构及工作原理是:给定训练样本集和隐层神经元数l,其中xi=[xi1,xi2,...,xin]t∈rn,即为样本的输入值,ti=[ti1,ti2,...,tin]t∈rn,即为样本的期望输出值。存在ai,bi,βi使得:
其中,a=[ai1,ai2,...,ain]为输入层与隐藏层间第i个节点的连接权值;βi=[βi1,βi2,...,βin]t为隐藏层第i个节点与输出层的连接权值;g(aixj+bi)为第i个隐层神经元的输出,g(·)为神经元激活函数。还可以表示为hβ=y,h即为神经网络的隐含层输出矩阵,具体形为:
通过实验研究发现,若给定任意不同的样本(xi,ti)、任意小误差ε(ε>0)和一个任意区间无限可微的激活函数g,则总存在一个含有k(k≤n)个隐含层神经元的单隐层前馈神经网络,在随机赋值初始权重和偏置的情况下,有||hn×mβm×n-t||<ε,隐藏节点数可在开始指定,且在训练中保持不变。因此,当激活函数g(xi)无限可微时,隐含层与输出层间的连接权值通过求解以下的最小二乘值获得。
h+为隐含层输出矩阵h的广义逆。
根据上述原理,本发明基于遗传算法改进的多模式污染物集成预报方法,如图1所示,包括以下步骤:
步骤1、预处理:对原始样本进行数据整理,保证数据有效性并简化运算。
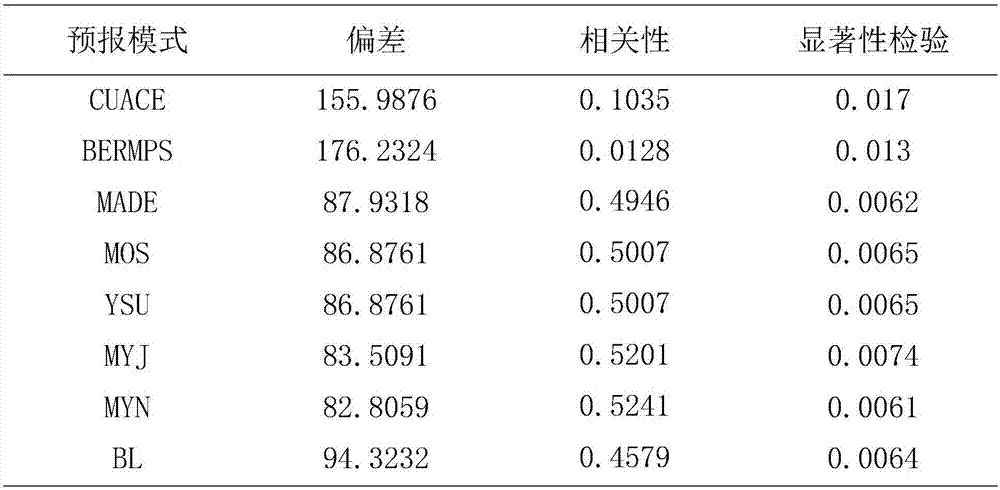
如针对大气污染物,将国家气象局模式cuace、北京市气象局模式bremps、欧洲气溶胶动力模式made(modelaerosoldynamicsmodelforeurope)、wrf-chem模式的局地三种边界层方案myj、myn3和bl以及非局地边界层方案ysu的天津区域自动气象站点资料进行整理,取出2015年六种大气污染物(no2,o3,pm2.5,pm10,co,so2)浓度数据,整理并处理极大、极小及缺失数据。在本实施例中,模式预报会随季节变化呈现一定规律,过多选取样本会造成计算量大且描述预报规律不准确,导致过拟合。最佳方案是在分季节预报基础上找到预报时刻最近30d的历史数据作为训练样本,即待集成数据所对应训练样本均为滚动更新,每个样本的实况值为网络训练的输出,所以输出层神经元为1。注意模型训练之前要对数据进行归一化处理。
步骤2、模式选取:对处理后的样本进行显著性检验,用偏差、相关性选取单模式。
在本步骤中,模式选取具体包括以下步骤:采用集成多个单一预报模式的方法,针对春(3月-5月)夏(6月-8月)秋(9月-11月)冬(12月-2月)4个季节分别进行单模式的选取。所用方法在满足显著性检验基础上,针对8种不同模式以及实况值通过相对偏差(standarddeviation,sd)和相关系数(correlationcoefficient,r)进行筛选,其中,cp为模式模拟值,co为观测值,
步骤3、引入遗传算子改进极限学习机(elm):在极限学习机算法的设计中引入种群适应度值来模拟选择算子优胜略汰的特点,引入随机数来体现随机变异的特点改进输出权重准确度。
在本步骤中,利用elm良好的映射能力来刻画遗传算法中父代和子代之间的复杂非线性关系,具体过程为:引入种群适应度值来模拟选择算子优胜略汰的特点,引入随机数来体现随机变异的特点。设问题有n维决策变量,则输入节点为n+2:种群适应度adapt、随机数random、父代种群
训练样本的构建是引入遗传算子的elm进化机制的关键,其中父代作为elm进化机制的输入,而子代作为输出。引入的种群进化代数evolution,映射出父代种群和子代种群的复杂非线性关系,获得更好搜索方向和搜索范围。evolution的选择会影响种群收敛速度,种群进化代数太少,进化速度不快;进化代数太多,训练后的进化机制搜索方向时效性变差。为此,evolution的选择通过实验仿真选取,且选取多代父种群和子种群以扩大训练样本,避免初始阶段进化不显著的缺点。
步骤4、极限学习机改进遗传算法:使遗传算法生成第一代子种群,子种群一部分由遗传算法生成下一代种群;另一部分由已经训练好的极限学习机进化机制来生成下一代种群,从而得到更优的搜索方向和搜索范围。通过获得更好的搜索方向减少迭代时间并获得最优预报值。
在本步骤中,采取elm结合改进遗传算法,表示为:首先随机生成单模式权重并用实数编码组成染色体,形成初始种群。随后,子种群一部分由遗传算法通过最优保留选择方式、选择算术交叉方式、动态变异方式的遗传三算子操作生成下一代种群;另一部分由已经训练好的elm进化机制来生成下一代种群。两种机制根据计算得到的种群适应度adapt的优劣来判断下一代子种群的分配比例,具体定义规则如下:
假设设问题有n维决策变量,则输入节点为n+2:种群适应度adapt、随机数random、父代种群
其中,i为集成预报成员模式;t为预报时间点;m为成员个数;n为一次预报时间点数目;e为集成结果与实际数据的均方误差;wi,t为第i个成员模式在第t个时间点上的权重系数;ri,t为该污染物第i个成员模式在第t个时间点的预报值;ri,t为第i个模式在预报时间点t的实况值;根据两种方法适应度对子种群分配比例进行调整,两种算法的适应度adapt1,adapt2,公式如下:
在本步骤中,迭代终止条件为均方根误差达到平衡,迭代到最优解不再发生变化即终止迭代。
本发明对于每种大气污染物精度预报均有提高:一氧化碳均方根误差降低到0.46mg/m3,平均绝对误差值降低到0.35mg/m3;二氧化氮均方根误差降低到12.60mg/m3,平均绝对误差值降低到9.36mg/m3;臭氧均方根误差降低到17.25mg/m3,平均绝对误差值降低到11.7mg/m3;pm2.5均方根误差降低到30.21mg/m3,平均绝对误差值降低到23.8mg/m3;pm10均方根误差降低到60.50mg/m3,平均绝对误差值降低到38.9mg/m3;so2均方根误差降低到10.75mg/m3,平均绝对误差值降低到7.76mg/m3。在算法的执行时间上,改进算法与遗传算法相比,30天滚动的分季节遗传算法在四个季节中平均用时614.98s,引入遗传算子的elm改进遗传算法集成预报用时281.79s。后者的执行时间明显更快。其中迭代总数500次中遗传算法平均收敛次数为381次,引入遗传算子的elm改进遗传算法网络为247次。因此,本文算法可以满足气象预报中高时效性的要求,能在尽可能短的时间内提供准确性高的预报结果。
实验首先对八种单模式进行选取。模式的选取采用各模式与实况值的显著性分析检验,显示p-value大于0.01,小于0.05,表示差异显著;p-value小于0.01,差异极显著。针对显著的模式方案进行相关性r以及偏差t分析,相关性r采用统一标准:取绝对值后0<r<0.09为没有相关性,0.1<r<0.3为相关,0.3<r<0.5为低度相关,0.5<r<0.8为中度相关,r≥0.8为高度相关。在相关性评价基础上,偏差不宜过大。图2和图3为以co为例的各单模式方案在冬季和夏季的筛选对比图。
图4给出了全年天津站点6种大气污染物均方根误差的3种典型单模式以及svm算法、bp算法、遗传算法与改进算法的预报结果对比图,按照春夏秋冬四个季节进行预报,由图可知:相较于三种单模式,四种集成模式均展现出了较好的均方根误差能力,而引入遗传算子的elm改进遗传算法模式又比其他三种集成模式更优秀。改进算法的co较单模式和集成算法均方根误差降低0.05~0.40mg/m3,平均绝对误差值降低0.02~0.34mg/m3;no2均方根误差降低1.88~15.32mg/m3,平均绝对误差值降低0.93~16.11mg/m3;o3均方根误差降低5.72~21.67mg/m3,平均绝对误差值降低0.13~16.85mg/m3;pm10均方根误差降低3.20~21.80mg/m3,平均绝对误差值降低0.69~6.86mg/m3;pm2.5均方根误差降低3.03~20.06mg/m3,平均绝对误差值降低0.07~9.08mg/m3;so2均方根误差降低7.33~17.71mg/m3,平均绝对误差值降低0.17~9.24mg/m3。其中冬季预报结果最优,其次是秋季、春季,预报效果最不稳定的是夏季。这与参与集成的多个模式各有优劣且夏天受温度、风力等气象因素影响较大相关,导致预报结果rmse的增长。
图4显示出集成模式预报效果普遍高于单模式且冬季和夏季分别是预报效果最好和最不稳定的季节,图5、图6采用6种大气污染物的svm算法集成模式、bp算法集成模式、遗传算法集成模式、引入遗传算子的elm改进遗传算法集成模式与实况值的预报结果进行对比分析,选取2015年预报效果最好的冬季单月以及预报较不稳定的夏季单月。由图5、图6可知:(1)在预报效果最好的冬季,4种集成方法均有良好的精度,但从细节上可以看出改进算法整体上更加贴近实况值。(2)预报效果最不稳定的夏季,bp算法和遗传算法因存在收敛不到最优解,整体预报不稳定的缺点,预测曲线与实况值有一定偏差。改进算法集成预报利用elm改进搜索方向,加快收敛速度,较其它三种集成方法明显更加贴近实况值且稳定,而svm虽然有少量预报结果比较贴近实况值,但整体上改进算法精度更好。
综上所述,本发明将过程划分为读取单模式大气污染物浓度数据及预处理、模式选取、引入遗传算子改进极限学习机、极限学习机改进遗传算法四个阶段,且考虑了季节性影响且设置30天动态滚动数据集。其中,与遗传算法集成模型相比,改进算法预测模型改进elm算法输入并模拟遗传算子操作,运用改进的elm算法与遗传算法相结合,具有收敛速度快,不易陷入局部最小的特点,可以较好发挥大气污染物预报作用;从4个季节的预报效果看,各单数值模式在不同季节中会展现出不同的预报效果,采用选出的数值模式进行集成预报均方根误差较各个单模式预报有很大的改进,且引入遗传算子的elm改进遗传算法的集成方法均方根误差较神经网络、svm集成预报更小。其中冬季预报结果最优,其次是秋季、春季、夏季;从单季节的每天预报效果看,在预报精度较不稳定的夏天,引入遗传算子的elm改进遗传算法展现了较神经网络、svm集成算法更好的预报精度和整体稳定度。实验证明,遗传算法改进的多模式污染物集成预报方法不仅具有最优的预报精度,而且有效降低了遗传算法的迭代次数,从而缩短了时间成本,本发明是对遗传方法的一种有效改进。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!