基于银行核心系统的数据处理方法与流程
本发明涉及金融系统领域,尤其涉及银行核心系统的在线、近线、离线数据的清理和查询处理。
背景技术:
银行核心系统,英文名称:corebankingsystem。银行核心系统指金融行业的银行核心业务系统。现有的银行核心系统,都是以客户为中心,进行帐务处理、满足综合柜员制、并提供24小时服务的核心银行业务系统。银行核心系统按照服务对象的不同,可分为二大类:第一类,服务对象为银行客户,提供的服务包括存款、贷款、结算、代理等;第二类,服务对象为银行自己,提供的服务包括网点/柜员管理、总账、内部账、现金、凭证、报表等。
无论哪一类银行核心系统,为了确保银行核心系统的生产环境(生产表)保持一个轻量化的状态运作,通常会对生产环境的在线数据做定时清理,但是目前的清理方式存在着以下问题:清理策略配置化程度低;清理方案部署落地复杂;近线和离线数据无法合理利用;以及多数据源运维困难等问题。
技术实现要素:
因此,针对上述的问题,本发明提出一种快速、高效的银行核心系统的数据处理方法,对现有的银行核心系统的清理方案进行改进,解决现有技术之不足。
为了达到上述目的,本发明所采用的技术方案是,一种基于银行核心系统的数据处理方法,包括:
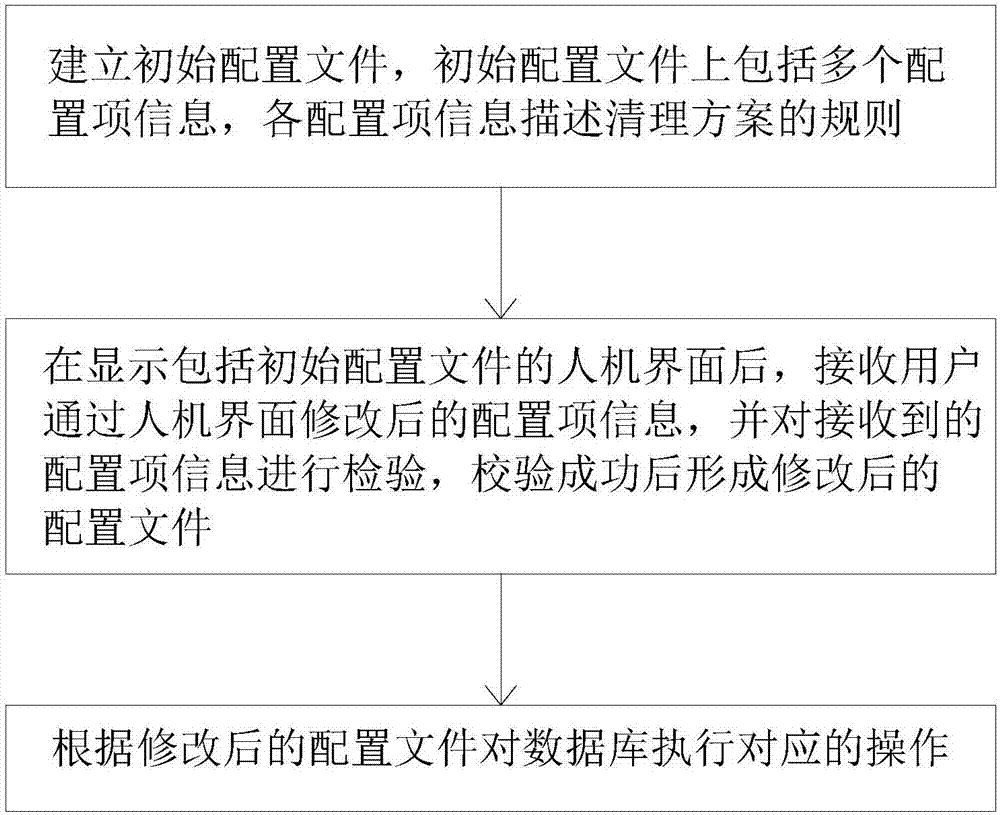
建立初始配置文件,初始配置文件上包括多个配置项信息,各配置项信息描述清理方案的规则;其中,配置文件可以是数据库表单也可以是预加载文件(excel格式文件、ini格式文件、shell脚本文件均可),本发明中,配置项信息优选配置在数据库表中,相对于配置在其他文件中,一来便于管理,二来便于实时生效;
在显示包括初始配置文件的人机界面后,接收用户通过人机界面修改后的配置项信息,并对接收到的配置项信息进行检验,校验成功后形成修改后的配置文件;
根据修改后的配置文件对数据库执行对应的操作。所述数据库包括生产库和历史库,生产库包括生产表和历史表,历史库包括历史表。
优选的,所述配置项信息至少包括:
生产保留时长,用以标识生产库生产表中的数据保留时间段;
近线保留时长,用以标识生产库历史表中的数据保留时间段;
生产清理频率,用以标识间隔多久清理一次生产库生产表;
近线清理频率,用以标识间隔多久清理一次生产库历史表;
数据清理方式,用以标识当前表记录的清理方式;
清理关键字,用以标识当前表记录按哪个关键字清理。
其中,所述清理方案包括在同一数据库同一区下执行数据交换操作的同库事务方式,用于在同一数据库不同区下执行数据交换操作的同库分区事务方式,用于在同一服务器上不同数据库之间执行跨库数据处理的本机跨库数据泵方式,以及用于在不同服务器上不同数据库之间执行跨库数据处理的跨物理机跨库数据泵方式。
其中的同库事务方式包括:i.根据配置项信息中的数据清理方式获取被清理表的清理关键字;ii.根据配置项信息中的生产保留时长计算清理关键字范围,由该清理关键字范围查询生产表,得到生产表的指定范围数据;iii.使用同一事务将生产表的指定范围数据迁移至历史表,同时删除生产表的指定范围数据。
同库分区事务方式包括:i.根据配置项信息中的数据清理方式获取被清理表的生产保留时长和生产清理频率;ii.根据生产保留时长和生产清理频率计算分区名称,由分区名称得到生产表的指定分区;iii.使用分区交换的方式将生产表的指定分区的数据迁移至历史表的指定分区;iv.重建历史表的指定分区的索引;v.删除生产表的指定分区。
其中的本机跨库数据泵方式又可分为三种操作方案:1、将生产库生产表传输至历史库的数据处理操作;2、将生产库历史表传输至历史库,历史表采用同库事务方式的数据处理操作;3、将生产库历史表传输至历史库,历史表采用同库分区交换方式的数据处理操作。
其中,所述本机跨库数据泵方式(生产库生产表至历史库)包括:
i.根据配置项信息中的数据清理方式获取被清理表的生产保留时长和生产清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称,由分区名称得到生产库指定分区;
iii.获取数据库的转储文件目录;
iv.获取配置文件中的数据源信息;
v.将生产库指定分区的数据导出为转储文件;
vi.将转储文件导入至历史库指定分区;
vii.删除生产库指定分区。
所述本机跨库数据泵方式(生产库历史表至历史库,历史表采用同库事务方式)包括:
i.根据配置项信息中的数据清理方式获取被清理表的清理关键字、生产保留时长和近线保留时长;
ii.根据生产保留时长计算清理关键字范围,由该清理关键字范围获得生产表指定范围数据;
iii.使用同一事务将生产表指定范围数据迁移至历史表,并删除生产表指定范围数据;
iv.根据近线保留时长计算清理关键字范围,由该清理关键字范围获得生产库历史表指定范围;
v.获取数据库的转储文件目录;
vi.获取配置文件中的数据源信息;
vii.将生产库历史表指定范围数据导出为转储文件;
viii.将转储文件导入至历史库;
ix.校验第vii、viii步骤的操作是否成功,如果成功则删除历史表指定范围数据。
所述本机跨库数据泵方式(生产库历史表至历史库,历史表采用同库分区交换方式)包括:
i.根据配置项信息中的数据清理方式获取被清理表的生产保留时长、生产清理频率、近线保留时长和近线清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称,由分区名称获得生产表指定分区的数据;
iii.使用分区交换的方式将生产表指定分区的数据迁移至历史表指定分区;
iv.重建历史表指定分区的索引;
v.删除生产表指定分区的数据;
vi.根据近线保留时长和近线清理频率计算分区名称,由近线保留时长和近线清理频率获得历史表指定分区的数据;
vii.获取数据库的转储文件目录;
viii.获取配置文件中的数据源信息;
ix.将历史表指定分区的数据导出为转储文件;
x.将转储文件导入至历史库指定分区;
xi.删除历史表指定分区的数据。
其中的跨物理机跨库数据泵方式又可分为三种操作方案:1、将生产库生产表采用文件传输的方式传输至历史库的数据处理操作;2、将生产库历史表采用文件传输的方式传输至历史库,历史表采用同库事务方式的数据处理操作;3、将生产库历史表采用文件传输的方式传输至历史库,历史表采用同库分区交换方式的数据处理操作。
所述跨物理机跨库数据泵方式(生产库生产表至历史库)包括:
i.据配置项信息中的数据清理方式获取被清理表的生产保留时长和生产清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称,由分区名称获得生产库指定分区的数据;
iii.获取数据库的转储文件目录;
iv.获取配置文件中的数据源信息;
v.将生产库指定分区的数据导出为转储文件;
vi.将转储文件从生产库服务器传输(ftp)至历史库服务器;
vii.将转储文件导入至转储文件目录的历史库指定分区;
viii.删除生产库指定分区的数据。
所述跨物理机跨库数据泵方式(生产库历史表至历史库,历史表采用同库事务方式)包括:
i.据配置项信息中的数据清理方式获取被清理表的清理关键字、生产保留时长和近线保留时长;
ii.根据生产保留时长计算清理关键字范围,由清理关键字范围获得生产表指定范围数据;
iii.使用同一事务将生产表指定范围数据迁移至历史表并删除生产表指定范围数据;
iv.根据近线保留时长计算清理关键字范围,由该清理关键字范围得到生产库历史表指定范围的数据;
v.获取数据库的转储文件目录;
vi.获取配置文件中的数据源信息;
vii.将生产库历史表指定范围的数据导出为转储文件;
viii.将转储文件从生产库服务器传输(ftp)至历史库服务器;
ix.将转储文件导入至转储文件目录的历史库;
x.如果第viii和ix步骤成功,则删除历史表指定范围数据。
所述跨物理机跨库数据泵方式(生产库历史表至历史库历史表采用同库分区交换方式)包括:
i.据配置项信息中的数据清理方式获取被清理表的生产保留时长、生产清理频率、近线保留时长和近线清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称,由分区名称获得生产表指定分区的数据;
iii.使用分区交换的方式将生产表指定分区的数据迁移至历史表指定分区;
iv.重建历史表指定分区的索引;
v.删除生产表指定分区;
vi.根据近线保留时长和近线清理频率计算分区名称,由该分区名称获取历史表指定分区的数据;
vii.获取数据库的转储文件目录;
viii.获取配置文件中的数据源信息;
ix.将历史表指定分区的数据导出为转储文件;
x.将转储文件从生产库服务器传输(ftp)至转储文件目录的历史库服务器;
xi.将转储文件导入至历史库指定分区;
xii.删除历史表指定分区的数据。
作为一个进一步的方案,所述配置项信息还描述历史查询方案的规则。
所述历史查询方案包括:数据路由处理步骤和结果拼接步骤;
其中,数据路由处理步骤包括:通过查询数据清理转移表返回生产库与历史库的日期界限,以及传入的起止日期,规定如下:
起始日期大于等于生产库与历史库的日期界限值,则路由到生产库单数据源;
终止日期小于生产库与历史库的日期界限值,则路由到历史库单数据源;
否则,先路由到生产库数据源,再路由到历史库数据源;
同时生成dao类逻辑;
结果拼接步骤包括:新增命名sql对应的历史查询方法;业务程序如果是历史查询,则需要调用历史查询方法;其中,历史查询方法通过双库遍历方式完成历史数据查询,并开放回调类,用以提供历史库与生产库的数据界线。
本发明针对清理策略提供了简捷全面的配置项,确保清理方式完全自定义;清理方案通过web方式由自主设计的人机界面进行部署;配套的历史查询方案将在线、近线、离线数据有机结合,在不影响生产效率的条件下,为数据的充分利用提供了渠道。分布式部署架构下,可以通过dbagentor的方式在不用数据源上使用不同策略对数据进行管理。
附图说明
图1为使用本发明完成银行核心系统数据管理的多数据源运维流程图;
图2为本发明的基于银行核心系统的数据处理方法的流程图;
图3为使用本发明完成银行核心系统的历史数据查询的流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
本发明针对现有的清理策略进行改进,通过提供简捷全面的配置项,确保清理方式完全自定义,可广泛适用不同客户的各种需求;清理方案通过自主搭建的web平台以人机交互的方式部署;配套有历史查询方案,可对在线、近线、离线数据进行有机结合,在不影响生产效率的条件下,为数据的充分利用提供了渠道。
另外,分布式部署架构下,可以通过dbagentor的方式在不用数据源上使用不同策略对数据进行管理。图1为本发明的完成银行核心系统数据管理的多数据源运维流程图,首先搭建web平台,web平台设置有批处理页面,用户通过采用人机交互的方式在批处理页面上执行抽象组件配置操作,后台的处理程序接收用户的配置项信息,校验成功后形成配置文件,然后根据该配置文件对数据库进行操作。对数据库的操作,可以是同一数据库内的数据操作,也可以是同一服务器上的不同数据库的操作,还可以是不同服务器上的不同数据库的操作。
具体的,参见图2,本发明的一种银行核心系统的数据处理方法,包括:
建立初始配置文件,初始配置文件上包括多个配置项信息,各配置项信息描述清理方案的规则以及历史查询方案的规则;在显示包括初始配置文件的人机界面后,接收用户通过人机界面修改后的配置项信息,并对接收到的配置项信息进行检验,校验成功后形成修改后的配置文件;根据修改后的配置文件对数据库执行对应的清理操作或者历史查询操作。其中的数据库包括生产库和历史库,生产库包括生产表和历史表,历史库包括历史表。生产库和历史库可以在同一服务器上,也可在不同的服务器上。
其中,配置项信息至少包括,生产保留时长、近线保留时长、生产清理频率、近线清理频率、数据清理方式以及清理关键字。其中,生产保留时长用以标识生产库生产表中的数据保留时间段;近线保留时长用以标识生产库历史表中的数据保留时间段;生产清理频率用以标识间隔多久清理一次生产库生产表;近线清理频率用以标识间隔多久清理一次生产库历史表;数据清理方式用以标识当前表记录的清理方式;清理关键字用以标识当前表记录按哪个关键字清理。
上述清理方案包括在同一数据库同一区下执行数据交换操作的同库事务方式,用于在同一数据库不同区下执行数据交换操作的同库分区事务方式,用于在同一服务器上不同数据库之间执行跨库数据处理的本机跨库数据泵方式,以及用于在不同服务器上不同数据库之间执行跨库数据处理的跨物理机跨库数据泵方式。清理方案的各个清理方式可由自定义配置项信息来实现自定义编辑,可满足不同场合的各种清理需求。
为了实现配置项的全面化简捷化,作为一个具体的实施方式,本发明的配置项信息列表如下:
本发明的清理方案的各数据清理方式列表如下:
通过对配置项信息进行操作选择,可得到如下清理方案:
上述清理方案中的7中清理方式分别详细描述如下:
0)同库事务方式
i.各配置项信息形成数据清理配置表kapp_sjqlpz,由该数据清理配置表中的数据清理方式sjqlfash配置为0的记录获取被清理表的清理关键字;
ii.根据生产保留时长计算清理关键字范围;
iii.使用同一事务将生产表指定范围数据迁移至历史表,并删除生产表指定范围数据。
1)同库分区交换方式
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为1的记录,获取被清理表的保留时长和清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称;
iii.使用分区交换的方式将生产表指定分区的数据迁移至历史表指定分区;
iv.重建历史表指定分区的索引;
v.删除生产表指定分区。
2)本机跨库数据泵方式(生产库生产表至历史库)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为2的记录,获取被清理表的生产保留时长和生产清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称;
iii.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
iv.获取配置文件中的数据源信息;
v.导出生产库指定分区数据为转储文件;
vi.导入转储文件至历史库指定分区;
vii.删除生产库指定分区。
3)本机跨库数据泵方式(生产库历史表至历史库历史表采用同库事务方式)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为3的记录,获取被清理表的清理关键字、生产保留时长和近线保留时长;
ii.根据生产保留时长计算清理关键字范围;
iii.使用同一事务将生产表指定范围数据迁移至历史表并删除生产表指定范围数据;
iv.根据近线保留时长计算清理关键字范围;
v.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
vi.获取配置文件中的数据源信息;
vii.导出生产库历史表指定范围数据为转储文件;
viii.导入转储文件至历史库;
ix.如果第vii、viii步骤成功,则删除历史表指定范围数据。
4)本机跨库数据泵方式(生产库历史表至历史库历史表采用同库分区交换方式)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为4的记录,获取被清理表的生产保留时长、生产清理频率、近线保留时长和近线清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称;
iii.使用分区交换的方式将生产表指定分区的数据迁移至历史表指定分区;
iv.重建历史表指定分区的索引;
v.删除生产表指定分区;
vi.根据近线保留时长和近线清理频率计算分区名称;
vii.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
viii.获取配置文件中的数据源信息;
ix.导出历史表指定分区数据为转储文件;
x.导入转储文件至历史库指定分区;
xi.删除历史表指定分区。
5)跨物理机跨库数据泵方式(生产库生产表至历史库)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为5的记录,获取被清理表的生产保留时长和生产清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称;
iii.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
iv.获取配置文件中的数据源信息;
v.导出生产库指定分区数据为转储文件;
vi.将转储文件从生产库服务器ftp至历史库服务器;
vii.导入转储文件至历史库指定分区;
viii.删除生产库指定分区。
6)跨物理机跨库数据泵方式(生产库历史表至历史库历史表采用同库事务方式)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为6的记录,获取被清理表的清理关键字、生产保留时长和近线保留时长;
ii.根据生产保留时长计算清理关键字范围;
iii.使用同一事务将生产表指定范围数据迁移至历史表并删除生产表指定范围数据;
iv.根据近线保留时长计算清理关键字范围;
v.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
vi.获取配置文件中的数据源信息;
vii.导出生产库历史表指定范围数据为转储文件;
viii.将转储文件从生产库服务器经ftp传输至历史库服务器;
ix.导入转储文件至历史库;
x.如果第viii、ix步骤成功,则删除历史表指定范围数据。
7)跨物理机跨库数据泵方式(生产库历史表至历史库历史表采用同库分区交换方式)
i.根据数据清理配置表kapp_sjqlpz中的数据清理方式sjqlfash配置为7的记录,获取被清理表的生产保留时长、生产清理频率、近线保留时长和近线清理频率;
ii.根据生产保留时长和生产清理频率计算分区名称;
iii.使用分区交换的方式将生产表指定分区的数据迁移至历史表指定分区;
iv.重建历史表指定分区的索引;
v.删除生产表指定分区;
vi.根据近线保留时长和近线清理频率计算分区名称;
vii.获取数据库视图dbadirectories中directory_name配置为dbcleandump的directory_path,即转储文件目录;
viii.获取配置文件中的数据源信息;
ix.导出历史表指定分区数据为转储文件;
x.将转储文件从生产库服务器经ftp传输至历史库服务器;
xi.导入转储文件至历史库指定分区;
xii.删除历史表指定分区。
上述配置项信息还描述了历史查询方案,该历史查询方案包括数据路由过程和结果拼接过程。
其中,数据路由包括如下步骤:
i.对于数据路由处理,通过查询数据清理转移表返回生产库与历史库的日期界限,以及传入的起止日期,规定如下:
ii.起始日期大于等于生产库与历史库的日期界限值,路由到生产库单数据源。
iii.终止日期小于生产库与历史库的日期界限值,路由到历史库单数据源。
iv.否则,先路由到生产库数据源,再路由到历史库数据源。
v.同时,由应用平台提供数据路由模板,ide工具自动完成dao生成类逻辑。
结果拼接包括如下步骤:
i.新增命名sql对应的历史查询方法。
ii.业务程序如果是历史查询,则需要调用历史查询方法。
iii.原查询方法保留,以备有其它用途。
iv.新增的历史查询方法中,通过双库遍历方式完成历史数据查询。
v.历史查询方法中,开放回调类,由应用平台实现,用以提供历史库与生产库的数据界线。
vi.历史查询方法中,平台需要使用两个数据库连接完成查询、结果拼接。
图3为本发明的历史数据查询的一个具体实例的流程图。
另外,本发明的数据库不限定其物理位置,针对多数据源运维管理有如下设计方案:
a)针对不同抽象组件配置不同dbagentor。
b)针对不同dbagentor配置不同清理策略。
c)运维平台发起清理请求,调度各节点dbagentor做不同策略的清理。
本发明的具体实施可包括:上传脚本,开通无密码ssh连接,创建转储目录,配置ftp传输信息,配置数据源信息,部署增量包,创建分区表,清理策略配置,代理流程、流程步骤以及目标代理配置,运维平台发起验证等过程。
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!