面向用户极致体验的社交网络数据放置方法与流程
本发明属于数据存储领域,特别涉及一种面向用户极致体验的社交网络数据放置方法。
技术背景
在线社交网络用户分布在世界各地,可以与其他人共享不同类型的数据,包括视频类以及音频类的数据,而且这些数据的种类和大小还在迅速的增加。社交网络供应商在向用户提供服务时,需要满足数据传输的低延迟性,数据稳定性、有效性以及隐私性的需求,保证用户在一个可接受的时间范围内获得自己需要的数据。如果在满足用户延迟要求的时间内不能获得他们想要的数据,就会降低用户的使用体验,从而使供应商的收益受到影响。目前,传统的解决方法,就是在每个用户所在的数据中心存放一个完整的数据副本以保证数据传输的低延迟性,但这个方法会大大提高副本的存储数量,带来非常高的数据存储费用,而且不同用户的数据副本需要定期更新,保持一致性,从而导致高额的维护工作量和传输成本。所以在进行社交网络数据放置时需要权衡时间延迟和数据存储费用。
目前,有很多社交网络服务供应商使用私有数据中心来存储用户的数据。然而,建立私有数据中心费用极其昂贵,而且还要考虑快速增长的数据量、数据中心的维护和数据中心能源等问题,因此建立私有的数据中心不是一个明智的选择。为了解决这一问题,一个合适的方法是使用公有云数据中心。例如amazons3,google云存储,microsoftazure等云服务供应商在世界各地建立不同的数据中心。通过使用云数据中心,社交媒体服务提供者能够让地理上分布的用户进行数据交流时满足延迟要求,同时使得数据的存储费用最小化。如果将用户的数据副本存放在在世界上所有的数据中心中,将带来十分昂贵的存储费用以及更新数据所产生的传输费用。
综上所述,数据存储在社交网络应用中是一种数据密集型的工作,并且供应商不能承受将数据中心建立在世界各地而产生的高昂费用,所以许多社交网络供应商(例如dropbox)使用云数据中心去存储数据。因此需要设计一个方法,使得社交网络用户在进行数据交互时,让所有用户能够在可以忍受的时间范围内(可接受的延迟时间一般为250ms以内)获得所需的数据信息,同时让数据的存储费用最小化。
技术实现要素:
本发明目的是针对现有的社交网络数据放置方法的不足之处,提出了一种面向用户极致体验的社交网络数据放置方法。此方法是以粒子群优化算法为核心的智能数据放置算法,不仅能够在云数据中心中找到合适的位置来存储数据,而且能够计算出合适的副本数量来保证社交网络用户与他们朋友之间进行信息交流时的延迟要求同时使得数据存储费用最小化。
为了实现以上目标,本发明采用以下技术方案:一种面向用户极致体验的社交网络数据放置方法,包括两个阶段:
初始化阶段:采用自适应方法将采集的用户社会关系数据集根据社交关系进行位置初始化;数据布局阶段:采用上一阶段的输出作为初始输入,并采用粒子群优化算法为核心的数据放置方法来进行数据布局。
进一步的,初始化阶段具体包括以下步骤:
(1)首先随机初始化n个用户所在的数据中心,并获得用户之间的社交关系;
(2)从n个用户中随机选择比例p的用户,在初始化时需要满足延迟性在250ms以下;
(3)对所有的用户进行位置初始化,如果用户i是需要满足延迟性要求的,从社交关系网中找出用户i的所有朋友,然后找出用户i朋友所分布的数据中心,在这些数据中心中全部放上用户i的数据;如果用户i是不需要满足延迟性要求的用户,进行随机初始化;
(4)所有用户位置初始化结束,得到m个可行性解空间。
进一步的,比例p为50%、70%、90%或99%。
进一步的,数据布局阶段具体包括以下步骤:
(1)通过初始化方法生成m个可行性解空间,每个解空间为一个种群;
(2)随机初始化每个种群中每个粒子的速度,速度空间范围为[-10,10];
(3)通过公式1计算每个粒子的适应度值,并以此初始化粒子的当前最优位置pbest,将当前种群中最优pbest记为gbest;
其中:
sci=usp*sdsi*ri
cost表示的存储数据的总费用;
sci表示在1个数据中心中存储用户i的数据1个月所产生的费用;
usp表示在1个数据中心中存储1gb数据1个月所产生的存储费用;
sdsi表示用户i的数据大小;
ri表示用户i副本的总个数。
(4)采用公式2和3对pbest和gbest进行迭代循环来更新粒子的速度和位置,总迭代数为40次;
其中:
c1,c2表示学习因子,取值为2;
r1,r2表示均匀分布在[0,1]之间的两个随机数;
w表示惯性权重,w=0.9-(iter/iter)*0.5,iter表示当前迭代次数,iter表示迭代总数;
(5)对每个更新后的粒子首先利用公式4的约束条件来检测是否满足延迟要求,如果满足则返回步骤3利用公式1来计算适应度值,并更新pbest和gbest;
不满足延迟条件则返回步骤4,当迭代数达到40次时,结束循环,得到gbest,即为最优解。
本发明提出一种全新的考虑多目标的数据放置方法,兼顾了传统的以存储费用为目标的数据放置问题,同时考虑社交网路用户之间信息交互的延迟问题,利用粒子群智能优化算法将两个问题整合到一起,设计了面向用户极致体验的社交网络数据放置方法。
本发明的有益效果:主要解决了因地理上分散的社交网络用户之间信息交流延迟过高的问题。社交网络中当用户之间进行信息交互时,因为地理上分布距离较远的原因,数据传输不可避免的产生延迟,当传输延迟超过用户所能接受的时间范围时将影响用户的社交体验。本发明采用了粒子群算法来优化社交网络中用户数据的存储位置,在保证网络用户延迟要求的基础上同时最大化减少数据的存储费用,不仅提高了用户的社交体验而且降低了社交网络服务供应商存储成本,同时为社交网络服务供应商了一个高效的数据管理方法。
附图说明
图1是用户-副本分布图。
图2是面向用户极致体验的社交网络数据放置方法的自适应初始化阶段流程图。
图3是基于粒子群优化算法的社交网络数据放置方法流程图。
具体实施方法
下面结合附图对本发明进行详细说明。
基于粒子群优化算法的智能数据放置算法包括两个阶段,第一阶段:数据初始化阶段;第二阶段:数据布局阶段。
1.优化模型
本发明规定距离每个用户最近的数据中心为此用户的主数据中心,每个用户有一个主副本位于主数据中心中,在其他数据中心中存储若干个从副本,在同一个数据中心中同一个用户的副本数不能超过1个。每个用户都是从主数据中心中读取自己的数据,如图1所示。
1)费用模型—粒子群优化的智能数据放置算法的适应度函数
该费用指的是所有数据中心中的所有数据副本所产生的存储费用。假设有n个用户,每个用户的从副本数目为ri,那么存储费用的计算公式1如下:
其中:
sci=usp*sdsi*ri
cost表示的存储数据的总费用;
sci表示在1个数据中心中存储用户i的数据1个月所产生的费用;
usp表示在1个数据中心中存储1gb数据1个月所产生的存储费用;
sdsi表示用户i的数据大小;
ri表示用户i副本的总个数。
2)延迟模型—粒子群优化的智能数据放置算法的约束条件
用户与数据中心之间的网络延迟是使用地理距离来衡量的,然而无法从网络上获得用户的具体位置信息,因此只能根据用户的大概经纬度生成随机位置。如果用户与其主数据中心在同一区域,则规定用户与其主数据中心之间的网络延迟为20ms。用户与其他数据中心之间的网络延迟由如下公式得到:
此公式是通过ping位于美国的260主机之间的单向延迟发现这个线性关系真实存在。每个用户从距离其最近的存储所需数据的数据中心中读取数据,当平均响应时间不大于250ms时,就认为此次网络延迟满足用户的延迟要求。
2.第一阶段:初始化阶段
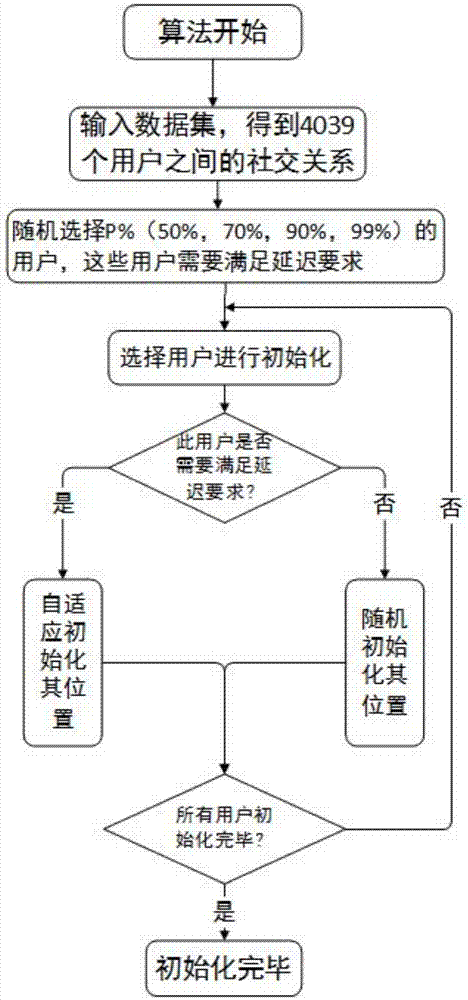
该阶段提出了一种自适应的初始化方法,具体流程见图2。用户之间的社交网络关系数据集来自于facebook网站2015年的真实数据,其中有4039个用户和88234个社交关系数据集。将采集的数据集根据社交关系进行位置初始化,使其满足粒子群优化算法的计算规则。在社交网络中,因为用户群体规模巨大,想让所有的用户满足网络延迟要求基本是不现实的,因此将在满足不同比例的用户延迟要求的前提下来检测此方法的可靠性和效率。该方法将比例设置成50%,在此比例下来进行试验来验证本方法的可靠性和有效性。
3.第二阶段:数据布局阶段
本阶段中,提出了基于粒子群优化算法的社交网络数据放置方法,具体流程见图3。该算法采用第二阶段的输出作为初始输入,第一阶段的公式1为适应度函数,公式2为约束条件来迭代更新每次的结果。每个数据中心中每月存储1gb数据产生的费用为0.125美元,每个用户每月存储27mb的数据,网络延迟需要保证在250ms以下。由于结合了第一阶段的自适应初始化方法,基于粒子群优化算法的社交网络数据放置方法的运算效率有所提升,并且收敛速度更快。基于粒子群优化算法的社交网络数据放置方法的粒子速度和位置由公式3和4进行更新,迭代次数设置为40次,每次迭代记录下局部最优pbest和全局最优gbest,直至迭代结束,得到最优值。
首先是部署实验环境,windows7系统下采用的matlab2014作为开发环境。
本方法主要解决的是社交网络中数据副本的数量和存放位置的问题,保证用户在进行信息交流时的时间延迟在可接受的范围内,同时使数据存储费用最小化,优化社交网络服务供应商在云资源分配中的费用,该费用不包括传输费用和数据的更新费用。
1.初始化阶段
该步骤的具体流程图见图2;
step1:首先随机初始化n个用户所在的数据中心(通过采集自facebook网站的数据集得到每个用户之间的社交关系);
step2:从n个用户中随机选择一定比例p(50%、70%、90%、99%)的用户,这些用户在初始化时需要满足延迟性在250ms以下,剩下的不需要满足延迟性要求的用户,可以随机初始化,那么这样初始化之后种群中满足延迟性要求的用户比例必定不小于p;(比如需要保证满足延迟性要求的用户比例为50%,那么就从n个用户中随机选择n*0.5个用户);
step3:然后对每个用户分别进行初始化;
step4:进行循环迭代,总数为用户个数n;
step5:如果用户i是需要满足延迟性要求的;
step6:从社交关系网中找出用户i的所有朋友,然后在找出用户i朋友所分布的数据中心,在这些数据中心中全部放上用户i的数据;(具体操作见表1);
step7:如果用户i是不需要满足延迟性要求的用户;
step8:可以随机初始化;
step9:返回step5,当迭代结果达到n次,结束循环;
step10:得到最终结果。
表1用户副本-数据中心放置方案
表1中第1行表示数据中心编号,第1列表示用户的编号,以用户1为例,假如用户1是需要满足延迟性要求的用户,通过社交网络关系网得到用户1的朋友分布在数据中心4、7、8、10所在的区域,用户1位于数据中心2所在的区域,那么在数据中心2、4、7、8、10中各放置一个副本,其他的数据中心不放置副本,这样用户1以及用户1朋友的延迟都会小于250ms;这样第1个用户初始化完成;如果某个用户不需要满足延迟性要求,那么就随机初始化。
2.数据布局阶段
为了更加明确的解释本发明的技术方案,首先对本发明基于的粒子群优化算法进行简单的介绍。
粒子群优化算法(particleswarmoptimization,pso)源自于对自然界中鸟群和鱼群等群体动物运动行为的研究,是一种基于群体智能方法的演化计算技术。粒子群优化算法的基本思想是通过群体中个体之间的协作和信息共享来寻找最优解,此算法简单,搜索效率高,通过对参数的调节能够很好的解决局部最优问题。采用此算法不仅能够保证结果的收敛速度,而且能够在更短的时间内得到最优的结果。在jameskennedy和russelleberhart提出的粒子群优化算法中(kennedyj,eberhartr.particleswarmoptimization.proceedingsoftheieeeinternationalconferenceonneuralnetworks(perth,australia),1942–1948.piscataway,nj:ieeeservicecenter;1995),每个优化问题的潜在解都可以想象成搜索空间上的一个点,称之为“粒子”(particle),每个粒子都有自己的位置和速度,粒子在空间中的位置代表解空间中的一个解,而速度则代表着粒子飞行的方向和距离,这个速度根据它本身的飞行经验和同伴的飞行经验来动态调整。所有的粒子都有一个被目标函数所决定的适应度值(fitnessvalue),并且记录自己到目前为止发现的最好位置(particlebest,记为pbest)和当前位置,这个可以看作是粒子自己的飞行经验。除此之外,还记录下到目前为止整个种群中所有粒子发现的最好位置(globalbest,记为gbest),这个可以看作是粒子同伴的经验。
始化阶段确定了每个粒子的位置,然后随机初始化每个粒子的速度信息,然后在以后的迭代过程中粒子通过pbest和gbest来更新自己,同时为了避免粒子群优化算法违背保证延迟时间要求的初衷。因此在每次迭代过程中,每个用户的主副本所在的位置不会变化,必须存储在主数据中心。粒子的位置和速度更新公式分别如公式3和公式4所示。
其中:
c1,c2表示学习因子,本方法中取2
r1,r2是均匀分布在[0,1]之间的两个随机数
w表示惯性权重,在本方法中w=0.9-(iter/iter)*0.5,iter表示当前迭代次数,iter表示迭代总数。此惯性权重可以动态的调整解空间的搜索范围,随着迭代次数的增加,惯性权重不断减小,从而使得粒子群优化算法在初期具有较强的全局收敛能力,而在后期具有较强的局部收敛能力。
基于粒子群优化算法的社交网络数据放置方法的流程如下,该步骤的具体流程图见图3。
step1:通过初始化阶段随机生成30个可行性解空间,每个解空间为一个种群;
step2:随机初始化每个种群中每个粒子的速度,本方法中的速度空间为[-10,10];
step3:通过公式1计算每个粒子的适应度值,并以此初始化粒子的当前最优位置pbest;
step4:当前种群中最优的pbest记为gbest;
step5:进行迭代循环,总迭代数为40次;
step6:利用公式(3)(4)来更新粒子的速度和位置;
step7:对每个更新后的粒子首先利用约束条件(2)来检测是否满足延迟要求,如果满足则利用公式1来计算适应度值,并更新pbest和gbest;
step8:返回step6,当迭代数达到40次时,结束循环;
step9:得到gbest,即为最优解。
以上所述,仅是本发明的较佳实施例而已,并非对本发明做任何形式的限制。凡是依据本发明的技术和方法实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明的技术和方法方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法
- 利用媒体提示来识别和关联用户设备的系统、方法和介质的制作方法
- 基于用户的媒体内容分节系统和方法
- 对公司社交网络的用户接收的消息进行分类的方法
- 基于对邻近一个或多个用户的媒体输出设备的动态发现的自组织(ad-hoc)媒体呈现的制作方法
- 使用确认指示来提高社交网络中的用户参与度的制作方法
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 在多个社交网络中识别同一用户的方法及装置的制造方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法