一种基于超像素的区域合并SAR图像海岸线检测算法的制作方法
本发明涉及一种基于超像素的区域合并sar图像海岸线检测算法,属于海岸线检测领域。
背景技术:
合成孔径雷达是一种主动式微波探测器,利用合成孔径原理、信号处理方法和脉冲压缩技术,通过较小尺寸的真实天线孔径合成较大的等效天线孔径来成像。sar图像已广泛应用于战略目标的识别探测、灾害控制、国土资源监测、海域使用管理、地图测绘、船舰目标识别、矿产勘探、农作物生长监测等领域并发挥重要作用。在海域使用管理中,海岸线检测是一个重要环节,通过检测海岸线可以监测海岸带变化。由于填海造地、江河泥沙堆积等原因,使得海岸线不断发生变化,能够长期监测海岸线的变化,对海域使用的动态监测具有一定实际意义。但由于相干斑、海风和陆地环境的复杂性等因素,使得海岸线检测具有较大难度。当海面或者陆地不均匀时,已有的区域合并海岸线检测算法容易出现无法合并的小区域,且需要人为设定合并的阈值。
技术实现要素:
本发明针对以上问题的提出,一种基于超像素的区域合并sar图像海岸线检测算法,其特征在于包括如下步骤:
s1:读取合成孔径雷达sar(syntheticapertureradar)图像i,输入k个超像素的种子点;
s2:根据所述种子点的数量k和图像的宽m和高n,计算种子点的位置;
s3:遍历所述合成孔径雷达图像i,根据邻域点j和种子点的相对位置关系确定邻域点局部窗和种子点局部窗的形状;所述邻域点j是指位于中心点i的2像素×2像素的局部窗内,分别计算出种子点局部窗和邻域点局部窗内邻域点和中心点的相似程度si,j;
s4:在邻域点和中心点的局部窗内对所述邻域点均值和中心点均值的相似程度si,j在局部窗内采用聚类算法求得ci,所述集合选取si,j接近1的邻域点j作为和中心点i属于同一类的点,这些点的集合即ci,并计算各中心点i的均值和集合ci中每一个点均值的标准差作为中心点的特征;
s5:计算邻域点j和其周围每一个种子点的di,j;将邻域点j合并di,j最小的种子点中,并更新种子点i的特征和位置;所述合并邻域点j分配和中心点i相同的标签即两者属于同一类;
s6:重复步骤s3-s5直至所有点的类别都不在发生变化;
s7:计算超像素的像素均值,超像素内像素数量和超像素内像素的标准差;遍历所述图像i,计算出超像素i和超像素j之间的相似性di,j和两个超像素的相似性判断的阈值e,当di,j小于e的大小时合并超像素的区域;
s8:重复步骤s7,直到迭代前后超像素不再合并,则输出海岸线检测结果。
进一步的,所述种子点的位置计算为:
在计算结果5像素×5像素的局部窗内选择梯度最小的像素为所述图像i的一种子点。
进一步的,所述si,j
其中,i表示中心点,j表示邻域点,μ(xi,yi)表示i局部邻域内的均值,μ(xj,yj)表示j局部邻域内的均值。
进一步的,所述dci,j
dci,j=||(μi,σi)t-(μj,σj)t||
其中,μi表示第i类超像素的均值,σi表示第i类超像素标准差,μj表示第j类超像素的均值,σj表示第j类超像素标准差,m表示dci,j与dsi,j之间的权重系数,s表示第一次选取种子点时,两个种子点之间的距离,t表示向量的转置,xi表示超像素i中心点的行坐标,xj表示超像素j中心点的行坐标,yi表示超像素i中心点的列坐标,yj表示超像素j中心点的列坐标。
进一步的,均值μ和每一个点局部窗内均值的标准差σ为:
其中,ci表示种子点第二类类像素的集合,n表示ci中像素的个数,μs(xj,yj)表示(xj,yj)处像素局部窗内的均值,
进一步的,所述更新种子点i的特征和位置为:
其中,s表示像素的位置,ls表示s处像素的标签值,ys表示s的列坐标,
其中,xs表示s的行坐标,ls表示s处像素的标签值,m表示第i类超像素中种子点的数量,
进一步的,所述超像素i和超像素j之间的相似性di,j:
其中,
其中,ni表示超像素i中像素的个数,nj表示超像素j中像素的个数,e表示的是两个超像素的相似性判断的阈值,
其中,
z1和z2表示超像素i和超像素j的统计量,
更进一步的,当所述si,j的值越接近于1时,则中心点i和邻域点j相似性越大;当si,j的值越接近于0时,则中心点i和邻域点j相似性越小。
本发明的优点在于:本发明提出一种基于超像素的区域合并sar图像海岸线检测算法,通过构建一个新的局部窗,可以有效的解决传统矩形窗中因含有边缘导致计算出的特征模糊的问题,通过该局部窗构建一个相似性描述子,使得提取出的特征更加精确,使得超像素的边缘贴合度更高。以超像素为基元,提出一种区域合并准则,该准则同时考虑了超像素的像素均值、相对大小和统计量信息,再根据邻域信息得到确定局部阈值,解决了已有算法中需要人为设置阈值的问题。
附图说明
为了更清楚的说明本发明的实施例或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做一简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的整体流程图。
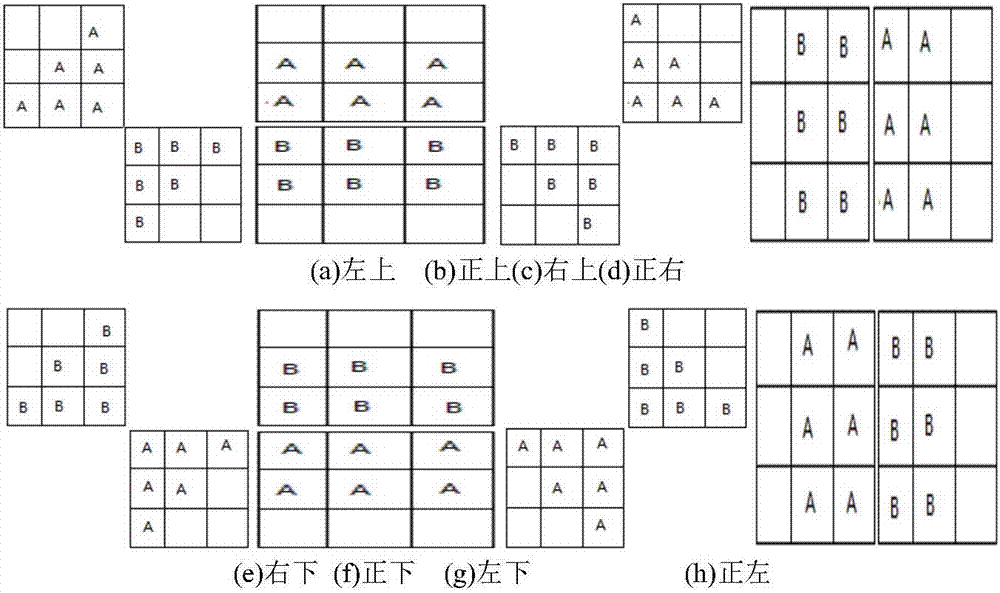
图2为本发明的局部窗的形状示意图。
图3为本发明的检测海岸线示意图。
具体实施方式
为使本发明的实施例的目的、技术方案和优点更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述:
如图1、图3所示,一种基于超像素的区域合并sar图像海岸线检测算法,包括如下步骤:
s1:读取合成孔径雷达sar(syntheticapertureradar)图像i,输入k个超像素的种子点;
s2:根据种子点的数量k和图像的宽m和高n,计算种子点的位置;
s3:遍历合成孔径雷达图像i,根据邻域点j和种子点的相对位置关系确定邻域点局部窗和种子点局部窗的形状;邻域点j是指位于中心点i的2像素×2像素的局部窗内,分别计算出种子点局部窗和邻域点局部窗内邻域点和中心点的相似程度si,j;
s4:在邻域点和中心点的局部窗内对邻域点均值和中心点均值的相似程度si,j在局部窗内采用聚类算法求得ci,集合选取si,j接近1的邻域点j作为和中心点i属于同一类的点,这些点的集合即ci,并计算各中心点的均值和集合ci中每一个点均值的标准差作为中心点的特征;
s5:计算邻域点j和其周围每一个种子点的di,j;将邻域点j合并di,j最小的种子点中,并更新种子点i的特征和位置;合并邻域点j分配和中心点i相同的标签即两者属于同一类;
s6:重复步骤s3-s5直至所有点的类别都不在发生变化;
s7:计算超像素的像素均值,超像素内像素数量和超像素内像素的标准差;遍历图像i,计算出超像素i和超像素j之间的相似性di,j和两个超像素的相似性判断的阈值e,当di,j小于e的大小时合并超像素的区域;
s8:重复步骤s7,直到迭代前后超像素不再合并,则输出海岸线检测结果。
在本实施方式中,种子点的位置计算为:
在计算结果5像素×5像素的局部窗内选择梯度最小的像素为图像i的一种子点。在本实施方式中,如图2(a)-(h)所示,局部窗的形状其中b所在的3像素×3像素的局部窗是种子点的,a所在的3像素×3像素的局部窗是邻域点的,种子点和邻域点的局部窗是可以重合的,邻域点局部窗中含a的像素形成的集合是邻域点局部窗的形状,中心点局部窗内含b的像素形成的集合即中心点的局部窗。即中心点和邻域点的局部窗不再是固定大小的3像素×3像素的局部窗而是变成了根据邻域点和中心点的相对位置关系形成的三角形和矩形。可以理解为在其他实施方式中,只要能够在一定程度上剔除边缘对计算中心点或邻域点特征的影响即可。
在本实施方式中,si,j
其中,i表示中心点,j表示邻域点,μ(xi,yi)表示i局部邻域内的均值,μ(xj,yj)表示j局部邻域内的均值。
作为优选的实施方式,dci,j
dci,j=||(μi,σi)t-(μj,σj)t||
其中,μi表示第i类超像素的均值,σi表示第i类超像素标准差,μj表示第j类超像素的均值,σj表示第j类超像素的标准差,m表示dci,j与dsi,j之间的权重系数,s表示第一次选取种子点时,两个种子点之间的距离,t表示向量的转置,xi表示超像素i中心点的行坐标,xj表示超像素j中心点的行坐标,yi表示超像素i中心点的列坐标,yj表示超像素j中心点的列坐标。
在本实施方式中,均值μ和每一个点局部窗内均值的标准差σ为:
其中,ci表示种子点第二类类像素的集合,n表示ci中像素的个数,μs(xj,yj)表示(xj,yj)处像素局部窗内的均值,
作为优选的实施方式,更新种子点i的特征和位置为:
其中,s表示像素的位置,ls表示s处像素的标签值,ys表示s的列坐标,
其中,xs表示s的行坐标,ls表示s处像素的标签值,m表示第i类超像素中种子点的数量,
作为优选的实施方式,超像素i和超像素j之间的相似性di,j:
其中,
其中,ni表示超像素i中像素的个数,nj表示超像素j中像素的个数,e表示的是两个超像素的相似性判断的阈值,
其中,
z1和z2表示超像素i和超像素j的统计量,
在本实施方式中,当si,j的值越接近于1时,则中心点i和邻域点j相似性越大;当si,j的值越接近于0时,则中心点i和邻域点j相似性越小。可以理解为在其他实施方式中,只要能够区分中心点i和邻域点j的相似性即可。
实施例参数设置:
本发明的参数设置为:种子数k为300,dc与ds之间的权重系数m为0.5,超像素的最大迭代次数为10,局部窗的大小是3×3,区域合并的最大合并次数为7。
gamma分布水平集方法的参数设置为:最大迭代次数是10000,弧长项系数μ为0.4,heaviside函数的幅度为1,c1和c2的权值均为1,时间步长为0.1。
基于目标的区域合并算法参数设置为:粗合并类别数k为10,置信度λ为0.9。
实施例:
算法性能对比主要采用均方根误差rmse和qa(overallaccuracy)作为精度分析指标,首先进行rmse对比,其计算公式如下:
其中rmse代表了手绘海岸线与各种算法提取海岸线的平均误差,x1k表示人工手绘得到的海岸线提取结果的二值图中第k个位置像素的像素值。x2k表示上述理论模型得到的海岸线提取结果的二值图中第k个位置像素的像素值,n表示图像像素数。rmse值越小说明与真实的海岸线越接近,精度越高。
针对envisat图像,算法的rmse对比如表1所示。
表1针对envisat图像的三种算法rmse对比
根据rmse表达式可知,rmse值越小说明模型检测结果和真实的海岸线结果越接近,水平集的方法和区域合并的方法并不能检测出海岸线的真实位置,而本发明算法可实现海岸线精确的检测,通过rmse值可以看出本专利算法检测性能明显优于两种对比算法,针对radarsat图像,算法的rmse对比如表2所示。
表2针对radarsat图像的三种算法rmse对比
从上述实验数据可以看出对于radarsat图像中对于海面比较均匀且海陆对比度比较大的图像,三种算法均能实现较好的实验结果,从rmse值可以看出本发明算法的性能要优于其它两种对比算法。
下面本专利采用性能指标qa(overallaccuracy)作为以上三种算法的性能评价标准,其表达式为:
其中,x1s表示人工手绘海岸线结果s位置像素的标签值,x2s表示实验得到的海岸线结果s位置像素的标签值,m表示图像的像素数,s表示图像位置集合。其含义是正确分类的像素占整体的百分比,其中参考标准是人工确定的海岸线。当qa的值越大,说明得到的海岸线越精确。实验图像与前一性能对比实验相同,针对envisat图像,qa的性能指标如表3所示。
表3针对envisat图像的三种算法qa对比
针对radarsat图像,qa的性能指标如表4所示。
表4针对radarsat图像的三种算法qa对比
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!