一种采空区危险临界程度预判方法与流程
本发明涉及煤矿安全生产技术领域,更具体地,涉及一种采空区危险临界程度预判方法。
背景技术:
随着服务年限的增加和开采条件的恶化,采空区的分布日趋复杂和体积不断增大,给深部矿体开采、浅部残矿回收以及地表建筑使用等带来了日趋严重的安全隐患。当坚硬顶板采空区的面积超过一定极限时,将会引起大面积冒落,一次冒落的面积少则数千平方米,多则可达数万平方米。这样大面积顶板在极短时间内冒落下来,不仅由于重量的作用会产生严重的冲击破坏力,而且更加严重的是把已采空间的空气瞬间排出,形成巨大的暴风,破坏力极强。顶板大面积来压现象在我国很多矿区都有发生,其中以山西大同矿区最为典型和严重。这种现象都塌至地表,形成近似椭圆的塌陷区,表现出上小下大,四周断裂面与水平面的夹角为60°~90°。顶板大面积来压事由坚硬岩层大面积冒落而形成的,这些岩层直接覆盖在开采矿体上,一般为厚层整体结构,层理和节理均不发育。当矿体面积与采空面积之比小于30%时,容易形成顶板大面积来压现象。顶板大面积来压主要的危险是顶板冒落而形成的冲击载荷和暴风。
采空区冒落危险临界程度预判是一项复杂的系统工程,影响该系统输出的因素很多,如围岩强度、悬露面积、节理构造、水文地质、采空体积、高垮比值等。这些因素表现出随机性、模糊性和灰色性,采空区的冒落危险等级与具体因素存在着复杂的非线性关系,难以用具体模型和准确方法来描述。国内研究集中在数值分析的基础上对采空区稳定性进行评价,但这些方法对空区模型与参数选择的准确性要求很高,实际中难以获得真实的评价结果,往往只具有指导意义和示范价值。因此,探求一种准确且便利的采空区危险临界程度预判方法具有一定的经济意义和的紧迫的现实意义。
在现有技术中对采空区冒落危险的防御还仅限于监测,例如在长沙矿山研究院有限责任公司的发明专利“一种顶板冒落高度监测装置”(cn201520432375.5)中,使用地表或巷道底板与空区顶板之间的钻孔,线缆,电源,滑动变阻器和发光二极管;所述钻孔内按设定标高铺设多根线缆,所述线缆的两端引出地表,并依次与电源、滑动变阻器和发光二极管连接形成回路;所述发光二极管之间并联连接。通过观察发光二极管的亮灭,监测顶板距离地表或巷道的厚度,从而确定顶板的标高,有效控制出矿量,避免出空采场造成了安全隐患。此专利对危险防御起不到预判作用,只有在危险即将发生时才能有监测作用。
技术实现要素:
本发明的目的是提供一种综合考虑了矿井采掘信息和矿体地质资料中各参数对冒落危险的影响及之间的相关联关系,通过运用相似关联度获得主要控制指标,通过学习和训练建立最优采空区冒落危险极限学习机,将待测采空区冒落危险主控指标的数据组成输入,得到采空区冒落危险等级,实现采空区冒落危险临界程度预判,(如图1)。步骤如下:
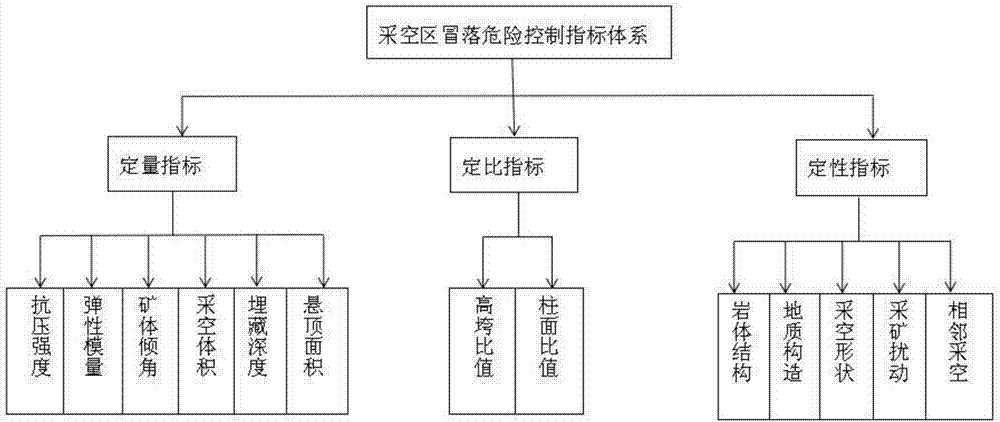
步骤1:构建采空区冒落危险控制指标体系,根据矿井采掘信息和矿体地质资料,采集采空区冒落危险控制指标参数。将采空区冒落危险控制指标划分为定量、定性和定比指标三个种类,结果为:矿压强度、弹性模量、矿体倾角、采空体积、埋藏深度和悬顶面积为定量指标;高垮比值和柱面比值为定比指标;岩体结构、地质构造、采空形状、采矿扰动和相邻采空为定性指标。
步骤2:运用相似关联度获得主要控制指标
根据步骤1获得的参数信息,得到不同指标序列与危险等级序列的始点零化像,计算两序列之间的灰色相似关联度。
设采空区冒落危险控制指标体序列xi=(xi(1),xi(2),…,xi(n)),冒落危险等级xj=(xj(1),xj(2),…,xj(n))的不同始点零化像分别为
计算不采空区冒落危险控制指标序列与冒落危险序列的相似关联度,利用预定阈值x得到n个采空区冒落危险的主要控制指标。
步骤3:训练并建立最优采空区冒落危险极限学习机预判识别模型
将步骤2中得到的所述n个空区冒落危险主要控制指标的的原始数据构成总体样本,其中总体样本划分为训练样本集和检验样本集两个部分;
将所述训练样本集序列组成输入矩阵,用data1表示,将所述训练样本的危险等级序列组成输出矩阵,用label1表示;建立[iw,b,lw,tf,type]=elmtrain(p,t,n,tf,type)函数对极限学习机模型进行内在学习;
建立y=elmpredict(p,iw,b,lw,tf,type)函数对极限学习机模型进行结果输出,其中p表示训练样本的输入矩阵,将检验样本集指标序列组成输入矩阵,用data2表示。将训练样本的危险等级序列组成输出矩阵,用label2表示。应用y=elmpredict(p,iw,b,lw,tf,type)函数对极限学习机模型进行结果输出。在检验过程中,p用data2代表,将y与label2比较。分析结果,确定最优采空区冒落危险极限学习机预判识别模型;
步骤4:使用步骤3中所述的最优采空区冒落危险极限学习机实现采空区危险预判
将待测采空区冒落危险主控指标的数据组成输入向量p,输入最优采空区冒落危险极限学习机的elmpredict函数,就可以得出结果。如果输出结果y为(1,1),则采空区冒落危险等级设定为事故状态;如果输出结果y为(1,0),则采空区冒落危险等级设定为隐患状态;如果输出结果y为(0,1),则采空区冒落危险等级设定为临界状态;如果输出结果y为(0,0),则采空区冒落危险等级设定为安全状态。
进一步的,在步骤2中所述的预定阈值x为0.1;
进一步的,在步骤2中所述的n个采空区冒落危险的主要控制指标为:高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动和相邻采空;
进一步的,步骤2中所述的总体样本划分为训练样本集和检验样本集两个部分,具体划分方法为训练样本集占总体样本的80%,检验样本集占总体样本的20%.
进一步的,步骤3中所述的最优采空区冒落危险极限学习机预判识别模型,其隐含层神经元个数为250个。
如本领域技术人员所能理解的,本发明可以用于任何危险临界程度预判相关的研究,尤其是矿山、地质等采空区危险临界程度预判相关的研究。
附图说明
图1为本发明示意图
图2为采空区冒落危险控制指标体系图
图3为冒落危险主要控制指标的相关系数矩阵图
图4为极限学习机的体系结构图
图5为隐含层神经元个数对极限学习机训练样本的性能影响图
图6为隐含层神经元个数对极限学习机检验样本的性能影响图
具体实施方式
下面的实施例可以使本领域技术人员更全面地理解本发明,但不以任何方式限制本发明。
如本文中所使用的,术语“包括”、“包括”、“具有”、“包含”、“涉及”等应该理解为开放式的,即,意指包括但不限于。除非上下文另有明确声明,本文中使用的单数形式“一”、“一个”和“这一”包括多个指示物。因此,贯穿该说明书,各个位置处的短语“在一个实施例中”或“在实施例中”的出现不必都参照相同的实施例。此外,在一个或多个实施例中,可以以任何合适的方式结合特定特征。
上面概述了实施例的特征,使得本领域技术人员可以更好地理解本发明的方面。本领域技术人员应该理解,他们可以容易地使用本发明作为基础来设计或修改用于实施与本文所介绍实施例相同的目的和/或实现相同优势的方法。本领域技术人员也应该意识到,这种等同构造并不背离本发明的精神和范围,并且在不背离本发明的精神和范围的情况下,本文中他们可以做出多种变化、替换以及改变。
以下结合详细资料为具体实施例对本发明做详细说明,但本发明并不仅限于以下举例:
本发明的计算方法包括下述步骤:
(1)构建采空区冒落危险控制指标体系
采空区处理是根据矿山压力规律和生产技术条件,控制采场顶板移动与采空跨落可以减轻采场压力显现并保证生产正常进行。通常根据顶板岩层特征、煤层回采厚度和地面不同地物,采空区处理方法有全部冒落法、全部充填法、局部充填法、缓慢下沉法,其中全部垮落法在我国矿山中应用最为广泛。
采空区冒落灾变机制属于小样本、贫信息的不确定性系统,即简单信息明确、运行过程灰化。在能够确认的信息中,有些信息带有单位量纲属于定量指标,包括抗压强度(mpa)、弹性模量(gpa)、矿体倾角(°)、采空体积(m3)、埋藏深度(m)和悬顶面积(m2)。有些信息为两指标比值属于定比指标,包括高垮比值和柱面比值,高垮比值为直接顶跨落高度与跨径长度的比值,柱面比值为矿柱面积与回采矿段的比值。还有一些指标无法定性描述属于定性指标,包括岩体结构、地质构造、采空形状、采矿扰动和相邻采空,其数据根据评分标准(8、6、4、2)来确定,分值越高表明稳定越差,这些指标构成了采空区冒落危险控制指标体系。
(2)运用相似关联度获得主要控制指标
设系统行为序列
xi=(xi(1),xi(2),…,xi(n))
xj=(xj(1),xj(2),…,xj(n))
的始点零化像分别为
令
则
①当
②当
③
设序列xi与xj长度相同,si-sj如上式所示,则称
灰色相似关联度εij具有以下性质:
①0≤εij≤1;
②εij仅与xi和xj的几何形状有关,而与其空间相对位置无关,或者说,平移转换不改变相似关联度的值;
③xi与xj在几何形状上越相似,εij越大,反之就越小;
④xi与xj平行,或
⑤εij=1;
⑥εij=εji。
根据矿井采掘信息和矿体地质资料,确定各控制指标的具体参数信息;将采空区冒落危险等级设定为事故、隐患、临界和安全四种不同状态,分别用1、2、3和4表示;然后利用matlab软件,设定代码(1,1)、(1,0)、(0,1)和(0,0)分别表示事故、隐患、临界和安全四种状态,采空区冒落危险控制指标数据如表1所示。直接使用原始数据计算控制指标与危险等级的灰色相似关联度,这样避免了单位量纲归一带来的信息含量损失。采空区冒落危险的灰色相似关联度如表2所示,高垮比值与危险等级的关联度最高,为0.678,弹性模量与危险等级的关联度最低,为0。选择以0.1为选择阈值,高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动和相邻采空这七个指标共同组成了采空区冒落危险的主要控制指标。
灰色相似关联主要测量不同序列之间的耦合作用,但这种方法重点关注不同序列的内在关系,而非具体关联数值。如果当序列数据绝对值较大时,|si-sj|或|si-sj|的数值可能较大,可以灰色相似关联数值较小的情形。但这种情形对于不同序列的内在联系没有决定性作用,所以灰色相似关联这种方法适用于序列的意义及量纲均不同的情形。
表1采空区冒落危险控制指标的原始数据
表2采空区冒落危险控制指标的相似关联
(3)基于相关系数矩阵的因子分析模型
因子分析是从研究对象中寻找公共因子,最早由查尔斯.斯皮尔曼在1904年提出。这种方法利用降维的思想,把一个原始变量分成两部分,一部分是少数几个公共因子的线性组合,另一部分是该变量所独有的特殊因子,其中公共因子和特殊因子都是不可观测的隐变量。
设p维总体x=(x1,x2…,,xp)’的均值为μ=(μ1,μ2,…,μp)’,协方差矩阵为∑=(σij)p×p,相关系数矩阵r=(ρij)p×p。因子分析的一般模型为
其中,f1,f2…,,fm为m个公共因子;εi是变量xi(i=1,2,…,p)所独有的特殊因子,它们都是不可观测的隐变量。称aij(i=1,2,…,p;j=1,2,…,m)为变量xi在公共因子fj上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。
上式还可以写成矩阵形式
x=μ+af+ε
其中,a=(aij)p×m成为因子载荷矩阵;f=(f1,f2…,,fm)’为公共因子变量;ε=(ε1,ε2…,,εp)’为特殊因子变量。通常对因子分析模型做如下假定:
①公共因子彼此不相关,且具有单位方差,即e(f)=0m×1,var(f)=im×m;
②特殊因子彼此不相关,即e(ε)=0p×1,
③公共因子和特殊因子彼此不相关,即cov(f,ε)=0m×p。
根据上述理论建立采空区冒落危险主要控制指标的因子分析模型,由高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动、相邻采空的原始数据构成。采空区冒落危险主要控制指标的相关系数矩阵图如图2示,因子分析结果如表3所示。
相关系数是一个绝对值不超过1的无量纲的数值,主要描述不同变量的线性相关程度。当相关系数为0时,变量间不存在线性趋势关系,但可能存在非线性趋势关系。当相关系数的绝对值为1时,一个变量是另一个变量的线性函数,越接近于1表明线性趋势越明显。在matlab平台,corrcoef函数用来计算不同指标的相关系数。相关系数还可以定义为标准化变量间的协方差,可以忽略不同指标的量纲单位和数量级别,所以相关系数这种定义也适用于序列的意义及量纲均不同的情形。
在图3,采用椭圆色块来直观表示不同变量之间的线性相关程度;椭圆越扁,相关系数的绝对值越接近于1,则变量间为强相关;椭圆越圆,相关系数的绝对值越接近于0,则向量间为弱相关。若椭圆的长轴方向是从左下到右上,则变量间为正相关;若椭圆的长轴方向是从右下到左上,则变量间为负相关。从图3可以发现,以相关系数的绝对值0.4为强弱阈值,采空体积与悬顶面积呈现强正相关,与采矿扰动呈现弱正相关,与柱面比值呈现强负相关;埋藏深度与采矿扰动呈现强负相关;悬顶面积与采空体积、相邻采空呈现强正相关,与柱面比值呈现强负相关;柱面比值与采空体积、悬顶面积呈现强负相关;采矿扰动与采空体积呈现弱正相关,与埋藏深度呈现强负相关;相邻采空与悬顶面积强正相关。将不同控制指标的相关系数绝对值累加求和发现,采空体积和悬顶面积构成了采空区冒落危险的核心控制指标,且悬顶面积的权重大于采空体积。
从表3可以看出,第一因子、第二因子和第三因子对原始数据总方差的贡献率分别为35.08%、22.99%和20.12%,累计贡献率达到了78.20%,这说明因子模型中考虑3个公共因子应该是比较合适的。在第一因子中,柱面比值的因子载荷绝对值达到了0.8637,说明第一因子主要反映矿柱分布,解释为矿柱因子;在第二因子中,相邻采空的因子载荷绝对值达到了0.9784,说明第二因子主要反映采空影响,解释为采空因子;在第三因子中,埋藏深度的因子载荷绝对值达到了0.6651,说明第三因子主要反映深度规律,解释为深度因子。
表3采空区冒落危险主要控制指标的因子分析结果
(4)以极限学习机实现采空区危险预判
极限学习机作为单隐含层前馈神经网络的典型代表,这种算法随机产生输入层与隐含层间的连接权值及隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元的个数,便可以获得唯一的最优解。与传统方法相比,这种方法具有学习速度快、泛化性能好、准确程度高等优点。
为极限学习机的体系结构图如图4所示,由输入层、隐含层和输出层组成,输入层与隐含层、隐含层与输出层神经元全连接。其中输入层有n个神经元,对应n个输入变量;隐含层有l个神经元;输出层有m个神经元,对应m个输入变量。设输入层与隐含层间的连接权值w为
其中,wji表示输入层第i个神经元与隐含层第j个神经元间的连接权值。
设隐含层与输出层间的连接权值β为
其中,βjk表示隐含层第j个神经元与输出层第k个神经元间的连接权值。
设隐含层神经元的阈值b为
设具有q个样本的训练集输入矩阵x和输出矩阵y分别为
设隐含层神经元的激活函数为g(x),则极限学习机网络的输出t为
t=[t1,t2,…,tq]m×q
其中,wi=[wi1,wi2,…,win];xj=[x1j,x2j,,…,xnj]t。
上式也可表示为
hβ=t’
式中,t’为矩阵t的转置;h为学习向量机网络的隐含层输出矩阵,
采空区冒落危险极限学习机预判识别模型概括为以下4个步骤:
(1)确定样本
利用matlab平台直接使用采空区冒落危险控制指标的原始数据,不进行归一处理以免数据信息丢失。采空区冒落危险控制指标的具体数据构成总体样本,其中总体样本的80%组成训练样本,总体样本的20%组成检验样本。在17个样本中,前14个样本组成训练样本,如表4所示;后3个样本组成检验样本,如表5所示。
表4采空区冒落危险极限学习机预判识别模型的训练样本
表5采空区冒落危险极限学习机预判识别模型的检验样本
(2)训练模型
将训练样本的高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动和相邻采空这七个指标序列组成输入矩阵,用data1表示。将训练样本的危险等级序列组成输出矩阵,用label1表示。
建立[iw,b,lw,tf,type]=elmtrain(p,t,n,tf,type)函数对极限学习机模型进行内在学习,其中iw为输入层与隐含层间的连接权值,b表示隐含层神经元的阈值,lw为隐含层与输出层的连接权值,tf为隐含层神经元的激活函数,type为极限学习机的应用类型,p表示训练样本的输入矩阵,t表示训练样本的输出矩阵,n表示隐含神经元的个数,取值100。在训练模型过程中,p用data1代表,t用label1代表,tf用’sig’默认函数,type取值为1来表示分类。
建立y=elmpredict(p,iw,b,lw,tf,type)函数对极限学习机模型进行结果输出,其中p表示训练样本的输入矩阵,iw为输入层与隐含层间的连接权值,b表示elmtrain函数隐含层神经元的阈值,lw为elmtrain函数隐含层与输出层的连接权值,tf为elmtrain函数隐含层神经元的激活函数,type为elmtrain函数极限学习机的应用类型,y为训练样本对应的输出预测值矩阵。在预测过程中,p用data1代表,将y与label1比较。分析结果,当隐含层神经元为100个时,训练样本预测正确率达71.4286%,也就是在14个学习样本中,有10样本正确,4个样本错误,分别是2号、8号、10号和11号样本。
(3)检验模型
将检验样本的高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动和相邻采空这七个指标序列组成输入矩阵,用data2表示。将训练样本的危险等级序列组成输出矩阵,用label2表示。应用y=elmpredict(p,iw,b,lw,tf,type)函数对极限学习机模型进行结果输出。在检验过程中,p用data2代表,将y与label2比较。分析结果,当隐含层神经元为100个时,训练样本预测正确率达66.667%,也就是在3个检验样本中,有2个样本正确,1个样本错误即15号样本,将4代表的安全状态检验为3代表临界状态,表明采空区冒落危险极限学习机预判识别模型的计算结果相对保守,能够增强现场主观安全意识和客观安全潜力。
(4)最优模型
基于matlab,应用[iw,b,lw,tf,type]=elmtrain(p,t,n,tf,type)函数和y=elmpredict(p,iw,b,lw,tf,type)函数。将隐含层神经元个数从50个到500个间隔50个探讨采空区冒落危险极限学习机预判识别模型,具体结果如图5和图6所示。
由图4可知,该模型并非隐含层神经元个数越多学习性能越好,从训练样本的预测准确率可以看出,当隐含层个数逐渐增加时,测试样本的预测正确率基本稳定在78.6%以上。当隐含层神经元个数为250个时,采空区冒落危险极限学习机模型的学习性能最佳,学习准确率高达92.86%,仅有9号样本学习错误。由图6可知,该模型也并非隐含层神经元个数越多检验越好,从检验样本的预测准确率可以看出,当隐含层个数逐渐增加时,测试样本的预测正确率基本稳定在66.7%以上。当隐含层神经元个数为250个时,采空区冒落危险极限学习机模型的学习性能最佳,学习准确率高达100%。
(5)实际应用
分析发现250个隐含层神经元建立极限学习机模型的效果最佳,利用检验样本对网络预测进行验证,若具体结果符合要求,说明该模型可行可靠可用,直接输入新数据得到预测结果进行实例应用。这说明此时的极限学习机模型最能适合采空区冒落危险,也表明该模型的计算结果比较正确、评判等级相对客观。
此时的采空区冒落危险极限学习机预判识别模型的输出t为
其中,wji表示输入层第i个神经元与隐含层第j个神经元间的连接权值,在y=elmpredict(p,iw,b,lw,tf,type)函数中,iw为输入层与隐含层间的连接权值矩阵(250×7),所以由参数iw代表wji,即输入层与隐含层的权值矩阵。βjk表示隐含层第j个神经元与输出层第k个神经元间的连接权值,在y=elmpredict(p,iw,b,lw,tf,type)函数中,lw为隐含层与输出层间的连接权值矩阵(250×4),所以由参数lw代表βjk,即隐含层与输出层的权值矩阵。b表示隐含层神经元的阈值,在y=elmpredict(p,iw,b,lw,tf,type)函数中,b表示隐含层神经元的阈值(250×1),所以由参数b代表b,即隐含层神经元的阈值。g(x)表示隐含层神经元的激活函数,在y=elmpredict(p,iw,b,lw,tf,type)函数中,tf为隐含层神经元的激活函数,采用用’sig’默认函数,所以由参数tf代表g(x),即输入层与隐含层的权值矩阵。所以,应用matlab平台建立的y=elmpredict(p,iw,b,lw,tf,type)函数完全彻底的解释了公式t=[t1,t2,…,tq]m×q。
在实际应用过程中,只需要将应用样本的高垮比值、采空体积、埋藏深度、悬顶面积、柱面比值、采矿扰动和相邻采空七个指标组成输入向量p,输入elmpredict函数,就可以得出结果。如果输出结果y为(1,1),则采空区冒落危险等级设定为事故状态;如果输出结果y为(1,0),则采空区冒落危险等级设定为隐患状态;如果输出结果y为(0,1),则采空区冒落危险等级设定为临界状态;如果输出结果y为(0,0),则采空区冒落危险等级设定为安全状态。
现有一房采工作面,高垮比值为0.2,采空体积为6000m3,埋藏深度为200m,悬顶面积为2980m2,柱面比值为0.18,采矿扰动为4,相邻采空为4。应用采空区冒落危险极限学习机预判识别模型,输出结果y为(1,0),则采空区冒落危险等级设定为隐患状态。在实际生产过程中,该面发生了顶板大面积突然冒落,造成一名工人从高处坠落导致抢救应用无效死亡,影响正常生产一周,直接经济损失300万元。
- 还没有人留言评论。精彩留言会获得点赞!