基于“量‑型”混沌相似原理的中长期水文预报模型的制作方法
本发明涉及水文预报预测领域,尤其涉及一种基于“量-型”混沌相似原理的中长期水文预报模型。
背景技术:
水文预报预测是防洪减灾和水资源利用的技术基础,但一直以来都是水文领域难以攻克的问题之一,水文系统受到下垫面条件变化、气候变化、人类活动等因素影响,是一个复杂的非线性系统。特别是随着预见期的增长,水文过程的非线性特征更加明显,传统水文预报方法难以满足预报精度要求。根据调研发现,水文时间序列具有一定的混沌特征,可以采用混沌预测方法进行预测,通过相空间重构技术将一维时间序列转化为多维相空间,将原序列中蕴藏的信息充分挖掘出来,从而实现水文预报预测。
混沌相空间相似点模型是基于混沌理论的一种预测方法,以与预测中心点的欧式距离来描述相点的相似性。对水文预测问题,如月降雨量预测,每个相点由m维月降雨量(m维坐标)组成,按欧氏距离大小度量相似程度就是意味着两个相点在各个维度对应的月降雨量相近,这实质上相当于一种“量”的相似,“量”相似考虑的是相点的整体相似性,但没有反映相点内部结构的相似程度,如对两个相点m维月雨量在时序上的升/降变化趋势是否一致或相近,无法描述。即使相点之间的欧式距离较小,相点结构也可能会有天壤之别,采用这些相似相点可能会导致最终预报效果不好。
技术实现要素:
本发明的目的为了解决现有技术的不足,本发明提供一种基于“量-型”混沌相似原理的中长期水文预报模型,通过综合考虑相空间中两个相点在“空间位置”和“内部结构”层面的相似程度,建立了双目标约束下的相似点寻优模型,以用于水文混沌预测,可有效提高水文时间序列的预报精度。
为了解决上述技术问题,本发明的技术方案为:一种基于“量-型”混沌相似原理的中长期水文预报模型,其特征在于,包括如下步骤:
步骤1:混沌特性识别,判断水文时间序列具有混沌特性:采用饱和关联维数法进行定量判断,若吸引子关联维数随着嵌入维数增加时趋于饱和,说明该水文时间序列具有混沌特征;
步骤2:相空间重构:采用自相关函数法和g-p算法确定相空间重构参数;
步骤3:混沌预测:应用双目标优化寻找相似点,采用“量”-“型”耦合的相似预测模型进行预报。
进一步的,步骤2包括以下步骤:
步骤2.1:对水文时间序列{x(1),x(2),...,x(n)},根据自相关函数法确定时间延迟τ;
步骤2.2:根据g-p算法,确定饱和关联维数d和嵌入维数m。
进一步的,根据g-p算法,给定一超球面半径r,距离小于r的相点点对数在所有相点点对中所占比例记为吸引子的关联函数cm(r),计算方法如下:
式中,n为总相点数,f为heaviside单位函数,y(i)、y(j)为相点点对,r为超球面半径。
根据水文时间序列具有混沌特征,确定饱和关联维数d和嵌入维数m,计算方法如下:
进一步的,步骤3包括以下步骤:
步骤3.1:根据时间延迟τ和嵌入维数m重构相空间,将一维水文时间序列转化为m维相空间下的相点y(i)=(x(i),x(i+1),...,x(i+(m-1)τ)),其中i=1,2,...,n,n=n-(m-1)τ;
步骤3.2:计算各相点与预测中心相点y(n)的欧氏距离;
步骤3.3:计算各相点与预测相点y'(n+1)内部结构相似性得分;
步骤3.4:将以欧式距离描述两个相点的空间接近程度定义为相点的“量”相似,作为第一优化目标f1;以累积单位阶跃函数描述两个相点的内部结构相似程度定义为相点的“型”相似,作为第二优化目标f2,在第一目标最优解的集合中对第二目标寻优,得到满足两个优化目标的相似相点;
步骤3.5:在相空间rm中搜索与y(t)最相近的相点y(t'),则由下一个相点y(t′+t)进行y(t+t)的预测,寻找最相似的k个相点(k>m+1),再取其平均值预测y(t+t)。
进一步的,步骤3.3中所述计算各相点与预测相点y'(n+1)内部结构相似性得分,需根据下列公式计算,由于x(n+1)未知,y(n+1)的第m维坐标未知,但前m-1维的坐标是已知的,将这个相点作为预测相点y'(n+1),设两个相点分别为y1=(x1,x2,...,xm),y2=(x’1,x'2,...,x'm)。令con(j)=(xj-xj+1)/(x'j-x'j+1),则两个相点第j维的相似性,可用单位阶跃函数描述:
其中,j为m维相空间中嵌入维数序号;con(j)表示相点坐标变化趋势的一致性与否,若两个相点在第j维上坐标变化趋势一致,则con(j)>0,并记score(j)为1;反之,con(j)<0,score(j)为0;两个相点的相似度可用累积单位阶跃函数
进一步的,步骤3.4中按照第一优化目标,寻找与预测中心点欧式距离最小的相点,记为f1*,引入一个宽容度ξ>0,在前一目标函数最优值附近的某一范围进行优化,满足两个优化目标的相似相点计算方法如下:
式中,i为重构相空间中所有相点个数;i1为满足第一优化目标(即“量”相似目标)的相似相点个数;ξ为第一个目标函数所容许的宽容度;f1*为满足第一优化目标的相似相点;
本发明所达到的有益效果:本发明提供的一种基于“量-型”混沌相似原理的中长期水文预报模型,既考虑了相空间中两个相点的空间接近程度,又考虑了两个相点的内部结构相似程度,建立双目标相似点寻优模型用于水文混沌预测,有效提高了预报精度。
附图说明
图1为本发明一种基于“量-型”混沌相似原理的中长期水文预报模型的流程图;
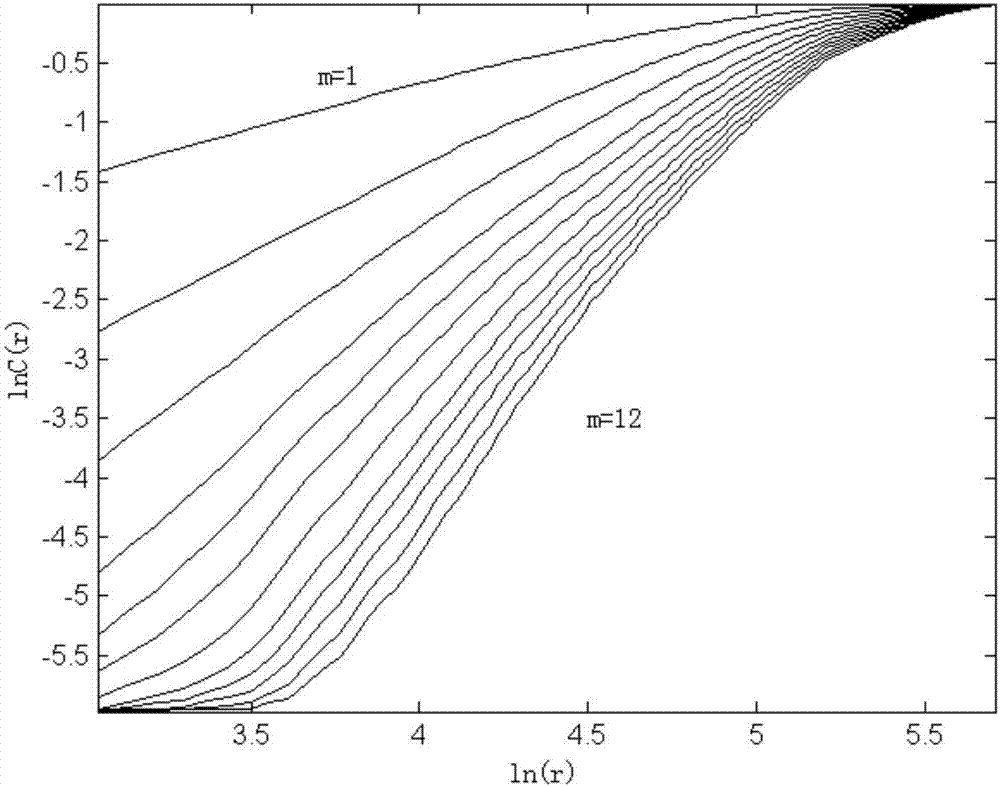
图2为某水文站月降雨系列关联函数与超球面半径的对数关系图
图3为某水文站月降雨系列的饱和关联维数图;
图4为传统相似点预测模型和“量”-“型”相似点预测模型结果散点图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
下面结合实例对本发明作更进一步的说明。
如图1所示,一种基于“量-型”混沌相似原理的中长期水文预报模型,其特征在于,包括如下步骤:
步骤1:混沌特性识别,判断水文时间序列具有混沌特性:采用饱和关联维数法进行定量判断,若吸引子关联维数随着嵌入维数增加时趋于饱和,说明该水文时间序列具有混沌特征;
步骤2:相空间重构:采用自相关函数法和g-p算法确定相空间重构参数;
步骤3:混沌预测:应用双目标优化寻找相似点,采用“量”-“型”耦合的相似预测模型进行预报。
具体实施过程如下:一种基于“量”-“型”混沌相似原理的水文时间序列预报模型,包括如下步骤:
(1)对水文时间序列{x(1),x(2),...,x(n)},根据自相关函数法确定时间延迟τ;
(2)根据g-p算法,给定一超球面半径r,距离小于r的相点点对数在所有相点点对中所占比例记为吸引子的关联函数cm(r)。
式中,n为总相点数,f为heaviside单位函数,y(i)、y(j)为相点点对,r为超球面半径。
若吸引子关联维数d随着嵌入维数增加时趋于饱和,说明该水文时间序列具有混沌特征,确定饱和关联维数d和嵌入维数m,计算方法如下。
(3)根据时间延迟τ和嵌入维数m重构相空间,将一维水文时间序列转化为m维相空间下的相点y(i)=(x(i),x(i+1),...,x(i+(m-1)τ)),其中i=1,2,...,n,n=n-(m-1)τ;
(4)计算各相点与预测中心相点y(n)的欧氏距离;
(5)计算各相点与预测相点y'(n+1)内部结构相似性得分,需根据下列公式计算。由于x(n+1)未知,y(n+1)的第m维坐标未知,但前m-1维的坐标是已知的,将这个相点作为预测相点y'(n+1)。设两个相点分别为y1=(x1,x2,...,xm),y2=(x’1,x'2,...,x'm),令con(j)=(xj-xj+1)/(x’j-x’j+1),则两个相点第j维的相似性,可用单位阶跃函数描述:
其中,j为m维相空间中嵌入维数序号;con(j)表示相点坐标变化趋势的一致性与否,若两个相点在第j维上坐标变化趋势一致(同升或同降),则con(j)>0,并记score(j)为1;反之,con(j)<0,score(j)为0;两个相点的相似度可用累积单位阶跃函数
(6)将以欧式距离描述两个相点的空间接近程度定义为相点的“量”相似,作为第一优化目标f1;以累积单位阶跃函数描述两个相点的内部结构相似程度定义为相点的“型”相似,作为第二优化目标f2。
(7)按照第一优化目标,寻找与预测中心点欧式距离最小的相点,记为f1*。引入一个宽容度ξ>0,在前一目标函数最优值附近的某一范围进行优化,按照下列公式在第一目标最优解的集合中对第二目标寻优,得到满足两个优化目标的相似相点。
式中,i为重构相空间中所有相点个数;i1为满足第一优化目标(即“量”相似目标)的相似相点个数;ξ为第一个目标函数所容许的宽容度;f1*为满足第一优化目标的相似相点;
(8)在相空间rm中搜索与y(t)最相近的相点y(t'),则由下一个相点y(t′+t)进行y(t+t)的预测。寻找最相似的k个相点(k>m+1),再取其平均值预测y(t+t)。
实施例:现有某一水文观测站点35年的月降雨量系列样本,共计420个月降雨量数据点;依据本发明方法,预报第36年各月降雨量的过程为:
(1)对水文时间序列{x(1),x(2),...,x(420)},根据自相关函数法,自相关函数首次下降到零点对应的滞时作为时间延迟τ,结果为τ=3。
(2)根据g-p算法,计算关联函数与超球面半径的对数关系曲线和关联维数与嵌入维数的关系曲线,分别如图2和图3所示。由于吸引子关联维数随着嵌入维数增加时趋于饱和,说明该水文时间序列具有混沌特征。选择饱和关联维数对应的嵌入维数作为相空间重构的最佳嵌入维数,计算得d=4.31、m=10。
(3)根据相空间重构参数τ=3、m=10,n=n-(m-1)τ=393,得到m维相空间下的393个相点。
(4)以第393个相点作为预测中心点,计算其他各相点与y(393)的欧氏距离。
(5)计算各相点与预测相点y’(394)的内部结构相似性得分。
(6)对第一个目标函数求解,得到最优解f1*=f(261)=115.02。然后在第一个目标函数的最优解集内求第二个目标函数的最优值,将第一个目标函数转化为辅助约束,此处取宽容度ξ=100,筛选出72个相似相点。再计算
传统的相空间相似点模型是以与预测中心点的欧式距离来判断相似点,本质上属于“量”相似。本发明通过构造一个累积单位阶跃函数,以度量两个相点内部结构的“型”相似,并采用宽容分层序列法求解,从而实现“量”-“型”耦合的混沌预测。以丹江口以上流域2016年的月降雨量预测为例,对提出的改进混沌预测模型进行了应用研究。结果表明,与传统的相似点预测模型相比,本发明方法预报的平均相对误差绝对值从44%降低到23%,模型预测精度有较明显提高,为月降雨预报提供了一种新途径。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!