一种商品合格率关联规则的挖掘方法和装置与流程
本发明涉及一种商品合格率关联规则的挖掘方法和装置。
背景技术:
检验检疫业务统计数据是对日常检验检疫业务所产生的数据的汇总与统计,从总体上反映一定时期检验检疫业务的运行状况,并支持从不同角度对检验检疫各项业务进行分析,包括检验检疫业务企业报检、集中审单、现场查验、检验检测等所产生的数据。
在日常的检验检疫业务中通常采用抽样检验的方式,全面的检测检验几乎无法做到;对给定批次的商品,并非每批都检验,挖掘进出口商品的质量规律,确定重点检验内容、检测项和风险程度,就成为大数据辅助质检部门解决这棘手问题的重要手段。
目前业内采用大数据分析来解读规则,较常见的是采用多维关联规则,但多维关联规则具有:
数据库表非常庞大、且对输入数据无筛查能力,导致无效或无关联变量信息过多产生,且算法模型生成易过于泛化,以及支持度较低时加入大量hash函数时,多维关联规则算法效率会非常低的缺点。
技术实现要素:
针对上述商品检验检疫商品大数据分析采用的多维关联规则数据庞大无筛查能力,效率低的技术问题,本发明提供一种使用决策树模型算法优化多维关联规则的方法和装置,具体如下:
一种商品合格率关联规则的挖掘方法,所述挖掘方法包括以下步骤:
a.获取原始训练数据集;
b.使用决策树算法对数据训练集进行特征分类,并提取出分类特征变量重要性数据集;
c.设置特征参数重要性阀值对步骤b得到的特征变量重要性数据集和调参数据交叉排除多维关联规则训练数据集干扰项,筛选得到纯净特征变量参数集;
d.对步骤c得到的纯净特征变量参数集通过多维关联规则得到商品合格率规则模型。
在上述技术方案的基础上,进一步的,所述步骤b使用决策树算法对数据训练集进行特征分类中所述决策树算法是c4.5决策树算法。
进一步的,一种商品合格率关联规则的挖掘的装置,其特征在于,包括:
存储模块,用于获取和存储原始训练数据集;
第一挖掘模块,用于使用决策树算法对数据训练集进行特征分类,并提取出分类特征变量重要性数据集;
第二挖掘模块,用于将设置特征参数重要性阀值对得到的特征变量重要性数据集和调参数据交叉排除多维关联规则训练数据集干扰项,筛选得到纯净特征变量参数集;
第三挖掘模块,用于将纯净特征变量参数集通过多维关联规则得到商品合格率规则模型。
本发明的优点在于:优化了关联规则模型的输入变量优化,同时利用决策树生成树的信息增益标准化后的值,避免了决策树面对连续变量及序列型数据的计算性能问题;无决策树生成树泛化剪枝优化问题。
附图说明
图1是本发明商品合格率关联规则的挖掘方法的流程示意图;
图2是本发明商品合格率关联规则的挖掘装置的结构示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的实力在附图中示出,其中自始至终相同或类似的标号表示相同或类似的原件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
如图1所示,种商品合格率关联规则的挖掘方法,所述挖掘方法包括以下步骤:
a.获取原始训练数据集;
b.使用决策树算法对数据训练集进行特征分类,并提取出分类特征变量重要性数据集;
c.设置特征参数重要性阀值对步骤b得到的特征变量重要性数据集和调参数据交叉排除多维关联规则训练数据集干扰项,筛选得到纯净特征变量参数集;
d.对步骤c得到的纯净特征变量参数集通过多维关联规则得到商品合格率规则模型。
其中步骤b具体如下:
b1:根据步骤a获取的训练集,判断所述训练集是多节点或单节点数据集,若是单节点数据集直接转入步骤d建立模型;
b2:设s是n个数据样本的集合,将样本集划分为c个不同的类
其中
假设属性a的所有不同值得集合为
其中,
信息增益gain
信息增益比作为划分训练数据集的特征,存在偏向于选择取值较多的特征问题,使用信息增益比(informationgainratio)可以对这一问题进行校正。这是特征选择的另一准则信息增益比
b3:选取信息增益比当前最大的构建当前子节点,并记录此特征分类参数;
b4:对应节点构建决策树遍历数据集,得到所有信息增益比。
b5:将信息增益比标准化后作为分类特征变量重要性数据集保存输出。
其中步骤c如下:
c1:输入步骤b得到的特征变量重要性数据集db及多维关联规则最小支持度;
c2:首先扫描数据集找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样;然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度;然后使用c1找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项。
定义如下:可表示成形如a→b的蕴涵式,a和b分别表示为规则的合取范式构成的逻辑公式,a∩b=∅。其主要参数有支持度与置信度。
(1)支持度s
事务集d中同时包含事务a和b的百分比,称为规则a→b具有支持度s。
支持度的计算方法为:
s(a→b)=包含a和b的事物数/事物总数×100%
(2)置信度c
事务集d中包含a的事务数与同时包含b的事务数的百分比,称为规则a→b具有置信度c。
置信度的计算方法为:
c(a→b)=包含a和b的事物数/包含a的事物数×100%
同时满足最小支持度和最小置信度的规则称为强关联规则,即在关联规则挖掘中所希望发现的关联规则。
c3:利用向下封闭属性,即如果一个项集是频繁项目集,那么它的非空子集必定是频繁项目集,频繁集的子集也一定是频繁集。依次类推,生成所有的频繁项目集,然后从频繁项目集中找出符合条件的关联规则。
c4:通过联合和剪枝两步,生成一个频繁集。例如:
1,其中lk-1为频繁集。合并只有最后一个元素不同的item,如
{1,2},{1,3},{1,4},{2,3},{2,4}
生成3-频繁项目集:
因为{1,2},{1,3},{1,4}除了最后一个元素以外都相同,所以求{1,2},{1,3}的并集得到{1,2,3},{1,2}和{1,4}的并集得到{1,2,4},{1,3}和{1,4}的并集得到{1,3,4}。但是由于{1,3,4}的子集{3,4}不在2-频繁项目集中,所以需要把{1,3,4}剔除掉。
2,合并后的集合,如果支持度不满足要求,则把该合并集合删除。
c5:对于所有满足最小支持度的频繁集,根据最小置信度得到强规则关联。
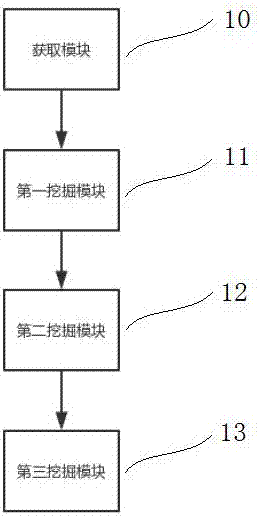
如图2所示,一种商品合格率关联规则的挖掘的装置,其特征在于,包括:
存储模块10,用于获取和存储原始训练数据集;
第一挖掘模块11,用于使用决策树算法对数据训练集进行特征分类,并提取出分类特征变量重要性数据集;
第二挖掘模块12,用于将设置特征参数重要性阀值对得到的特征变量重要性数据集和调参数据交叉排除多维关联规则训练数据集干扰项,筛选得到纯净特征变量参数集;
第三挖掘模块13,用于将纯净特征变量参数集通过多维关联规则得到商品合格率规则模型。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求极其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!