一种挖掘重叠社区动态演化关联规则的方法与流程
本发明涉及复杂网络重叠社区领域。
背景技术:
近年来,在线社交、邮件、生物等网络的兴起激起了学者们对网络演化分析的兴趣,使其成为新的研究热点。现实世界中的网络是不断演化的,对其动态演化的分析将揭示更多底层特性。该领域的研究分两类:第一类目的在于更新现有的挖掘算法,使结果与网络的状态一致。例如,研究如何更新重叠社区发现的结果,使重叠社区与变化后的网络保持一致;第二类目的在于研究特定类型的变化如何影响重叠社区和网络拓扑,从而深入理解网络演化并建立演化网络模型。网络的动态演化过程常用一组快照序列表示,每个快照对应一个静态网络,一个仅包含两个快照的网络演化过程如图1所示。
1959年,paul
在1998年,watts和strogatz在er图的基础上提出了一种新的网络演化模型,该模型首先将所有节点两两相连,构成一个环。然后,任意两节点之间以概率β生成新的边,生成边的过程不断地重复。用该模型生成的网络,具有了小世界性和社区结构等复杂网络应拥有的性质,但是节点的度服从均匀分布。然而在真实网络中,节点的度服从幂律分布。
除了静态网络的拓扑性质,网络演化的基本法则是优先连接(preferentialattachment),即一个节点与其余节点建立连接的概率与它的度成正比,满足该性质的模型是ba模型(ba,barabási-albert)。ba模型能很好地解释枢纽节点的形成,且所生成网络的度服从指数分布与真实网络匹配。但是,其假设高度节点持续存在于网络中,存在时间越长度越大,使得它们始终有很高的连接概率,而新生节点始终只有很小的连接概率。因此ba模型无法表示新节点也具有很大的连接概率的情况。因此bianconi等人提出给每个节点引入一个适应度参数η,以描述节点的质量、能力或活跃度等。η和度k共同决定连接概率。因此,即使新节点的度较低,但是若具有较高的η,该节点也能在短时间内生成大量边。例如,在早期的www网络中,google搜索页面作为一个新生节点在很短的时间内获得了大量链接。该适应度模型已考虑了节点度分布的不均匀性且考虑了节点固有的η属性,但所生成的网络无社区结构且假设节点η保持不变,因而不能匹配某些网络的动态演化过程。
一种更好的模型是随机块模型(sbm,stochasticblockmodel),常用于统计学和社交网络分析领域。给定块个数k,将节点分配到这k个块。块内节点间的边生成概率为ψi,块i与另一个块j的节点之间生成边的概率为ψij。因而,可以得到随机块概率矩阵,描述整个网络任意两节点之间的互连概率。sbm模型具有简单、灵活、易于扩展的特点,且使用不同类型的概率矩阵可以生成不同类型的网络。例如,采用对角元素非零、非对角元素为零的概率矩阵,将生成一个包含k个独立子图的网络;对角元素大而非对角元素较小的随机块可以生成具有社区结构的网络;按照主对角线到次对角线的顺序递减概率可以得到一个包含层次社区结构的网络。通过使用后验概率块建模的方法,可以实现社区发现。然而,简单的随机块模型并没有考虑节点度分布的不均匀特点和社区大小分布,与真实网络的匹配不准确。随机块模型要求指定块数限制了其应用范围。
以上所讨论的研究以理解和建模网络演化的一般法则为目标,例如优先连接和增长性等。此外,还存在以节点演化、重叠社区演化、参数演化、角色动态演化等为研究对象的网络演化分析方法,从其他角度分析网络演化的过程。例如,berlingerio等人将关联规则框架应用于网络演化分析,提出了一种挖掘节点的动态演化规则的方法,得到节点的常见演化模式。该方法通过将所有快照压缩为一个网络并给边加上时间戳,再应用dfs策略搜索与一个模式同构的子图实现挖掘,然而这种方法不能得到重叠社区的不同演化事件之间的关联。
技术实现要素:
本发明通过挖掘复杂网络中重叠社区动态演化中的“增长分裂”、“合并后增长”等特定演化序列,给出一种动态演化关联规则的方法,从而有助于深入理解重叠社区动态特征并且预测其演化,为理解复杂网络重叠社区动态演化的底层机制提供一种新的分析工具。
为此,本发明给出以下技术方案实现:
本发明研究方法,其特征在于,以重叠社区作为节点、改变点作为边进行社区演化图建模。基于关联规则挖掘框架定义演化子图模式、支持度、社区演化规则及置信度。根据dfs策略搜索得到所有支持度高于一定阈值的子图从而生成重叠社区动态演化关联规则。
有益效果
本发明基于一种复杂网络中挖掘重叠社区动态演化关联规则的方法,有如下有益效果。
虽然目前对网络、社区及节点的动态演化已经有了大量研究,但是依然没有人提出一种挖掘重叠社区动态演化规则的方法。本发明得到的重叠社区动态演化关联规则揭示了重叠社区动态演化的模式,具有较好的预测重叠社区未来演化的能力,是一种复杂网络中重叠社区动态演化的新的分析工具。
附图说明
图1网络的一次动态演化过程。
图2重叠社区演化图。
图3重叠社区演化图中的同构子图。
图4存在一条路径的子图间可达性。
图5存在公共部分的子图间可达性。
图6为本发明方法流程图。
图7为算法1流程图。
图8为算法2流程图。
图9为算法3流程图。
具体实施方式
本发明的具体实施过程包括如下3个方面:
①以重叠社区作为节点、改变点作为边进行社区演化图建模
②基于关联规则挖掘框架,定义演化子图模式、支持度、社区演化规则及置信度
③搜索所有支持度高于一定阈值的子图,从而生成重叠社区动态演化关联规则,并计算置信度
①
以重叠社区作为节点、改变点作为边进行社区演化图建模
一个重叠社区演化图(简称“社区演化图”)eg=(v,e)是定义在演化网络
1)一个重叠社区作为图中的一个节点。每个节点关联相应社区的节点数。
2)演化图eg划分为n个分区,gi中的社区对应第i分区中的节点,且所有分区按时间顺序排列。
3)对两个相邻分区中的节点
4)每条边可以关联五种改变事件类型,即合并、分裂、增长、缩小和消失。每条边必须介于两个相邻分区的节点之间。
5)为了表示社区消亡事件,用一个特殊节点表示已经消失的社区。
6)演化图eg至少包含两个分区。
通过重叠社区演化图建模,可以将所有社区及改变点统一表示为一个抽象的图(graph),如图2所示。其中,重叠社区演化图中节点的大小对应社区成员节点个数。
②
基于关联规则挖掘框架,定义演化子图模式、支持度、社区演化规则及置信度
由于没有定义相同分区中的社区之间的边并且图中不存在回路,因而重叠社区演化图也可以视为森林。在这样的森林结构中,每棵树都是社区演化图的一个子图,代表了一部分重叠社区演化历史。为了分析和挖掘社区演化图中的局部演化事件,本发明定义重叠社区演化子图如下:
定义1重叠社区演化子图:重叠社区演化子图是定义在演化网络
1)seg至少包含一个入度为0的节点,称为源节点。
2)seg包含多个出度为0的节点,称为目的节点。
3)seg是一个连通子图,即
4)seg中不存在回路,因而seg图也可以视为一棵树。
5)seg图可以只包含社区生命期的一部分,将其起始时间记为ts,结束时间记为te(1≤ts,te≤n)。
重叠社区演化子图从局部角度描述了一个社区的演化序列及其后影响的社区。在分析dblp和twitter等网络时,发明人发现在社区演化图中,经常存在许多同构的子图,例如图3所示。这表明社区的动态演化存在频繁出现的演化关联规则,本发明将之称为频繁演化模式(frequentevolutionpattern)。为找到频繁演化模式,在重叠社区演化子图基础上进一步定义社区演化模式如下:
定义2演化子图模式:给定重叠社区演化图
1)
2)
3)
其中,函数
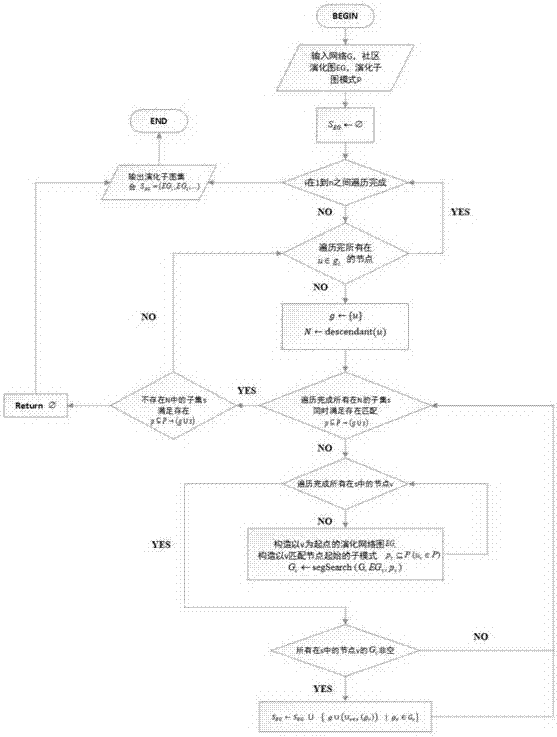
通过迭代搜索各分区和基于回溯法的策略,本发明给出演化子图搜索算法,如算法1所示的流程图7。
算法1演化子图搜索算法(segsearch)
1.输入网络
2.进行赋值操作:
3.对i从1到n进行遍历,检查是否遍历完成,若遍历未完成,则进行下一步操作;否则,跳到步骤18。
4.对所有的u∈gi子节点进行遍历,检查是否遍历完成,若遍历未完成,则进行下一步;否则跳到步骤17。
5.进行赋值操作:g←{u},n←descendant(u)。
6.对所有满足下列条件的子集进行遍历:
7.对所有的v∈s子节点进行遍历,检查是否遍历完成,若遍历为完成,则进行下一步;否则跳到步骤11。
8.构造以v为起点的演化网络图egv。
9.构造以v匹配节点uv起始的子模式
10.进行赋值操作:gv←segsearch(g,egv,pv),返回步骤7。
11.如果所有节点v∈s的gv非空,则进行下一步操作;否则跳到步骤13。
12.进行赋值操作:seg←seg∪{g∪(∪v∈s(gv))|gv∈gv}。
13.返回步骤6。
14.如果不存在子集
15.跳到步骤18,返回空集。
16.返回步骤4。
17.返回步骤3。
18.输出演化子图集合seg={eg1,eg2,...},其中每个egi都匹配p。
19.结束程序。
在算法1中,与模式p相匹配的子图集合为seg,它首先初始化为空集。然后,按顺序遍历各分区中的节点u,令它与模式p中的源节点up匹配,并且将u的后继节点放入集合n。接下来在第6行的循环中,遍历n的所有的子集s且只考虑大小为|descendant(up)|的子集。在第7~10行的循环中,如果节点u合并s之后,与up合并其后继节点的子图匹配,则在以v∈s为起点的社区演化图中,搜索子模式pv,即进行递归调用。对于子集s中的每个节点v,可能返回多个匹配子模式pv的子图,这些子图用gv表示。当集合s中的所有节点处理完成并且各节点v所对应的集合gv均非空时,从每个集合gv中选择一个子图,将它与g合并,从而得到与模式p匹配的社区演化子图。在算法1的第13行中,如果存在多种组合方式时,则将这些组合的演化子图都存入seg。如果子集s中有任何节点的gv为空,说明后半部分无法匹配,此时舍弃s。
为了量化社区演化子图的出现次数,本发明定义社区演化子图支持度如下:
定义3演化子图支持度:给定社区演化图eg(v,e)和演化子图模式p(vp,ep),则p在eg中的支持度为一个函数
其中,fp表示p在eg中的一次出现,v是p中的一个节点,uv是p在eg中的一次出现,即p所匹配的子图中u所映射到的节点,
由上述定义可知,模式p在社区演化图eg中的支持度σ(eg,p)等于p中的每个节点所映射到的不同节点个数的最小值。所以,σ(eg,p)并不等于模式p所匹配的子图个数。实际上,该定义是基于最小镜像的支持度。我们没有直接采用模式p匹配到的演化子图个数而采用最小镜像支持度作为支持度,这是为了让它满足反单调性,从而使后面的搜索算法能尽量裁剪搜索空间,提高执行效率。除了最小镜像支持度以外,还存在其它的子图模式支持度定义,但是使用它们需要解决np完全的最大独立集问题(mis,maximalindependentset),因而无法得到最优解从而计算支持度的准确值。
上面的支持度定义只描述了一个模式的出现次数,没有描述两个模式间的关联。除了存在频繁演化模式之外,不同的演化子图之间还存在动态关联。例如,一种模式pa出现后,在接下来的时间内,相关的社区可能按照pb的方式演化,此时pa间接导致了pb,因而pa与pb存在关联。为了挖掘出子图模式间的关联,首先定义子图之间的可达性,因为存在关联的子图之间通常是可达的。假设a(va,ea),b(vb,eb)分别为社区演化图eg中的子图,
定义4演化子图规则和置信度:给定社区演化图eg,子图模式pa和pb,演化子图a和b分别与模式pa和pb匹配,则演化子图规则即重叠社区演化关联规则定义为蕴含式
且同时满足以下条件:
1)pa的支持度大于最小支持度阈值∈,即σ(eg,pa)≥∈。
2)演化子图a可达于b,即a°b。
3)该规则的支持度为模式pa的支持度,即
4)该规则服从一定的置信度,记为
演化子图关联规则描述了两种子图模式在社区演化图中的关系,而它的置信度则可以度量在整个数据集中满足这种关系的规则占总数据的比值,帮助判断我们发现的关联规则的可信度。根据经典的关联规则框架,一种较为直接的演化子图关联规则的置信度定义为:
其中,pa∪pb表示pa和pb同时出现,即
support(pa∪pb)=σ(eg,pa∪pb)(2)
根据前面的定义可知,支持度必须满足反单调性,因而必然有σ(eg,pa∪pb)≤σ(eg,pa)且σ(eg,pa∪pb)≤σ(eg,pb)。因此,该置信度满足条件
从而使它适合用于度量社区演化规则的有意义性(interestingness)。实际上,演化子图规则的置信度为在pa发生之后pb也发生的概率,如果这个概率越大说明pa与pb之间的关联越强,反之亦然。在实际的挖掘应用中,置信度低于最小阈值的规则将被视为无效的因而被舍弃。
从公式(1)可以看出,演化子图关联规则的置信度取决于支持度σ(eg,pa)和σ(eg,pa∪pb)。通过搜索得到在社区演化图eg中分别匹配pa和pa∪pb的子图集合{a1,a2,...,am}和{b1,b2,...,bn}后,生成关联规则并检验其置信度将十分容易。
③
搜索所有支持度高于一定阈值的子图,从而生成重叠社区动态演化关联规则
重叠社区演化关联规则挖掘问题也可以分为两步:1)在社区演化图中挖掘支持度高的演化子图模式;2)搜索匹配一个模式的所有演化子图,生成演化子图规则并检验其置信度。其中,第二个问题已经在算法1中解决。第一个问题解决如下:
给定包含n个节点的图,在不考虑边的情况下,该图的子图数量为
这表明,子图的搜索空间是指数级的,因而不能直接遍历子图。然而,与传统研究者提出的子图挖掘不同,本发明社区演化图eg中的节点代表重叠社区而边代表演化事件,因而不存在高度节点,使得搜索空间较小。另外,对于节点数过多或过于复杂的演化子图,我们也无法对该规则进行分析从而得出有意义的关于社区动态演化的结论。因此,本发明设定节点数限制
算法2演化子图挖掘(segmining)
1.输入社区演化图eg(v,e),最大节点数ξ。
2.将eg中“合并”类型的边反向。
3.检查是否将v中所有的u遍历完成,未完成则进行下一步操作;否则跳到步骤5。
4.进行赋值操作:g←{u},s←segexpanding(eg,g,ξ)。返回步骤3。
5.恢复eg中“合并”类型边的方向。
6.输出演化子图集合seg={g1,g2,...},其中
7.结束程序
在演化子图挖掘算法中,针对一个子图进行扩展如图9所示的算法3。本发明基于深度优先搜索的策略(dfs,depthfirstsearch),从一个节点出发寻找所有与之连通的子图,并返回支持度大于最小支持度的子图。在搜索过程中,计算构造中的子图的支持度,当发现支持度较高的子图时将它存入集合seg,且舍弃支持度低的和重复的子图。当子图节点个数到达最大节点数ξ时停止进一步扩展。
算法3演化子图扩展(segexpanding)
1.输入社区演化图eg,演化子图g,最大节点数ξ。
2.如果nodescount(g)=ξ,则进行下一步操作;否则跳到步骤4。
3.进行赋值操作:seg←seg∪{g},然后跳到步骤9,返回seg的值。
4.将g中所有节点的后一级节点放入集合
5.检查是否遍历完所有的子集
6.如果support(g∪w)≥minsupport,则进行下一步;否则跳到步骤。
7.进行相关操作:c←g∪w,segexpanding(eg,c,ξ)。
8.返回步骤5。
9.输出对应的演化子图集合seg={g1,g2,...},其中
10.结束程序
通过执行算法3,可以得到在一个社区演化图中支持度较高的所有子图模式,放入集合seg。然后,对于seg中的任意两个子图模式seg1和seg2,判断seg1是否可达于seg2,即
创新点
提出了一种进行重叠社区动态演化的新的分析工具。
针对目前对重叠社区演化的研究局限于检测其合并、分裂、收缩、增长等动态事件,分析其演化的稳定性等,没有给出一种挖掘重叠社区动态演化关联规则的方法,也无法根据重叠社区过去的演化事件预测未来发生的变化等问题。挖掘其演化中的“增长分裂”、“合并后增长”等特定演化序列,给出一种复杂网络中挖掘重叠社区动态演化关联规则的方法,从而有助于深入理解重叠社区动态特征并且预测其演化,是一种进行重叠社区动态演化分析的重要工具。
- 还没有人留言评论。精彩留言会获得点赞!