一种基于视频分析的新生儿疼痛表情识别方法与流程
本发明涉及一种基于视频分析的新生儿疼痛表情识别方法,属于视频分析与模式识别技术领域。
背景技术:
以往医学界认为新生儿没有疼痛感,所以一直未对新生儿疼痛予以重视。但是近年来医学研究证实,反复的疼痛刺激会对新生儿,尤其是早生儿和危重儿产生一些近期和远期的影响。疼痛是一种主观感受,自我评估被认为是最可靠的评估疼痛方法。但由于新生儿不能像成人一样用语言表达疼痛的感受,所以正确评估和积极处理新生儿疼痛具有重要的临床意义。在常用的新生儿疼痛评估工具中,“面部表情”被认为是最可靠的疼痛监测指标。
目前国际上对新生儿疼痛的评估都是由受过专门训练,并熟悉各项评估技术指标的医护人员进行人工评估,但人工评估耗时费力,而且评估结果往往受到主观因素的影响。因此,开发一种基于面部表情的新生儿疼痛自动评估系统是非常有意义和价值的。
南京邮电大学卢官明教授带领的课题组曾采用基于局部二值模式(lbp)和稀疏表示分类相结合的识别方法,对新生儿的疼痛与非疼痛表情的分类进行了研究,取得了较为满意的识别性能。但前期开展的有关新生儿疼痛表情识别研究主要面向静态图像,实验所用的表情图像都是经人工裁剪、对齐、尺度归一化和灰度均衡化等处理后得到的。尽管实验结果取得了较高的识别率,但算法的泛化能力有限,与实际临床的疼痛评估还有很大的差距。因为在临床应用中,疼痛评估系统面向摄像机采集的监控视频,而不是预先归一化后的静态图像。
技术实现要素:
本发明所要解决的技术问题是提供一种基于视频分析的新生儿疼痛表情识别方法,能够解决现有技术不能有效识别新生儿疼痛表情的问题,为开发客观准确的新生儿疼痛自动评估系统提供新的途径。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于视频分析的新生儿疼痛表情识别方法,包括如下步骤:
步骤a.采集新生儿分别对应预设各个疼痛程度等级的各个样本疼痛等级表情视频,并进入步骤b;
步骤b.分别针对各个样本疼痛等级表情视频,具体针对样本疼痛等级表情视频进行剪辑,获得各个表情图像帧,进而获得各个样本疼痛等级表情视频分别所对应的各组样本表情图像帧,并统一各组样本表情图像帧的帧长度l,以及统一所有表情图像帧的分辨率h×w,然后进入步骤c;
步骤c.构建三维卷积神经网络,并采用各组样本表情图像帧,以及分别所对应的疼痛程度等级作为训练样本,针对三维卷积神经网络进行训练,获得对应于新生儿表情识别的三维卷积神经网络,然后进入步骤d;
步骤d.采集新生儿实际表情视频,并进行图像帧调整,然后采用对应于新生儿表情识别的三维卷积神经网络,针对新生儿实际表情视频进行识别,获得所对应的疼痛程度等级。
作为本发明的一种优选技术方案:所述预设各个疼痛程度等级包括新生儿平静状态、新生儿啼哭状态,以及因致通性操作所导致的新生儿轻度疼痛状态、新生儿剧烈疼痛状态。
作为本发明的一种优选技术方案:所述步骤c中,采用各组样本表情图像帧,以及分别所对应的疼痛程度等级作为训练样本,通过反向传播算法针对三维卷积神经网络进行训练。
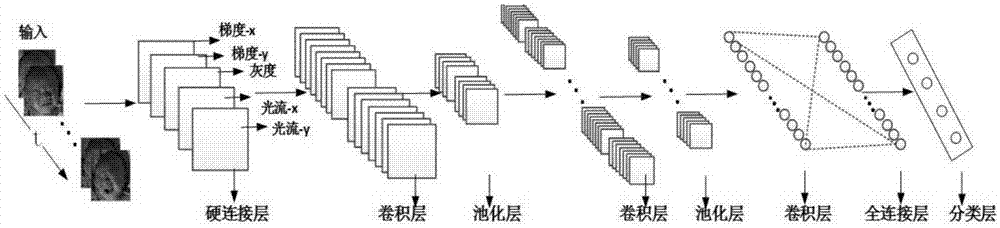
作为本发明的一种优选技术方案:所述步骤c中构建的三维卷积神经网络由输入开始,依次包括第一层硬连接层、第二层卷积层、第三层池化层、第四层卷积层、第五层池化层、第六层卷积层、第七层全连接层和第八层分类层,所述各组样本表情图像帧依次经过三维卷积神经网络中的各层,获得表情图象帧分类,并结合各组样本表情图像帧分别所对应的疼痛程度等级,针对三维卷积神经网络进行训练,获得对应于新生儿表情识别的三维卷积神经网络;
所述步骤d中,采集新生儿实际表情视频,获得所对应的表情图像帧,并调整该新生儿实际表情视频所对应表情图像帧的帧长度为l,以及调整该新生儿实际表情视频所对应各表情图像帧的分辨率为h×w,然后将新生儿实际表情视频所对应的表情图像帧,依次经过对应于新生儿表情识别的三维卷积神经网络中的各层,获得该新生儿实际表情视频的分类,即获得该新生儿实际表情视频所对应的疼痛程度等级。
作为本发明的一种优选技术方案:所述三维卷积神经网络中由输入开始,依次所包括各个层如下:
第一层硬连接层,提取新生儿表情视频所对应各表情图像帧中的灰度、水平方向梯度、垂直方向梯度、水平方向光流和垂直方向光流等特征;
第二层卷积层,采用d1×k1×k1的3d卷积核,针对第一层硬连接层所输出多个通道的特征进行卷积操作,获得l1个分辨率为h1×w1的二维特征图,其中,l1=m1×[(l-d1+1)×3+(l-1-d1+1)×2],
第三层池化层,采用预设尺寸k2×k2的采样窗口,针对上一层卷积层所获的二维特征图进行下采样操作,获得l1个分辨率为h2×w2的二维特征图;其中,
第四层卷积层,采用d3×k3×k3的3d卷积核对上一层池化层的输出进行卷积操作,获得l2个分辨率为h3×w3的二维特征图;其中,k3×k3表示本层中3d卷积的空间维大小,d3表示本层中3d卷积的时间维大小,l2=m1×m3×{[(l-d1+1)-d3+1]×3+[(l-1-d1+1)-d3+1]×2},
第五层池化层,采用预设尺寸k4×k4的采样窗口,针对上一层卷积层所获二维特征图进行下采样操作,获得l2个分辨率为h4×w4的二维特征图;其中,
第六层卷积层,采用h4×w4的卷积核,针对上一层池化层的输出,按预设卷积步长为1,在空间维度上进行卷积操作,获得l2个分辨率为1×1的二维特征图;
第七层全连接层,获得上层卷积层的输出结果作为全连接层的输入,且该全连接层的输入节点数为l2个,该全连接层节点与上层卷积层所输出各个二维特征图进行全连接,进而获得该新生儿表情视频所对应的l2维特征向量;
第八层分类层,接收上一层全连接层输出的l2维特征向量,并采用预设分类器进行分类识别,即完整针对该新生儿表情视频的识别。
作为本发明的一种优选技术方案:所述第八层分类层中,针对上一层全连接层输出的l2维特征向量,采用softmax分类器进行分类识别。
本发明所述一种基于视频分析的新生儿疼痛表情识别方法采用以上技术方案与现有技术相比,具有以下技术效果:本发明设计的一种基于视频分析的新生儿疼痛表情识别方法,通过引入基于三维卷积神经网络的深度学习方法,将其运用于新生儿疼痛表情识别工作中,能够有效识别出新生儿处于安静、啼哭状态以及致痛性操作引起轻度疼痛、剧烈疼痛等表情,为开发新生儿疼痛自动评估系统提供一种新的途径,具体引入三维卷积神经网络,通过3d卷积核提取视频片段的时域和空域特征,避免人工提取特征的繁琐,且所提取特征更具优越性,并且在深度学习平台上自动学习并识别新生儿疼痛表情,与传统人工评估方式相比,更加客观,更加准确,并且节省了大量人力资源。
附图说明
图1是本发明所设计一种基于视频分析的新生儿疼痛表情识别方法的示意图;
图2是本发明所设计三维卷积神经网络的结构图;
图3是本发明所设计新生儿各个疼痛程度等级的表情图像帧。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
本发明将深度学习理论拓展应用到动态视频中的表情识别领域,针对面向临床应用的新生儿疼痛表情识别关键技术问题,提出一种基于视频分析的新生儿疼痛表情识别方法,其中基于三维卷积神经网络(3dcnn)进行实现,以突破在传统的表情识别方法中人工设计与提取显式表情特征的技术瓶颈,提高在面部受遮挡、姿态倾斜、光照变化等复杂情况下的识别率和鲁棒性。
如图1所示,本发明设计了一种基于视频分析的新生儿疼痛表情识别方法,实际应用中,具体包括如下步骤:
步骤a.采集新生儿分别对应预设各个疼痛程度等级的各个样本疼痛等级表情视频,并进入步骤b。其中,各个疼痛程度等级包括新生儿平静状态、新生儿啼哭状态,以及因致通性操作所导致的新生儿轻度疼痛状态、新生儿剧烈疼痛状态,如图3所示。
步骤b.分别针对各个样本疼痛等级表情视频,具体针对样本疼痛等级表情视频进行剪辑,获得各个表情图像帧,进而获得各个样本疼痛等级表情视频分别所对应的各组样本表情图像帧,并统一各组样本表情图像帧的帧长度l,以及统一所有表情图像帧的分辨率h×w,然后进入步骤c。
步骤c.构建三维卷积神经网络,如图2所示,三维卷积神经网络由输入开始依次包括第一层硬连接层、第二层卷积层、第三层池化层、第四层卷积层、第五层池化层、第六层卷积层、第七层全连接层和第八层分类层,采用各组样本表情图像帧,以及分别所对应的疼痛程度等级作为训练样本,通过反向传播算法针对三维卷积神经网络进行训练,其中,所述各组样本表情图像帧依次经过三维卷积神经网络中的各层,获得表情图象帧分类,并结合各组样本表情图像帧分别所对应的疼痛程度等级,针对三维卷积神经网络进行训练,获得对应于新生儿表情识别的三维卷积神经网络,然后进入步骤d。
其中,三维卷积神经网络中由输入开始,依次所包括各个层如下:
第一层硬连接层,提取新生儿表情视频所对应各表情图像帧中的灰度、水平方向梯度、垂直方向梯度、水平方向光流和垂直方向光流等特征,基于上述各组样本表情图像帧所包括的12帧表情图像帧,形成12×3+(12-1)×2=58个二维特征图,其中,12个灰度特征图,12×2=24个梯度特征图和(12-1)×2=22个光流特征图,这五种特征在网络中形成了五个通道,然后对这几个通道分别进行处理。
第二层卷积层,采用d1×k1×k1的3d卷积核,针对第一层硬连接层所输出多个通道的特征进行卷积操作,获得l1个分辨率为h1×w1的二维特征图,其中,l1=m1×[(l-d1+1)×3+(l-1-d1+1)×2],
第三层池化层,采用预设尺寸k2×k2的采样窗口,针对上一层卷积层所获的二维特征图进行下采样操作,获得l1个分辨率为h2×w2的二维特征图;其中,
第四层卷积层,采用d3×k3×k3的3d卷积核对上一层池化层的输出进行卷积操作,获得l2个分辨率为h3×w3的二维特征图;其中,k3×k3表示本层中3d卷积的空间维大小,d3表示本层中3d卷积的时间维大小,l2=m1×m3×{[(l-d1+1)-d3+1]×3+[(l-1-d1+1)-d3+1]×2},
第五层池化层,采用预设尺寸k4×k4的采样窗口,针对上一层卷积层所获二维特征图进行下采样操作,获得l2个分辨率为h4×w4的二维特征图;其中,
第六层卷积层,采用h4×w4的卷积核,针对上一层池化层的输出,按预设卷积步长为1,在空间维度上进行卷积操作,获得l2个分辨率为1×1的二维特征图。
第七层全连接层,获得上层卷积层的输出结果作为全连接层的输入,且该全连接层的输入节点数为l2个,该全连接层节点与上层卷积层所输出各个二维特征图进行全连接,进而获得该新生儿表情视频所对应的l2维特征向量。
第八层分类层,接收上一层全连接层输出的l2维特征向量,并采用softmax分类器进行分类识别,即完整针对该新生儿表情视频的识别。
步骤d.采集新生儿实际表情视频,获得所对应的表情图像帧,并调整该新生儿实际表情视频所对应表情图像帧的帧长度为l,以及调整该新生儿实际表情视频所对应各表情图像帧的分辨率为h×w,然后将新生儿实际表情视频所对应的表情图像帧,依次经过对应于新生儿表情识别的三维卷积神经网络中的各层,获得该新生儿实际表情视频的分类,即获得该新生儿实际表情视频所对应的疼痛程度等级。
实际应用中,实际应用中,我们在医护人员对新生儿进行常规的侵入性、致痛性操作,例如洗澡、打预防针和采血的过程中,使用高清数码相机拍摄了一系列新生儿疼痛视频。我们随机选取了25个新生儿在不同状态下的面部表情视频,同时由受过专业培训的医护人员对拍摄视频中的新生儿疼痛级别进行评估,主要分为平静、轻度疼痛、剧烈疼痛、哭这四类表情状态。并对每类视频按所属类别进行标号,平静表情对应标号0,轻度疼痛表情对应标号1,剧烈疼痛表情对应标号2,哭表情对应标号3,并依次建立相对应表情的文件夹,将对应标记的新生儿表情视频依次放入。因此,共有4个文件夹,每个文件夹下应有25个不同新生儿的同类表情视频。对所有样本视频进行灰度化、尺度归一化等处理,将其分割成12帧表情图像帧,每个视频片段相互之间不重叠,并将视频帧图像统一大小,处理后的视频帧分辨率为128×128,得到统一大小后的视频片段。至此,新生儿面部表情视频库建立完毕。
对于三维卷积神经网络各层而言:
第一层硬连接层,提取新生儿表情视频所对应各表情图像帧中的灰度、水平方向梯度、垂直方向梯度、水平方向光流和垂直方向光流等特征,基于上述各组样本表情图像帧所包括的12帧表情图像帧,形成12×3+(12-1)×2=58个二维特征图,其中,12个灰度特征图,12×2=24个梯度特征图和(12-1)×2=22个光流特征图,这五种特征在网络中形成了五个通道,然后对这几个通道分别进行处理。
第二层卷积层,采用7×11×11的3d卷积核,针对第一层硬连接层所输出多个通道的特征进行卷积操作,卷积步长为3,在同一个位置使用2个不同的卷积核,可得到2组特征图,卷积后进行非线性映射,获得56个分辨率为40×40的二维特征图,其中,56=[(12-7+1)×3+(11-7+1)×2]×2,
第三层池化层,采用2×2尺寸的采样窗口,针对上一层卷积层所获的二维特征图进行下采样操作,滑动步长为2,获得56个分辨率为20×20的二维特征图;其中,
第四层卷积层,采用3×7×7的3d卷积核对上一层池化层的输出进行卷积操作,卷积步长为1,在同一个位置使用3个不同的卷积核,可得到3组特征图,卷积后再进行非线性映射,获得108个分辨率为14×14的二维特征图;其中,108=[((12-7+1)-3+1)×3+((11-7+1)-3+1)×2]×2×3,14×14=(20-7+1)×(20-7+1)。
第五层池化层,采用2×2尺寸的采样窗口,针对上一层卷积层所获二维特征图进行下采样操作,滑动步长为2,获得108个分辨率为7×7的二维特征图;其中,
第六层卷积层,由于时间维上帧数很少(灰度,水平方向和垂直方向梯度均为4帧,水平方向和垂直方向光流均为3帧),故只在空间维上卷积,采用7×7的卷积核,针对上一层池化层的输出,按预设卷积步长为1,在空间维度上进行卷积操作,获得108个分辨率为1×1的二维特征图,其中,1×1=(7-7+1)×(7-7+1)。
第七层全连接层,获得上层卷积层的输出结果作为全连接层的输入,且该全连接层的输入节点数为108个,该全连接层节点与上层卷积层所输出各个二维特征图进行全连接,进而获得该新生儿表情视频所对应的108维特征向量。
第八层分类层,接收上一层全连接层输出的l2维特征向量,并采用softmax分类器进行分类识别,即完整针对该新生儿表情视频的识别,其中,输出为样本x属于类别j的概率值
即在4个概率值中寻找最大值,将概率值最大的j所对应的类别作为样本x的分类结果,用class(x)表示。
上述所设计基于视频分析的新生儿疼痛表情识别方法,通过引入基于三维卷积神经网络的深度学习方法,将其运用于新生儿疼痛表情识别工作中,能够有效识别出新生儿处于安静、啼哭状态以及致痛性操作引起轻度疼痛、剧烈疼痛等表情,为开发新生儿疼痛自动评估系统提供一种新的途径,具体引入三维卷积神经网络,通过3d卷积核提取视频片段的时域和空域特征,避免人工提取特征的繁琐,且所提取特征更具优越性,并且在深度学习平台上自动学习并识别新生儿疼痛表情,与传统人工评估方式相比,更加客观,更加准确,并且节省了大量人力资源。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!