一种基于图像分析和深度学习的人数统计方法与流程
本发明涉及图像目标识别和深度学习技术领域,尤其是一种基于图像分析和深度学习的人数统计方法。
背景技术:
利用计算机视觉技术对监控图像或视频进行人数统计,可广泛应用在如踩踏预警、交通疏导、商铺人流评估、出勤率统计等项目场景中。然而目前已有的人数统计系统在拥挤环境下常常具有较大的误差。这是因为在拥挤环境下通常有大量遮挡的情况出现,导致人体肩膀以下的部位的特征几乎无法得到可靠有效的利用。而如果只对头肩进行特征提取和定位,由于头肩形状曲线相对简单,传统的手工设计的特征提取算法如hog、lbp、haar等,参见《histogramsoforientedgradientsforhumandetection》(n.dalalandb.triggs,inieeeconferenceoncomputervisionandpatternrecognition,2005),其所提取的特征很容易与一些身体其他部位或背景纹理形状的相应特征相混淆,产生大量的误检测。另一方面,基于深度学习的特征提取,参见《richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation》(r.girshick,j.donahue,t.darrell,etal,cvpr,2014)和《fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks》(s.ren,k.he,r.girshick,etal,nips,2015),已在很多图像分析领域超过了手工特征。但由于计算量大速度慢,尚未在实时性要求较高的监控场景中得到广泛应用。
技术实现要素:
本发明要解决的技术问题是提供一种基于图像分析和深度学习的人数统计方法,能够解决现有技术的不足,能够以较快的速度达到较高的人数统计性能。
为解决上述技术问题,本发明所采取的技术方案如下。
一种基于图像分析和深度学习的人数统计方法,包括以下步骤:
a、对输入图像进行金字塔模型计算,生成多个分辨率和尺寸的图像;
b、在金字塔的每一层上进行窗口滑动,计算窗口区域的hog特征值,并通过线性svm分类器进行分类,判断该窗口是否为头肩区域;
c、对于步骤b中给出的每个头肩区域,提取相应的图像,归一化到设定好的相同尺寸,输入到深度神经网络中,得到分类输出;
d、对步骤c的输出里的所有头肩窗口进行非极大值抑制,以合并相邻区域和尺度的重叠的检测结果。
作为优选,步骤a中,对原始图像进行高斯平滑,并生成分辨率下降10%的图像,并对新生成的低分辨率图像重复此过程,直到生成给定层数的金字塔模型。
作为优选,步骤b中,
对金字塔的每一层进行目标检测;检测过程中,用一个固定大小w×h的窗口在图像空间进行滑动,窗口下的图像区域计算hog特征并输入一个线性svm分类器中,获得是否为头肩目标的判断结果;在hog计算中,每个像素点(x,y)的水平、垂直梯度分别为
gx(x,y)=i(x+1,y)-i(x-1,y)
gy(x,y)=i(x,y+1)-i(x,y-1)
式中i(x,y)表示(x,y)处的像素值,像素点(x,y)的梯度幅值和方向则分别为
α(x,y)=tan-1(gy(x,y)/gx(x,y))
hog的计算是把窗口划分成很多细胞,每个细胞是4x4个像素,细胞与细胞之间不重叠,则对于每个细胞,相应特征的生成公式则为
ho(m,n)=∑4m≤x<4m+4,4n≤y<4n+4g(x,y)δo(x,y)/z
其中,ho(m,n)为梯度方向为o(0≤o<9)的在细胞(m,n)的特征值;z为某个归一化参数;hog计算每个块的特征并串联起来;这里,每个块则包括2x2个相邻细胞,块与块之间可重叠;每个块的特征包括其下每个细胞的归一化后的9个梯度方向的直方图,形成一个36维的特征;所有块的特征形成维度为36×(w/4-1)×(h/4-1)的hog特征。
作为优选,步骤c中,对步骤b获得的每个头肩区域,将区域内图像提取出来,放大或缩小到48x48的尺寸,送入深度神经网络中,获取是否为头肩目标的判断。
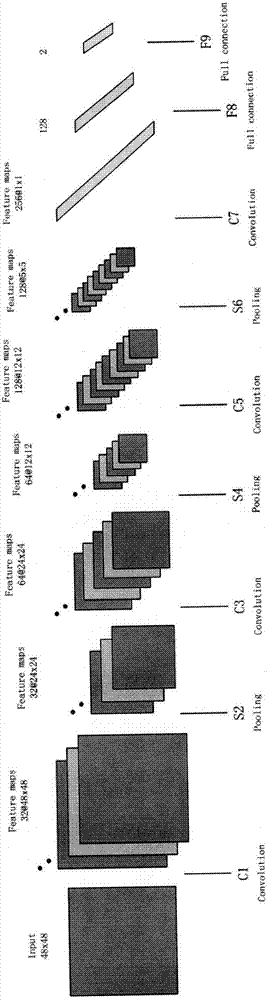
作为优选,所述深度神经网络包括3组卷积层与采样层、2个全连接层和1个输出层。
作为优选,卷积层的3d卷积操作中,对于卷积层的每个输出通道on的每个象素(x,y),
其中im为输入通道,m为输入通道数,hm,n为5x5的二维滤波器,αm,n为通道权重;hm,n与αm,n共同组成了一个3维滤波器;通过pca对im的5x5邻域进行主成分分析,则im可表示为多个主成分的加权和,
其中(i,j)属于(x,y)的5x5邻域,βk为第k个pca投影系数,uk为第k个pca主成分,k为主成分个数,则
其中,
采用上述技术方案所带来的有益效果在于:本发明所设计的深度神经网络采用了全新的结构,极大的减少了模型参数和提高了运算速度。与通常的基于深度学习的目标检测器不同,本发明抛弃了深度学习比较普遍采用的selectivesearch、rpn(regionproposalnetwork)等候选区域提取方法,而采用了传统的hog检测器的输出作为候选区域,对于拥挤环境下的头肩场景和小目标场景具有一定的优越性。对场景进行人工景深标定,大幅度减少hog检测的尺度空间搜索范围。本发明通用性好,对拥挤环境和非拥挤环境都具有良好的检测性能;因为采用了较简单的深度神经网络和pca分解加速、hog预筛选的机制、和人工景深标定,速度较快。
附图说明
图1是本发明一个具体实施方式的流程图。
图2是本发明一个具体实施方式中深度神经网络的结构图。
图3是本发明一个具体实施方式中人工景深标定示意图。
具体实施方式
参照图1,本发明一个具体实施方式包括以下步骤:
a、对输入图像进行金字塔模型计算,生成多个分辨率和尺寸的图像;
b、在金字塔的每一层上进行窗口滑动,计算窗口区域的hog特征值,并通过线性svm分类器进行分类,判断该窗口是否为头肩区域;
c、对于步骤b中给出的每个头肩区域,提取相应的图像,归一化到设定好的相同尺寸,输入到深度神经网络中,得到分类输出;
d、对步骤c的输出里的所有头肩窗口进行非极大值抑制,以合并相邻区域和尺度的重叠的检测结果。
步骤a中,对原始图像进行高斯平滑,并生成分辨率下降10%的图像,并对新生成的低分辨率图像重复此过程,直到生成给定层数的金字塔模型。
步骤b中,
对金字塔的每一层进行目标检测;检测过程中,用一个固定大小w×h的窗口在图像空间进行滑动,窗口下的图像区域计算hog特征并输入一个线性svm分类器中,获得是否为头肩目标的判断结果;在hog计算中,每个像素点(x,y)的水平、垂直梯度分别为
gx(x,y)=i(x+1,y)-i(x-1,y)
gy(x,y)=i(x,y+1)-i(x,y-1)
式中i(x,y)表示(x,y)处的像素值,像素点(x,y)的梯度幅值和方向则分别为
α(x,y)=tan-1(gy(x,y)/gx(x,y))
hog的计算是把窗口划分成很多细胞,每个细胞是4x4个像素,细胞
ho(m,n)=∑4m≤x<4m+4,4n≤y<4n+4g(x,y)δo(x,y)/z
与细胞之间不重叠,则对于每个细胞,相应特征的生成公式则为
其中,ho(m,n)为梯度方向为o(0≤o<9)的在细胞(m,n)的特征值;z为某个归一化参数;hog计算每个块的特征并串联起来;这里,每个块则包括2x2个相邻细胞,块与块之间可重叠;每个块的特征包括其下每个细胞的归一化后的9个梯度方向的直方图,形成一个36维的特征;所有块的特征形成维度为36×(w/4-1)×(h/4-1)的hog特征。
步骤c中,对步骤b获得的每个头肩区域,将区域内图像提取出来,放大或缩小到48x48的尺寸,送入深度神经网络中,获取是否为头肩目标的判断。
所述深度神经网络包括3组卷积层与采样层、2个全连接层和1个输出层。
卷积层的3d卷积操作中,对于卷积层的每个输出通道on的每个象素(x,y),
其中im为输入通道,m为输入通道数,hm,n为5x5的二维滤波器,αm,n为通道权重;hm,n与αm,n共同组成了一个3维滤波器;通过pca对im的5x5邻域进行主成分分析,则im可表示为多个主成分的加权和,
其中(i,j)属于(x,y)的5x5邻域,βk为第k个pca投影系数,uk为第k个pca主成分,k为主成分个数,则
其中,
参照图2,其中c1、c3、c5、c7为卷积层,s2、s4、s6为采样层(也包括非线性激活操作),f8、f9为全连接层。所有的卷积层采用的滤波器长度都为5。c1、c3层的填充长度为2,c5层的填充长度为1,c7层不做填充。f8的节点数为128。f9的节点数为2。
为了进一步提升它的速度,我们把每个卷积层操作(c1、c3、c5、c7)里的3d卷积,分解为多个2维卷积和1x1的卷积运算。
标准卷积操作:m为输入通道数、n为输出通道数、滤波器为5x5,所以对于每个像素点位置,要做5x5xmxn次乘法。
pca投影:对于每个输入通道的每个像素点位置,将5x5的邻域投影到6个主成分方向上,这相当于做了6个5x5的卷积,所以对于每个像素点位置,要做5x5x6xn次乘法。
1x1卷积:对于每个像素点位置,对生成的6m维的向量进行加权求和,这相当于一个标准的1x1的卷积操作,所以对于每个像素点位置,要做6xmxn次乘法。
参照图3,分别选择位于近处的一个人的头部和位于远处的一个人的头部,按照人头大小绘制两个方形框。场景中任何位置的人头大小都可根据这两个框的大小以及它们的纵向位置做线性插值获得。这种标定和估算方法成立的前提是所有人都处于同一个主平面中,并且摄像机成像的水平方向与场景中的主平面平行。这样的前提通常是可以满足的。这种对场景任意位置的人头大小的估算可以大幅度减少尺度空间的搜索范围,提高图像分析的速度。
本实施例在多个大学的教室监控系统中进行了验证,可以达到平均89%以上的人数统计准确率。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!