一种人脸识别方法与流程
本发明属于视频监控技术领域,涉及一种人脸识别方法。
背景技术:
近年来基于深度学习的人脸识别方法层出不穷,每年都有大量的高质量的文献、专利发表,人脸相关的产品也迎来了爆发期,在人脸检索、人证比对等方向应用取得了非常显著的成绩,可以说在很多场合人脸识别的性能已经超过人类,但是在监控视频中的应用仍然存在很多未能解决的问题,其中监控场景下的人脸分辨率是一个主要原因,虽然近年来很多摄像头已经从原来的标清升级到高清,但是大多数摄像头都是监控大场景下的人类活动,同时人脸在场景中又存在远近的问题,所以低分辨率的人脸在监控视频中是普遍存在的,这种情况对现有人脸识别方法的性能有很大影响,甚至出现大面积无法识别的问题。
技术实现要素:
本发明针对现有人脸识别算法对低分辨率人脸识别性能低下的问题,提出一种有效的人脸识别方法,可以比较好的解决该问题。
针对低分辨率人脸问题,本发明在深度学习识别网络中加入超分辨模块,能够有效提高人脸分辨率,恢复更多的有利于识别的人脸信息,从而提高低分辨率人脸的识别效果。
为克服现有识别技术对低分辨人脸识别性能低下的问题,本发明提供一种人脸识别方法,具体步骤包含:
步骤1、输入人脸图像。
步骤2、根据人脸大小,将人脸分为清晰人脸和低分辨率人脸。
步骤3、根据步骤2的分类结果,利用预先训练好的深度学习网络计算人脸特征。
步骤4、根据不同图像的人脸特征计算人脸之间的相似度。
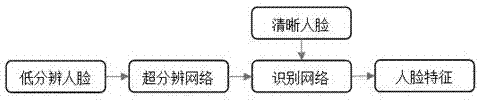
其中所述的预先训练好的深度学习网络其网络结构包含两个子网络,分别是超分辨网络和识别网络,其中超分辨网络的输出为识别网络的输入,在人脸识别特征计算过程中低分辨率人脸从超分辨网络输入,依次经过识别网络得到人脸识别特征,清晰人脸直接输入到识别网络计算人脸识别特征。
以上所述的深度学习网络训练步骤如下:
1、准备清晰的人脸训练数据,其中包含n个人,每个人至少两张以上的人脸照片。
2、每张人脸图像按固定比例α下采样得到低分辨率人脸,并和清晰人脸一一对应形成样本对。
3、低分辨率人脸输入到超分辨网络,利用超分辨网络的loss和对应的清晰图像,训练超分辨网络。
4、超分辨网络的输出作为识别网络的输入,同时利用识别网络的loss及人脸图像的身份类别信息训练识别网络。
5、识别网络的梯度能够直接反传到超分辨网络。
6、超分辨网络和识别网络同步训练直到所有的参数稳定。
本发明的重点是区别对待清晰人脸和低分辨人脸,对于低分辨人脸在识别过程中引入超分辨模块,并且采用端对端的训练方式使得深度学习网络同时具备清晰人脸和低分辨人脸的有效特征提取能力。
本发明的有益效果:
本发明区别对待清晰人脸和低分辨率人脸,有效提升低分辨人脸的识别效果,同时又不影响清晰人脸的识别性能。
本发明将超分辨网络和识别网络集成在一起并且同步训练,能够实现超分辨信息促进识别效果,同时识别网络又反过来指导超分辨网络恢复更有利于识别的人脸信息的良性循环,使得最大限度的利用超分辨提升识别性能。
附图说明
图1为本发明方法流程图。
图2为人脸特征计算流程图。
图3为深度学习网络训练示意图。
具体实施方式
这里结合附图对本发明做一个详细介绍,并给出具体实施细节,如图1所示本发明提供一种人脸识别方法,具体步骤包含:
1、输入人脸图像;
2、根据人脸大小,将人脸分为清晰人脸和低分辨率人脸;
3、根据步骤2的分类结果,利用预先训练好的深度学习网络计算人脸特征;
4、根据不同图像的人脸特征计算人脸之间的相似度。
本实施例根据人脸大小划分人脸类别,以人脸大小100×100为界,小于100×100判为低分辨人脸,否则为正常清晰人脸。
人脸特征计算如图2所示,低分辨人脸从超分辨网络输入,依次经过识别网络,清晰人脸直接从识别网络输入,从而得到人脸识别特征。
人脸相似度计算如公式(1)所示,fi、fj表示两张不同人脸图像的特征向量。
以上所述的深度学习网络训练示意图如图3所示,其训练步骤如下:
1、准备清晰的人脸训练数据,其中包含n个人,每个人至少两张以上的人脸照片,本实施例利用了5万人,平均每人40张人脸图像。
2、每张人脸图像按固定比例α下采样得到低分辨率人脸,并和清晰人脸一一对应形成样本对,本实施方案采用α=0.4,即人脸图像的宽、高都下采样到原来40%。
3、低分辨率人脸输入到超分辨网络(srnet),利用超分辨网络的loss和对应的清晰图像,训练超分辨网络。
4、超分辨网络的输出作为识别网络(recnet)的输入,同时利用识别网络的loss及人脸图像的身份类别信息训练识别网络。
5、识别网络的梯度能够直接反传到超分辨网络。
6、超分辨网络和识别网络同步训练直到所有的参数稳定。
上述训练过程中提到的超分辨网络的loss(sr-loss),本实施例以超分辨图像和清晰图像的欧式距离为loss,其具体公式如下所示:
sr-loss=||srnet(li)-hi||2(2)
其中srnet(li)是低分辨率图像li的超分辨结果,hj是对应的清晰图。
识别网络的loss,本实施例采用softmaxloss,其具体公式如下说是:
其中pj表示在k类样本中属于第j类概率,yj表示当前样本的类别信息。
本实施例对上述超分辨网络采用三层的全卷积网络,卷积核数目分别是64、32、3,卷积核的大小分别是9、5、5,识别网络采用30层的残差网络。
本实施例以caffe为训练工具,其中batchsize为100,初始学习率为0.1,每24000降低10倍直到0.0001,训练策略采用sdg,weightdecay为0.0005,迭代10万次左右能得到比较稳定的模型。
按照本实施例,经具体测试,相比没有对低分辨人脸做针对性优化的方案其识别性能上有非常显著的提升。
- 还没有人留言评论。精彩留言会获得点赞!