一种基于语义通道的多特征行人检测方法与流程
本发明属于计算机视觉领域,涉及一种基于语义通道的多特征行人检测方法,通过初始通道图片处理、特征提取以及决策森林的分类来实现对行人的高效检测。可用于车辆辅助驾驶、机器人研究技术等领域。
背景技术:
近年来,汽车的自动驾驶技术越来越受到研究者的关注。作为自动驾驶技术中的一个重要环节,行人检测是利用计算机视觉技术来判断图像或者视频中是否存在行人。与图像分类任务不同的是,行人检测还需将行人用方框标注出来以表示行人的方位。同时,在智能监控和机器人领域,行人检测也发挥了重要作用。
行人检测主要包含三类方法:
决策森林方法。该类方法通常先需要初始通道处理输入图片来得到初始通道图片,接下来提取这些通道图片中的手工特征,最后将这些特征输入到决策森林中来判定该特征是否属于行人。分类器的学习权重相当于行人身体的全局模板。该方法有较快的检测速度,手工特征对于小尺寸的行人有较好的检测效果。
基于深度学习的方法。深度学习方法通常需要较大的网络架构,包括卷积层,池化层,全连接层等,能从原始像素中学习出不同的特征。该方法无需人工设计特征,提取出的特征、人体变形部分和分类器通常可以用来联合优化算法效果。
dpm(deformablepartmodel,可变形部分模型)。与决策森林方法不同的是,dpm可以识别行人更复杂的姿势和动作,学习混合身体每个部分的局部模板来判断行人是否存在。该方法对于不同动作的行人往往能更好的识别。
现有的行人检测方法往往存在将背景和垂直物体等错误地识别为行人,并且忽视小尺寸的行人、骑行者和遮挡等异常情况。一些算法在取得较高性能的同时会有较多的耗时,或者运行速度较快但取得的效果却不佳。因此在性能与耗时之间取得一个平衡也是研究者的关注重点。
技术实现要素:
本发明的目的是针对现有技术问题而提供的一种基于语义任务的多特征行人检测方法,对现有的行人检测方法进行改进,来实现在道路环境下对于行人的高性能检测。
实现本发明目的的具体技术方案是:
一种基于语义通道的多特征行人检测方法,该方法包括以下具体步骤:
步骤1:训练阶段
将caltech行人训练数据库用hog+luv通道和sof算法处理,得到初始通道图片集合;将这些图片利用滑动窗口方法提取多尺寸的行人特征图,在这些特征图中提取侧面差异和对称相似度特征;利用这些特征建立决策森林,得到训练完成的快速提升决策森林;
步骤2:测试阶段
利用车载摄像头拍摄的照片作为测试数据,使用hog+luv通道和sof算法对图片进行处理后得到输入通道图片,使用滑动窗口方法在通道图片中得到多尺寸的行人特征图,并提取侧面差异和对称相似度特征;将这些特征输入到在训练阶段中训练完成的快速提升决策森林中,以此决定特征是否为行人,并在图片中行人的对应位置上标上方框,测试阶段结束。
所述训练阶段中,输入数据为caltech行人测试数据库,测试数据库为一段一段的视频,将这些视频每3帧取1个样帧,并且在注释文件中取得对应注释信息;图片大小为640*480像素。
所述测试阶段中,输入数据为车载摄像头拍摄的图片,将图片大小调整为640*480像素。
所述使用hog+luv通道和sof算法对图片进行处理是:对输入图片进行hog+luv通道处理,这10个通道包括6个hog(histogramoforientedgradients,梯度直方图)通道,1个归一化梯度大小通道,3个luv色彩通道,将10张处理后的图片形成初始通道图片集合;并且使用sof(semanticopticalflow)算法处理输入图片,得到语义分割图像,将该语义分割图像也加入到初始通道图片集合中。
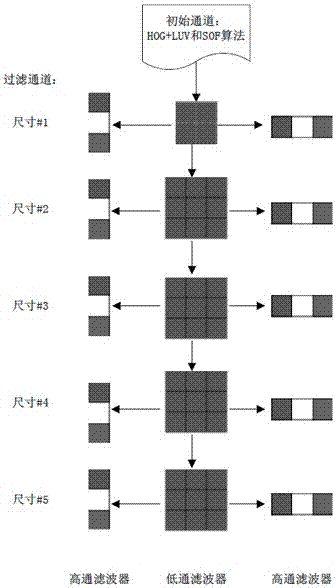
所述得到多尺寸的行人特征图是:设计相应的5个低通滤波器和10个高通滤波器;使用2*2像素集合体和4个平滑滤波器获得5个不同尺寸的通道,利用水平和垂直方向的高通滤波器在每个通道上进行处理得到不同大小的边缘。
所述提取侧面差异和对称相似度特征是:规定碎片a初始大小2*2像素,从a开始提取水平对称碎片a'以及a和a'之间的碎片b,步长为2像素,利用特征公式分别计算侧面差异特征和对称相似度特征;接着每次碎片长度和宽度增加1像素长度,重复上述步骤,直到碎片大小为12*12像素。
所述训练阶段,将产生的特征输入到决策森林中;该决策森林进行5轮的学习,每一轮树的数量为32,128,512,2048,最后到4096;每棵树的建立过程中都会从庞大的特征中随机取样1/32的特征,初始化样本权重,这些权重按照降序排序,并且对每个节点经过贪心极大搜索;每一轮过后,都会加入5000个负例,累积的负例不超过20000个。最终建立完成的快速提升决策森林包含4096棵决策树。
所述在测试阶段,将产生的3种特征输入到已经训练完成的拥有4096棵树的快速提升决策森林中,判断特征是否属于行人;将行人特征映射回到原图上,在对应的行人区域打上方框。
本发明有益效果
本发明解决了在图像中检测行人并标注行人的问题。该发明可用于车辆自动驾驶中,帮助车辆准确识别行人,具有运行速度快,识别准确率高的优点,对小尺寸的行人、骑行者和遮挡等异常情况也能较好的处理。
附图说明
图1为本发明流程图;
图2为提取多尺度行人特征流程图;
图3为训练快速提升决策森林具体流程图;
图4为经过sof算法处理的效果图;
图5为在提取侧面差异和对称相似度特征碎片取样的效果图。
具体实施方式
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。
参阅图1,本发明包括:
步骤1:训练阶段
使用hog+luv通道和sof算法处理caltech行人训练数据库,得到初始通道图片;在通道图片中提取多尺寸行人特征,接着在这些特征图中提取侧面差异和对称相似度特征;利用这些特征建立决策森林,得到快速提升决策森林,训练完成。
步骤2:测试阶段
使用hog+luv通道和sof算法对车载摄像头拍摄的照片进行处理后得到输入通道图片,使用滑动窗口方法在通道图片中得到多尺寸的行人特征图,并提取侧面差异和对称相似度特征;将这些特征输入到已训练完成的快速提升决策森林中,以此判别特征是否为行人,并在原始图片中行人的对应位置上标上方框。
以下结合各子步骤,详细阐述本发明的具体实施过程
训练阶段
s11:在训练阶段,输入数据为caltech行人数据库,每3帧取1个样帧,并且取得相应注释。输入图片大小为640*480像素。
s12:将输入图片经过10个hog+luv图片通道的处理,这10个通道包括6个hog(histogramoforientedgradients,梯度直方图)通道,1个归一化梯度大小通道,3个luv色彩通道,将10张处理后的图片形成初始通道图片集合。
s13:使用sof(semanticopticalflow)算法处理输入图片,得到语义分割的图片,将该结果图片也加入到初始通道图片集合中。sof算法的过程为:1)预处理阶段,使用deeplab算法将图片预分割。网络架构使用vgg模型,使用随机梯度下降和紧密连接条件随机域对模型进行调整。接着对物体进行匹配并且利用discreteflow算法初始化光流。2)移动建模,对背景和独立物体的移动进行分层建模。3)构成流域,局部层会评估前景和背景像素的流值,最终确定光流域。4)优化分割,利用流域重新优化图像的语义分割。
s14:采用滑动窗口方法来提取候选窗口,滑动窗口大小采用如下大小:水平长度为图片宽度的1/16,垂直长度为图片高度的1/16。通过将窗口中心固定在80至400行可以减少33%的搜索域,步长为4像素。为了提取5种尺寸的多尺寸行人特征,设计相应的5个低通滤波器和10个高通滤波器。低通滤波器可以捕捉在不同尺寸行人中的特征,高通滤波器可以捕捉不同的结构比如边缘和中心。使用2*2像素集合体和4个平滑滤波器获得5个不同尺寸的通道,利用水平和垂直方向的高通滤波器在每个通道上进行处理得到不同大小的边缘。该过程如图2所示。
s15:提取侧面差异特征:假设碎片b可定位于a与a'之间,a'为a的水平对称碎片。该特征计算形式如下
其中ab为取样碎片,sa为碎片a的像素和,na为碎片a中的像素个数。
提取对称相似度特征中,对称相似度特征计算如下:
ssf(a,a')=|fa-fa'|
ssf为碎片a与a'的对称相似度特征。f为最大值池化函数,补丁a中包含三个随机产生小块a1,a2,a3并且面积都大于a的1/2,因此在l和v通道上
其他通道求的是最大值,公式如下所示
取样碎片的距离可以不同,高度相同,两者大小相同,但不可超过最大方框,方框大小为8*8细胞,一个细胞为2*2像素,纵横比可以调整。规定碎片a初始大小1*1细胞,从a开始提取水平对称碎片a'以及a和a'之间的碎片b,步长为2像素,利用上述特征公式分别计算侧面差异特征和对称相似度特征。接着每次碎片长度和宽度增加1细胞长度,重复上述步骤,直到碎片大小为6*6细胞。
s16:如图3所示,将s14步骤和s15步骤中产生的3种特征输入到快速提升决策森林中。该分类器进行5轮的学习,每一轮树的数量为32,128,512,2048,最后到4096。每棵树的建立过程中都会从庞大的特征中随机取样1/32的特征,初始化样本权重,这些权重按照降序排序,并且对每个节点经过贪心极大搜索。每一轮过后,都会加入5000个负例,累积的负例不超过20000个。
在寻找最优特征的训练过程中,1)在相对较小的m-分集合中测试每个特征,2)基于先前的错误值进行最好到最差的排序。3)对于每个特征,继续在逐渐增大的样本集合中训练,升级错误值。如果被证明是不正确的,立即修剪。若训练完成,将其保存为最佳状态。4)输出最佳特征和相应的参数。
在提升阶段,1)使用线性搜索决定优化标量αt,2)对于给定的错误分类和提升时的具体变量来升级样本权重。3)若需要更多的提升迭代次数,降序排序样本权重,增加迭代次数t,进行第2步。
测试阶段
s21:在测试阶段,输入图片为车辆前端放置摄像头拍摄的图片。输入图片大小为640*480像素。
s22:与s12和s13所述相同,将输入图片经过10个hog+luv图片通道的处理,形成初始通道图片集合。使用sof算法处理输入图片,得到语义分割的图片,将该结果图片也加入到初始通道图片集合中。
s23:与s14和s15所述相同,在初始通道图片中提取多尺寸行人特征、侧面差异特征和对称相似度特征。
s24:将s23中产生的3种特征输入到已经训练完成的拥有4096棵树的快速提升决策森林中,判断特征是否属于行人。将行人特征映射回到原图上,在相应的行人区域打上方框。
实施例
本实施例中,输入图片为车辆前端放置的摄像头拍摄的图片,大小为640*480像素,在内存中的形式为640*480的二维矩阵,如下所示。
其中xmnm<=480n<=640表示一个特定位置上的像素。将该图片分别使用hog+luv通道和sof算法进行处理,得到的初始通道图片共有11张,大小都为640*480像素。其中,sof算法还需要输入前一次的处理图片进行光流的比对。图为经过sof算法处理得到的语义分割图片。在图4中,有两个移动的行人,在背景中包括了山、天空和道路。
在提取多尺寸行人特征中,采用滑动窗口的方法,窗口大小为40*30像素,将窗口中心固定在80至400行,步长为4像素。先使用2*2像素的集合体对窗口中的像素依次进行处理,在使用4个低通滤波器依次进行处理。在各尺寸的通道上使用水平和垂直方向的2个高通滤波器进行处理,得到不同大小的边缘信息。一共使用了15个滤波器,将每个通道分为2*2像素的块,并且计算平均值。每张初始图经过多尺寸行人特征提取后变为320*240像素的特征图。
在提取侧面差异特征和对称相似度特征中,初始碎片大小为2*2像素,最终碎片大小为12*12。每次迭代碎片高度与宽度各增加2像素,步长为2像素。将碎片中心固定在40至200行之间。每一次迭代中,固定碎片a,产生相同大小、高度的碎片a',开始离开碎片a向右滑动。每到达一个新的位置,都计算给定的侧面差异特征和对称相似度特征。如图5所示,最左边的方框为碎片a,中间的方框为具有侧面差异特征的碎片b,最右边的方框为具有对称相似度特征的碎片a'。将6种碎片大小的两种特征分别都制作为二维矩阵形式。
将提取出来的二维矩阵输入到已经训练完成的拥有4096颗树的快速提升决策森林中。比如输入特征矩阵为320*240,输出矩阵大小为320*2,代表320种特征是否为行人特征,0代表不是行人特征,1代表是行人特征。将这些是行人的特征映射回原图上,在相应的区域上打上方框,表示该区域有行人的存在。
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
- 还没有人留言评论。精彩留言会获得点赞!