识别网络爬虫的方法、存储介质、电子设备及系统与流程
本发明涉及信息处理领域,具体涉及一种识别网络爬虫的方法、存储介质、电子设备及系统。
背景技术:
目前,很多网站会采用反爬虫技术以防止网站的正常访问被爬虫的访问流量所阻扰。常用的反爬虫技术会通过判断用户请求中的headers字段,来判断是否是一个浏览器。也会采用对ip的访问量统计的方式来判断是否是爬虫,比如一段时间ip访问量非常大则可以判断是爬虫。还会采用动态生成网页信息的方式来判断,例如将页面部分内容使用代码来生成而不是一个静态页面。
然而基于上述的反爬虫策略最终都会有相应的应对方法,例如对于对ip的访问量统计的方式,可以使用代理ip不断的变换ip来访问来应对。例如针对反爬虫将页面属性设置为隐藏属性这种方式,其特点是避免了正常人点击该链接,但是爬虫会爬取该链接,这种方法在爬虫通过仔细研究后可以通过链接的属性而不对该链接进行爬取,从而绕过了爬虫的检测策略,达不到识别爬虫的目的。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种识别网络爬虫的方法,该方法能较好地避免爬虫绕过爬虫检测策略,更有效的识别网络爬虫。
为达到以上目的,本发明采取的技术方案是:
一种识别网络爬虫的方法,该方法包括以下步骤:
创建用于检测网络爬虫行为的多个无效链接;
利用无效链接提供的链接地址,创建隐藏链接属性信息的第一链接,以及创建与html页面背景色相同的肉眼不可见的第二链接;
将第一链接和第二链接插入到html页面中;
记录在html页面上的操作信息并上报至服务器;以及
服务器判断是否收到操作信息,若否,则为网络爬虫,若是,则进一步判断是否存在对第一链接和第二链接的访问,若是,则为网络爬虫,若否,则为正常访问。
在上述技术方案的基础上,所述第二链接包括与html页面背景色相同的肉眼不可见的图片链接和/或文字链接。
在上述技术方案的基础上,所述图片链接插入html页面的方法为:
在html页面插入图片,并设定图片的宽度和高度,为所述图片附上超链接,所述超链接指向无效链接提供的链接地址。
在上述技术方案的基础上,所述文字链接插入html页面的方法为:
在html页面插入文字,并设定文字的颜色、字体大小和文本内容,为所述文字附上超链接,所述超链接指向无效链接提供的链接地址。
在上述技术方案的基础上,所述第一链接插入html页面的方法为:
在html页面插入不可见的超链接,所述超链接指向无效链接提供的链接地址。
在上述技术方案的基础上,所述方法还包括定时更换html页面上插入的第一链接和第二链接以及更换无效链接提供的链接地址的步骤。
在上述技术方案的基础上,通过在现有地址上添加字段或者将现有字段改为无效字段来创建用于检测网络爬虫行为的多个无效链接。
本发明还提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
本发明还提供一种设备,包括存储器、处理器及存储在存储器上并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
本发明的目的还在于提供一种识别网络爬虫的系统,该系统能较好地避免爬虫绕过爬虫检测策略,更有效的识别网络爬虫。
为达到以上目的,本发明采取的技术方案是:
一种识别网络爬虫的系统,包括:
生成模块,其用于创建检测网络爬虫行为的多个无效链接,并根据无效链接提供的链接地址,创建隐藏链接属性信息的第一链接以及与html页面背景色相同的肉眼不可见的第二链接;
插入模块,其用于将所述第一链接和第二链接插入到html页面中;
记录模块,其用于记录在html页面上的操作信息;以及
服务器,其用于根据是否收到操作信息以及是否存在对第一链接和第二链接的访问来判断是否为网络爬虫,若未收到操作信息,则为网络爬虫,若收到操作信息,则进一步判断是否存在对第一链接和第二链接的访问,若是,则为网络爬虫,若否,则为正常访问。
与现有技术相比,本发明的优点在于:
本发明的识别网络爬虫的方法,为了识别爬虫,创建了多个无效链接,然后利用无效链接提供的链接地址,创建隐藏链接属性信息的第一链接,以及创建与html页面背景色相同的肉眼不可见的第二链接。在进行识别时,首先通过判断服务器是否收到操作信息来识别爬虫,若服务器没有收到操作信息,则可以认为是爬虫行为。若收到操作信息则进一步判断是否存在对第一链接和第二链接的访问,由于正常去访问网站时基本不会点击到上述这些链接,从而也不会产生访问该链接的请求。但是如果是爬虫程序,由于爬虫会爬取所有的链接,从而服务器可以判断凡是有对上述第二链接和第一链接进行访问的,都认为是爬虫程序。而且本发明实施例采用了第二链接和第一链接相结合的策略,避免了在仅仅使用隐藏链接属性信息的第一链接时,被爬虫绕过的情况,至此得以更好的实现对爬虫的识别。
附图说明
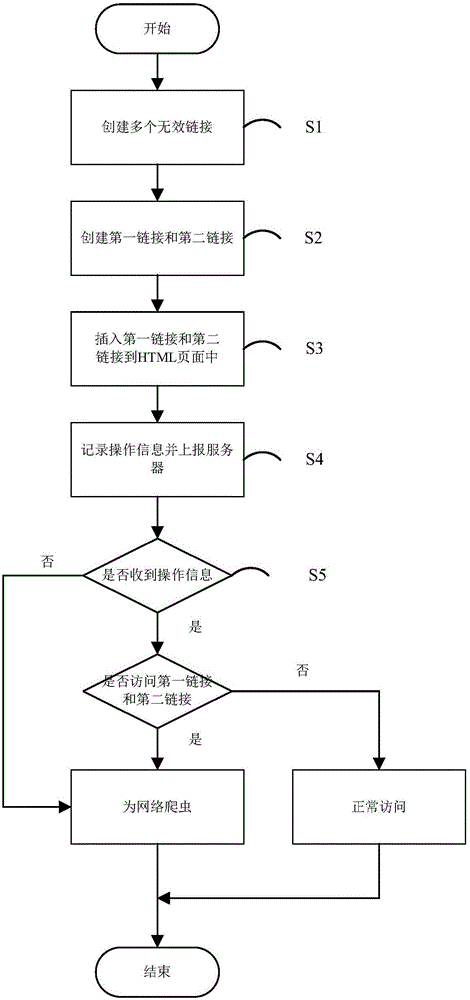
图1为本发明实施例中识别网络爬虫的方法的流程图;
图2为本发明实施例中电子设备连接框图。
具体实施方式
以下结合附图及实施例对本发明作进一步详细说明。
参见图1所示,本发明实施例提供一种识别网络爬虫的方法,该方法包括以下步骤:
s1.创建用于检测网络爬虫行为的多个无效链接。
本发明实施例首先会创建一些无效的链接,无效的意思是指该链接不会对正常的网页访问提供任何信息,并且正常的用户基本是看不到该链接也不会点击到该链接,无效链接只是用于检测爬虫的行为。通常无效链接会尽量的隐藏起来防止正常的用户进行点击访问。
无效链接具体的链接地址则可以是在现有的地址中添加一个字段用于表示无效的链接,或者将正常的地址的某个字段改成无效的字段。对于这样的无效链接,当其被点击时,会从服务器请求该页面的数据,此时服务器则可以知道该页面被访问了,从而可以检测此时的访问是爬虫行为。
具体实现如下:例如网站的主页程序中存在的一个链接:www.douyu.com/game/lol,该链接标示一个lol的分页链接。此时可以通过设置成一个不存在的游戏链接来创建无效链接,如下:www.douyu.com/game/xxabc,其中xxabc是不存在的。
对于https://www.douyu.com/game/tvgame?page=3&isajax=1这类链接,字段page=3表示第3页。则此时可以通过将其修改成一个无效的页面数来创建无效链接,比如可以修改成下面这种形式:https://www.douyu.com/game/tvgame?page=xx&isajax=1。
在实际运用中创建无效链接有多种方法,可以不断的去变换生成的无效链接的形式,以提高无效链接的伪装度。
s2.利用无效链接提供的链接地址,创建隐藏链接属性信息的第一链接,以及创建与html页面背景色相同的肉眼不可见的第二链接。
由于爬虫都是通过编写程序来请求网站的html数据,然后再使用程序来从html中解析出所有的链接,接着会去访问所有的链接来继续爬取网站的数据。
本发明实施例并非仅通过一种隐蔽策略,而是使用多种隐蔽策略相互结合的方式来识别爬虫,其效果会更为明显。例如对于网页中极其不显眼的位置插入一个非常小的与html页面背景色相同的肉眼不可见的第二链接,还可以是在页面中的链接将其可见属性设置为不可见的第一链接。
通常来说,正常去访问网站时基本不会点击到上述这些链接,从而也不会产生访问该链接的请求。但是如果是爬虫程序,由于爬虫会爬取所有的链接,从而服务器可以判断凡是有对上述第二链接或第一链接进行访问的,都认为是爬虫程序。
本发明实施例的第二链接包括与html页面背景色相同的肉眼不可见的图片链接和/或文字链接。例如可以在网页的某一次背景旁边插入一个链接,该链接也是一个图片链接,且图片的颜色正好和背景融合到一起,一般来说是无法看到此处有一个链接,正常访问该网页时也不会点击该链接。同样的也可以设置文字链接,可以将文字链接设置成和背景一样的颜色,从而融合到背景图片中。
由于第二链接或第一链接也有可能被正常访问到,为了防止误判,本发明实施例的策略可以是一个页面多个第二链接或第一链接被访问到,或者是连续多个页面的第二链接或第一链接被访问到时,才认为是爬虫。
此外,如果仅仅使用隐藏链接属性信息的第一链接,爬虫很可能会识别到这种策略,从而对于不显示的链接不进行爬取。但是本发明实施例不仅使用了隐藏链接属性信息的第一链接,同时也使用了刻意伪造的图片链接和/或文字链接,对于刻意伪造的图片链接和/或文字链接,爬虫不容易绕过其检测策略,故将其结合使用可以达到更好的效果。
s3.将第一链接和第二链接插入到html页面中。
本发明实施例中将第一链接和第二链接插入到html页面中的方法如下:
对于第二链接中的图片链接,其插入方式为:
<ahref="链接的地址"><imgsrc="图片的url"width="图片的宽度"height="图片的高度"></a>,即在html页面插入图片,并设定图片的宽度和高度,为图片附上超链接,超链接指向无效链接提供的链接地址。
其中href="链接的地址"表示填入链接的地址,src="图片的url"表示图片的链接的地址,width="图片的宽度"表示图片的宽度,height="图片的高度"表示图片的高度。
为了很好的隐蔽这个链接地址,会将图片和背景尽量的融合到一起,起到隐藏的作用。
对于第二链接中的文字链接,其插入方式为:
<ahref="链接的地址"style="color:#fff;font-size:12px;"><“文字”></a>。即在html页面插入文字,并设定文字的颜色、字体大小和文本内容,为文字附上超链接,超链接指向无效链接提供的链接地址。
这里可以通过设置color属性来设置文字的颜色,可以通过font-size来设置字体的大小,可以通过font-weight来设置字体的权重。通过一系列的设置可以使得文件链接隐蔽的插入到现有的html页面中。
对于隐藏链接属性信息的第一链接,其插入方式为:
<ahref="链接的地址"style="display:none;"></a>。即在html页面插入不可见的超链接,超链接指向无效链接提供的链接地址。
通过设置style中的display为none表示该标签的链接地址不会在页面中进行显示,从而在页面中此链接是不可见的。
为了起到更好的识别爬虫的效果,本发明实施例还包括定时更换html页面上插入的第一链接和第二链接以及更换无效链接提供的链接地址的步骤。
具体的,为了防止爬虫能够刻意分析出本发明实施例中的反爬虫策略,本发明实施例会对每个页面链接插入的位置进行变换,以及对于链接的生成的链接地址进行更换。
此外,服务器还可以在不同的页面将文字链接、图片链接和不可见的链接组合起来插入到不同的页面,还可以采用有些页面插入不可见链接,有些页面不插入不可见链接的方式,使得页面插入的第一链接具有随机性,使得爬虫不易于找到其中规律。这样通过不断的进行更新和变换,可以极大的提高其被爬虫分析的门槛。
本发明实施例对于无效链接的构造方式也可以经常的进行更换,例如当网站开发了一个新的板块页面,则可以通过新的板块的页面来构造新的无效链接,以防止爬虫记录了旧的无效链接而导致反爬虫策略失效。
s4.记录在html页面上的操作信息并上报至服务器。
对于正常的网页,当用户使用鼠标或者键盘点击页面信息时,会有鼠标的移动信息和点击信息,或者是键盘的按键信息。然而爬虫是通过网络协议直接请求服务器的页面数据,所以是没有页面操作信息的,本发明实施例基于以上这个区别,可以在页面上记录用户的操作信息,并通过网络协议发送给服务器,告知此页面有用户操作信息,如果没有操作信息则服务器不会收到客户端的用户操作信息。
s5.服务器判断是否收到操作信息,若否,则为网络爬虫,若是,则进一步判断是否存在对第一链接和第二链接的访问,若是,则为网络爬虫,若否,则为正常访问。
首先服务器可以通过判断是否有收取到客户端上报的操作信息,如果有没有收到操作信息则可以认为是爬虫行为。如果收到操作信息则进一步的判断是否存在对第一链接和第二链接的访问(因为用户的页面操作信息也是可以被高级的爬虫进行伪造),当服务器收到对上述链接的访问请求时,可以对每个请求进行标记,同时为了防止产生误判,服务器则可以定义同一个页面有超过2个或者不同的页面有超过2个以上的请求则认为是一个爬虫的行为。由于正常去访问网站时基本不会点击到上述这些链接,从而也不会产生访问该链接的请求。但是如果是爬虫程序,由于爬虫会爬取所有的链接,从而服务器可以判断凡是有对上述第二链接或第一链接进行访问的,都认为是爬虫程序。采取上述方式后可以比较容易的识别出爬虫和用户的访问区别,从而对爬虫进行阻止等惩罚措施。
同时存在一些搜索引擎是基于爬虫的形式来爬取页面,那么服务器则需要排除掉这些搜索引擎,例如百度搜索引擎,其爬虫ip是固定的几种,可以通过ip地址来过滤掉搜索引擎爬取。也可以结合http请求中的user-agent来排除,其中百度搜索引擎的user-agent是baiduspider。
综上所述,本发明实施例为了识别爬虫,创建了多个无效链接,然后利用无效链接提供的链接地址,创建隐藏链接属性信息的第一链接,以及创建与html页面背景色相同的肉眼不可见的第二链接。在进行识别时,首先通过判断服务器是否收到操作信息来识别爬虫,若服务器没有收到操作信息,则可以认为是爬虫行为。若收到操作信息则进一步判断是否存在对第一链接和第二链接的访问,由于正常去访问网站时基本不会点击到上述这些链接,从而也不会产生访问该链接的请求。但是如果是爬虫程序,由于爬虫会爬取所有的链接,从而服务器可以判断凡是有对上述第二链接和第一链接进行访问的,都认为是爬虫程序。而且本发明实施例采用了第二链接和第一链接相结合的策略,避免了在仅仅使用隐藏链接属性信息的第一链接时,被爬虫绕过的情况,至此得以更好的实现对爬虫的识别。
对应上述的识别网络爬虫的方法,本发明实施例还提供一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时可实现上述实施例中的识别网络爬虫的方法的步骤。需要说明的是,存储介质包括u盘、移动硬盘、rom(read-onlymemory,只读存储器)、ram(randomaccessmemory,随机存取存储器)、磁碟或者光盘等各种可以存储程序代码的介质。
另外,参见图2所示,对应上述的识别网络爬虫的方法,本发明实施例还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该处理器执行计算机程序时可实现上述实施例中的识别网络爬虫的方法的步骤。
本发明实施例还提供一种识别网络爬虫的系统,其包括生成模块、插入模块、记录模块和服务器。
生成模块,其用于创建检测网络爬虫行为的多个无效链接,并根据无效链接提供的链接地址,创建隐藏链接属性信息的第一链接以及与html页面背景色相同的肉眼不可见的第二链接。
插入模块,其用于将第一链接和第二链接插入到html页面中。
记录模块,其用于记录在html页面上的操作信息。
服务器,其用于根据是否收到操作信息以及是否存在对第一链接和第二链接的访问来判断是否为网络爬虫,若未收到操作信息,则为网络爬虫,若收到操作信息,则进一步判断是否存在对第一链接和第二链接的访问,若是,则为网络爬虫,若否,则为正常访问。
本发明不局限于上述实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出多个改进和润饰,这些改进和润饰也视为本发明的保护范围之内。本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!