一种创新创意的大数据处理方法、服务器及系统与流程
本发明属于大数据处理领域,尤其涉及一种创新创意的大数据处理方法、服务器及系统。
背景技术:
创新是引领发展的第一动力,是企业生存与发展的根本。大数据环境下,如何进行创新是每一个企业都急需解决的问题。
传统的创新研发方法主要分为创意产生方法、概念开发方法、概念评估方法、设计开发方法等。例如,常见的创意产生方法有头脑风暴法、kj法、德尔菲法、“5w2h”法等;常见的概念开发方法有形态分析法、质量功能配置法(qfd)、triz法、sit和usit法等;常见的概念评估方法有层次分析法、决策矩阵法、pugh矩阵法、加权评分法等;常见的设计开发方法有产品及周期优化法、田口方法、公理化设计理论、价值工程法等。
以上这传统创新方法确实在企业创新研发的各环节中起到一定作用,但是,这些传统的创新方法只涉及创新过程的某一环节,尚没有一套完整的方法和系统能够引导用户实现从创意到开发的整个创新研发过程。并且,在互联网+与大数据时代,如何充分利用大数据技术和“众智众创”进行更科学的创新研发,也有待解决。
技术实现要素:
为了解决现有技术的不足,本发明的第一目的是提供一种创新创意的大数据处理方法,其能够准确获取用户需求、最新技术、现有产品优缺点等信息,实现精准创新。
本发明的一种创新创意的大数据处理方法,该方法在大数据处理服务器内完成,包括:
步骤1:爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络;
步骤2:接收客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案;
步骤3:将初始创新方案发送至评价服务器,并在评价服务器内依据预设评分标准对初始创新方案进行评分;
步骤4:接收评价服务器的评分并与方案合格评分阈值相比较,若前者大于后者,则初始创新方案为可行创新方案;否则,返回步骤2,直至得到可行创新方案。
进一步的,在所述步骤1中,利用定向爬虫对多源异构的创新大数据进行爬取。其中,创新大数据主要指从科技博客、技术报告、专利信息、社交媒体等渠道提取出的海量网络数据和来源于企业erp和web交易系统的企业报表、产品交易数据和企业内部专业知识等。
进一步的,所述步骤1中集合生成具有层次关联关系的创新知识网络的具体过程包括:
利用现有分词系统和停用词库对创新大数据进行分词、去停用词预处理;
建立向量空间模型vsm,通过tf-idf计算vsm中各项的权重,提取关键词;
计算提取出关键词的相关度,将相关度高的关键词筛选出来,利用层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合;
根据聚类后的关键词集合和相应的层次关联关系,形成具有层次关联关系的三层模型,最终建立出创新知识网络。
本发明首先通过去噪预处理并提取关键词,进而通过层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合,最后建立出创新知识网络,将关键词及其层次结合在一起,使得创新知识网络更加立体形象。
进一步的,所述步骤2中进行相关信息标注之后,还包括通过训练好的语言模型自动生成初始创新方案。
本发明的第二目的是提供一种创新创意的大数据处理服务器。
本发明的一种创新创意的大数据处理服务器,包括:
创新知识网络生成模块,其用于爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络;
初始创新方案生成模块,其用于接收客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案;
初始创新方案评分模块,其用于将初始创新方案发送至评价服务器,并在评价服务器内依据预设评分标准对初始创新方案进行评分;
可行创新方案生成模块,其用于接收评价服务器的评分并与方案合格评分阈值相比较,若前者大于后者,则初始创新方案为可行创新方案,直至得到可行创新方案。
进一步的,在所述创新知识网络生成模块中,利用定向爬虫对多源异构的创新大数据进行爬取。其中,创新大数据主要指从科技博客、技术报告、专利信息、社交媒体等渠道提取出的海量网络数据和来源于企业erp和web交易系统的企业报表、产品交易数据和企业内部专业知识等。
进一步的,所述创新知识网络生成模块,包括:
预处理模块,其用于利用现有分词系统和停用词库对创新大数据进行分词、去停用词预处理;
关键词提取模块,其用于建立向量空间模型vsm,通过tf-idf计算vsm中各项的权重,提取关键词;
层次关联关系集合建立模块,其用于计算提取出关键词的相关度,将相关度高的关键词筛选出来,利用层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合;
创新知识网络建立模块,其用于根据聚类后的关键词集合和相应的层次关联关系,形成具有层次关联关系的三层模型,最终建立出创新知识网络。本发明首先通过去噪预处理并提取关键词,进而通过层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合,最后建立出创新知识网络,将关键词及其层次结合在一起,使得创新知识网络更加立体形象。
进一步的,所述初始创新方案生成模块中进行相关信息标注之后,还包括通过训练好的语言模型自动生成初始创新方案。
本发明的第三目的是提供一种创新创意的大数据处理系统。
本发明的一种创新创意的大数据处理系统,包括上述所述的创新创意的大数据处理服务器。
进一步的,所述大数据处理服务器还与客户端相连。本发明在客户端实时显示由大数据处理服务器输出的可行创新方案。
与现有技术相比,本发明的有益效果是:
本发明通过爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络,再根据客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案,再经过评价服务器内的评分,生成可行创新方案,最终实现准确获取用户需求、最新技术、现有产品优缺点等信息,实现精准创新,以及实现了创新大数据融合、创意智能推荐和解决方案生成,提高了产品研发的效率。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1是本发明的一种创新创意的大数据处理方法流程图。
图2是本发明的创新创意的大数据处理方法具体实施例示意图。
图3是本发明的一种创新创意的大数据处理服务器结构示意图。
图4是本发明的一种创新创意的大数据处理系统结构示意图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
图1是本发明的一种创新创意的大数据处理方法流程图。
如图1所示的本发明的一种创新创意的大数据处理方法,该方法在大数据处理服务器内完成,包括:
步骤1:爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络。
具体地,在所述步骤1中,利用定向爬虫对多源异构的创新大数据进行爬取。其中,创新大数据主要指从科技博客、技术报告、专利信息、社交媒体等渠道提取出的海量网络数据和来源于企业erp和web交易系统的企业报表、产品交易数据和企业内部专业知识等。
具体地,所述步骤1中集合生成具有层次关联关系的创新知识网络的具体过程包括:
利用现有分词系统和停用词库对创新大数据进行分词、去停用词预处理;
建立向量空间模型vsm,通过tf-idf计算vsm中各项的权重,提取关键词;
计算提取出关键词的相关度,将相关度高的关键词筛选出来,利用层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合;
根据聚类后的关键词集合和相应的层次关联关系,形成具有层次关联关系的三层模型,最终建立出创新知识网络。
本发明首先通过去噪预处理并提取关键词,进而通过层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合,最后建立出创新知识网络,将关键词及其层次结合在一起,使得创新知识网络更加立体形象。
步骤2:接收客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案。
具体地,所述步骤2中进行相关信息标注之后,还包括通过训练好的语言模型自动生成初始创新方案。
步骤3:将初始创新方案发送至评价服务器,并在评价服务器内依据预设评分标准对初始创新方案进行评分。
步骤4:接收评价服务器的评分并与方案合格评分阈值相比较,若前者大于后者,则初始创新方案为可行创新方案;否则,返回步骤2,直至得到可行创新方案。
本发明通过爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络,再根据客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案,再经过评价服务器内的评分,生成可行创新方案,最终实现准确获取用户需求、最新技术、现有产品优缺点等信息,实现精准创新,以及实现了创新大数据融合、创意智能推荐和解决方案生成,提高了产品研发的效率。
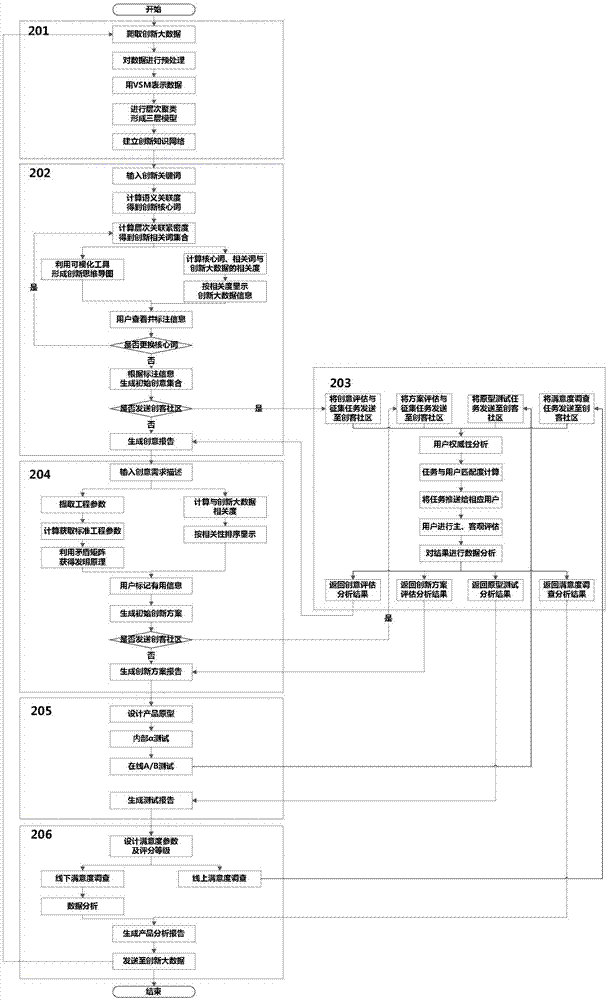
图2是本发明的创新创意的大数据处理方法具体实施例示意图。
本发明的创新创意的大数据处理方法具体实施例的过程包括:
步骤201:利用爬虫对创新大数据进行爬取,数据预处理,用向量空间模型表示,抽取关键词进行层次聚类,形成三层模型,最终建立创新知识网络。
其中,步骤201还包括:
步骤2011:利用爬虫对购物网站、科技博客、数据知识服务等平台进行数据爬取,获取商品信息、评价信息、科技信息和专利信息等,存放在创新大数据库中,同时,将企业内部数据上传至创新大数据库ibd。
步骤2012:用现有分词系统,如nlpir等对分步骤1中爬取到的数据信息进行分词、去停用词等预处理。
步骤2013:数据文档dj用向量空间模型vsm表示可以表示为dj(w1j,w2j,…,wnj),其中n是所有词的数目,wij代表了标引词i在文档dj中的权重。
用tf-idf方法计算向量空间模型中项的权重,抽取出数据文档关键词,tf-idf的计算公式如下:
tf-idf=词频tf×逆向文件频率idf
其中:
步骤2014:用欧式距离计算抽取出关键词的相似度,将相似度高的关键词筛选出来,欧式距离的表达式如下:
其中,公式中的ti和tj分别表示两个抽取出来的不同的关键词、wk记录关键词在向量空间模型中的位置信息、k指的是总的关键词的个数。
利用凝聚层次聚类的方法将抽取出来的关键词进行聚类,建立一种具有层次关联关系的关键词集合。凝聚层次聚类的主要过程为:找到与ti距离最近的5个关键词ta、tb、tc、td、te,使ti作为父节点,将筛选出来的关键词聚类成具有层次关联关系的双层结构,并存入关键词集合di={ti、ta、tb、tc、td、te}中,再依次寻找与ta、tb、tc、td、te距离最近的5个关键词,使ta、tb、tc、td、te分别作为父节点,将筛选出来的关键词聚类成具有层次关联关系的三层结构,分别将第三层结构的关键词有序地存入关键词集合di中。
步骤2015:根据聚类成功的关键词集合和相应的层次关联关系,形成具有层次关联关系的三层模型,建立创新知识网络ikn。
步骤202:输入创新关键词,计算关键词与创新知识网络中关键词的语义关联度,得到知识网络中的创新核心词;计算知识网络中,创新核心词的层次关联紧密度,得到创新相关词集合,利用可视化工具形成创新思维导图;同时计算创新核心词、相关词与创新大数据的相关度,按相关度排序显示创新大数据信息;用户查看并标注信息,根据标注信息生成初始创意集合,可选择进行步骤203,将创意集合发送评价服务器内的“创客社区”进行创意评估与征集,根据返回结果进行数据分析,最终生成创意报告。
其中,步骤202还包括:
步骤2021:输入创新关键词ikw,创新关键词即是所要发明或创新领域内的主要关键词,可以是词或是句子,如果是句子会自动将这句话分词,然后选择所需要的关键词完成创新关键词的输入。
步骤2022:计算关键词与创新知识网络中关键词的语义关联度,得到知识网络中的创新核心词icw。
按语义关联度计算方法wsr来计算输入的创新关键词和层次聚类后关键词的关联度。wsr语义关联度计算公式如下:
公式中a是指创新关键词,b是指层次聚类后的关键词,将a和b转换成需要计算的节点。relartneti是基于数据文本语义关联度计算方法,αi是不同层次节点的权重;节点a和b至少分别隶属于一个分类aj和bk,其中
经过计算后,寻找出语义关联度最高的关键词,即为创新核心词。
步骤2023:计算知识网络中,创新核心词的层次关联紧密度,得到创新相关词集合irw。
聚类紧密程度,是表示该聚类中所有关键词和聚类中心之间的平均相似度,层次紧密度计算公式如下:
其中,cl(ni)表示聚类ni内部的紧密度,tj则是聚类ni中的任意关键词,
步骤2024-1:利用d3.js等数据可视化工具,将创意核心词与相关词集合展示为创新思维导图。
步骤2024-2:计算创新核心词、相关词与爬取到的创新大数据文档的相似度,按相似度排序显示步骤201中爬取到的创新大数据信息。
相似度计算主要步骤是:将创新核心词与相关词分别表示为向量空间模型q(w1q,w2q,…,wnq),采用tf*idf的方式计算权重,之后采用两个向量夹角的余弦函数求相似度,创新词与创新大数据文档的相似度计算公式为:
其中,dj为第j个创新大数据文档,q为创新核心词或相关词,wij、wiq分别为dj、q的向量空间模型中第i个词的权重。
步骤2025:用户查看并标注信息,可在创新思维导图中更换创新核心词,在知识网络中进行重新检索,得到以新的创新核心词为中心的创新思维导图和创新大数据。
步骤2026:通过爬取到的创意信息进行训练学习,生成一组自动生成的创意的语言模型:
语言模型=(rule1,rule2,...,rulek)
每一个规则rulei可表示为:rule=r1×r2×r3×…,其中ri有三种取值:通配符$(可以为任意词语,或为空null),词语的语法语义表示项w以及词语t,即:
ri∈{$}+w+{t1,t2,t3...}
根据用户标注信息,自动生成初始创意集合iis。
步骤2027(可选):可选择进行步骤203,将创意集合发送“创客社区”进行创意评估与征集,社区用户进行主客观评价,对评估结果进行数据分析。
步骤2028:根据初始创意结合和返回的分析结果,最终生成创意报告。若没有进行分步骤7,则创意报告中只包含初始创意集合,主客观评价分析内容为空。
步骤203:将创新任务(创意评估与征集、方案评估与征集、原型测试、满意度调查)发送至评价服务器内,进行社区用户权威性分析,计算任务与用户的匹配度,根据匹配度,将任务推送给相应用户群体,用户进行主客观评估,得到的任务客观评分及主观评价信息返回到各步骤,继续进行下一步创新研发。
其中,步骤203还包括:
步骤2031:将创新任务(创意评估与征集、方案评估与征集、原型测试、满意度调查)设置一定的悬赏分数,发送至“创客社区”进行众智评估,对待解决问题进行分词,根据分词结果得出问题所属的分类。
步骤2032:进行社区用户权威性分析。
在pagerank算法的基础上,构建一个用户问答关系图g=(u,r),其中用户问答关系图中的每一个结点ui∈u表示为一个用户,用户问答关系图中的每一条有向边rij∈r表示为用户ui到用户uj之间的问答交互关系;
引入对答案质量的分析,分析用户的行为,得出初步的用户权威性的计算方法;所述用户的行为,包括:回答问题、选择最佳答案、赞成和反对。
设回答问题的权重分数为x,其中x>0,选择最佳答案的权重分数为ax,其中a>1,赞成的权重为bx,其中b>0,反对的权重为-cx,其中c>0;
其中,auth(ui,c)代表用户ui在问题类别c的权威性值,n代表总的用户数量,
引入对问题难度的分析,得出用户权威性计算方法;
问题难度的计算公式如下:
dif(q)代表问题q的难易程度,1<dif(q)<2,a(q)是问题q的回答集合,|a(q)|代表问题q的回复数量;ta(q)代表回复a的日期,tq(q)代表问题q的提出日期;ta(q)-tq(q)的单位是秒;其中,tavg是回答问题q的平均耗费时间;η是调节参数;
问题的回答数量越多,表明有越多的用户知道问题的答案,问题相对简单,当问题的平均回答时间越长,表明用户无法在短时间之内回答该问题,问题相对困难。
最终计算用户权威性的方法:
步骤2033:计算任务与社区用户的匹配度。
设问题类别构成集合c={c1,c2,c3,…,cn},注册用户构成集合u=[u1,u1,u3,…,un},表征用户与某个问题类别相关程度的计算方法公式如下:
rij=inm(ui,cj)×authij;
其中,rij代表用户ui与问题类别cj的相关程度,其含义为:当某个问题属于类别cj时,用户ui回答这一问题的可能性;inm(ui,cj)代表用户ui在注册之后的第m个月对于问题类别cj的兴趣度,即用户ui是否有兴趣回答类别cj的问题;authij代表用户ui对于问题类别cj的权威度,即用户ui是否有能力回答问题类别cj的问题;initin是用户兴趣度的初始值;qm-1(ui,cj)代表用户ui在注册之后的第m-1个月对类别cj的提问总数,aqm-1(ui,cj)代表用户ui在注册之后的第m-1个月对类别cj的回答总数。
步骤2034:根据匹配度,将任务按优先级推送给相应用户群体。
计算待解决问题的优先级,按照优先级从高到低进行排序,从而得到排序之后的待解决问题列表;待解决问题优先级的计算方法如下:
在公式中,priority(q)指问题q的优先级,interval(q)代表问题q已发布的时间,单位为天,score(q)代表问题q的悬赏分数;
当已发布时间相同时,悬赏分高的问题的优先级高;当问题悬赏分相同时,发布时间更长的问题获得更高的优先级;
根据步骤2033,获取该问题所在的问题类别与各用户的相关程度值,从有序的待解决问题列表中按问题的优先级,推送给相关程度高的用户。
步骤2035:对得到的任务客观评分及主观评价信息进行数据分析,包括客观评价的平均分计算,主观评价的高频词抽取和被赞同次数统计并排序显示等,返回到各步骤。
其中,主要通过构造文本的pat数组和lcp数组来得到一篇文本中多次重复出现的高频字串,进而抽取出高频词。
将待处理文本看作一个字符串,从任意一位字符开始到文本结尾所形成的子字符串,称为文本的一个后缀,pat数组就是文本所有后缀的字典顺序的排列。lcp数组对应于一个pat数组,lcp数组记录了pat数组中相邻两个后缀间的最大公共前缀长度。pat数组和lcp数组的创建过程的实质是字符串的排序过程,可采用bentley-sedgewick算法。
如果在lcp数组中,存在连续的k个元素值大于等于m,则可以推断出有一个长度为m的字符串,在文本中总共出现了k+1次。因此,通过扫描lcp数组可以发现文本的重复字符串及其出现次数。
步骤204:根据创意,输入具体需求描述,从需求描述中提取非标准工程参数,计算非标准工程参数与triz的39个标准工程参数的相似度,得到标准工程参数对,利用triz矛盾矩阵,得到推荐的发明原理;同时计算需求描述与创新大数据的相关度,按相关度排序显示相关信息,根据用户标注的信息,生成初始创新方案,可选择进行步骤203,将方案发送评价服务器内进行方案评估与征集,根据返回结果进行数据分析,最终生成创新方案报告。
其中,步骤204还包括:
步骤2041:根据创意,输入具体需求描述iqc,包括创意名称、创意背景、期望结果、潜在困难四部分内容,便于提取工程参数。
步骤2042-1:
通过对一定数量有代表性的专利文本进行分析整理,得到改善参数提取词汇集合wi={″可以″,改善″,″提高″,......}、恶化参数相关词汇集合wd={″破坏″,″导致″,″丧失″,......},利用此集合,从需求描述中提取集合中词汇的前后名词,分别作为改善或恶化的非标准工程参数pi和pd。
利用基于语义词典hownet的语义相似度计算方法,计算非标准工程参数与triz的39个标准工程参数的相似度。
对于两个汉语词语w1和w2,如果w1有个n义项:s11,s12,…,s1n,w2有个m义项:s12,s22,…,s2m,w1和w2的相似度是各个概念的相似度之最大值:
sim(w1,w2)=maxi=1…n,j=1…msim(s1i,s2j);
在hownet中对一个实词的描述可以表示为一个特征结构,含有四个特征:第一基本义原、其它基本义原、关系义原和关系符号,相对应的,两个概念的这一部分的相似度分别记为sim1(s1,s2)、sim2(s1,s2);、sim3(s1,s2)和sim4(s1,s2)。概念的整体相似度为:
其中,β(1≤i≤4)是可调节的参数,且有:β1+β2+β3+β4=1,β1≥β2≥β3≥β4.
计算得到标准工程参数对,利用triz提供的矛盾矩阵,得到发明原理。
步骤2042-2:计算需求描述与创新大数据的相似度,并按相似度排序显示。计算方法与步骤202中步骤2022中采用cosine值计算相似度方法一致。
步骤2043:用户查看发明原理具体内容、案例和推荐的创新大数据信息,包括相关专利、相关科技等,标注有用信息。
步骤2044:通过爬取到的triz解决方案进行训练学习,生成一组自动生成的创新方案的语言模型,通过用户标注的信息,生成初始创新方案。
步骤2045(可选):可选择进行步骤203,将初始创新方案发送至评价服务器内进行创意评估与征集,根据社区用户的主客观评价进行数据分析。
步骤2046:根据初始创新方案和返回的分析结果,生成创新方案报告。若没有进行步骤2045,则创新方案报告中只包含初始创新方案,主客观评价内容为空。
步骤205:产品研发人员根据创新方案设计产品原型,进行内部“α测试”,通过后进行在线“a/b测试”,进行步骤203,将测试发送评价服务器内,对测试结果进行数据分析,根据分析结果最终生成原型测试报告。
其中,步骤205还包括:
步骤2051:产品设计人员根据创新方案进行产品外观、结构、功能等设计,通过设计软件将产品原型展现出来,从中选出两个最优方案pa和pb。
步骤2052:创新研发部门进行内部“α测试”,即依据产品原型pa和pb,生产出对应的产品样品sa和sb,用以确定产品原型设计在技术上是否可以实现,依据产品原型生产出的产品是否符合期望要求等,若存在问题,对产品原型进行调整改进,得到产品原型
步骤2053:进行步骤203,将原型
步骤2054:生成原型测试报告,根据报告内容,对产品原型继续调整修改,确定最终产品原型。
步骤206:产品售后人员设计满意度参数及评分标准,分别进行线上、线下满意度调查,线上满意度调查进行步骤203,将满意度调查发送“创客社区”,对社区用户评价结果和线下调查结果进行综合数据分析,生成产品分析报告,将数据发送至步骤201的创新大数据库,作为下一次创新的大数据基础。
其中,步骤206还包括:
步骤2061:产品售后人员设计满意度参数及评分标准,参数如外观、材质、性能、故障率、性价比等,满意度评分分别为1到5颗星,每个参数满意度评分后可备注满意或不满意的具体原因、改进建议。
步骤2062-1:进行电话回访、问卷调查等线下满意度调查,统计调查结果,进行数据分析,如计算各参数均值,提取主观评价高频词等。
步骤2062-2:进行线上满意度调查,进行步骤203,将满意度调查发送至评价服务器,根据社区用户反馈结果进行数据分析。
步骤2063:将线上和线下的调查分析结果综合,生成产品分析报告。
步骤2064:将满意度调查数据发送至步骤201的创新大数据库中,作为下一次产品更新升级的大数据基础。
本发明创新研发基于科学的大数据分析,能够准确获取用户需求、最新技术、现有产品优缺点等信息,实现精准创新;实现了创新大数据融合、创意智能推荐、解决方案生成、产品原型测试、产品售后分析、产品更新升级等循环创新全过程;创新研发不再仅仅依靠专业创新人员,更集合了众智的力量,实现了社会化与公众参与的互动进化式创新。
图3是本发明的创新创意的大数据处理服务器结构示意图。
如图3所示,本发明的一种创新创意的大数据处理服务器,包括:
(1)创新知识网络生成模块,其用于爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络。
在所述创新知识网络生成模块中,利用定向爬虫对多源异构的创新大数据进行爬取。其中,创新大数据主要指从科技博客、技术报告、专利信息、社交媒体等渠道提取出的海量网络数据和来源于企业erp和web交易系统的企业报表、产品交易数据和企业内部专业知识等。
具体地,所述创新知识网络生成模块,包括:
预处理模块,其用于利用现有分词系统和停用词库对创新大数据进行分词、去停用词预处理;
关键词提取模块,其用于建立向量空间模型vsm,通过tf-idf计算vsm中各项的权重,提取关键词;
层次关联关系集合建立模块,其用于计算提取出关键词的相关度,将相关度高的关键词筛选出来,利用层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合;
创新知识网络建立模块,其用于根据聚类后的关键词集合和相应的层次关联关系,形成具有层次关联关系的三层模型,最终建立出创新知识网络。本发明首先通过去噪预处理并提取关键词,进而通过层次聚类的方法将这些关键词进行聚类,建立具有层次关联关系的集合,最后建立出创新知识网络,将关键词及其层次结合在一起,使得创新知识网络更加立体形象。
(2)初始创新方案生成模块,其用于接收客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案。
具体地,所述初始创新方案生成模块中进行相关信息标注之后,还包括通过训练好的语言模型自动生成初始创新方案。
(3)初始创新方案评分模块,其用于将初始创新方案发送至评价服务器,并在评价服务器内依据预设评分标准对初始创新方案进行评分。
(4)可行创新方案生成模块,其用于接收评价服务器的评分并与方案合格评分阈值相比较,若前者大于后者,则初始创新方案为可行创新方案,直至得到可行创新方案。
本发明通过爬取多源异构的创新大数据,并集合生成具有层次关联关系的创新知识网络,再根据客户端输入的创意需求描述,得到创新关键词,计算创新关键词与创新知识网络中的关键词的关联度和层次关联关系的紧密度,并进行相关信息标注,生成初始创新方案,再经过评价服务器内的评分,生成可行创新方案,最终实现准确获取用户需求、最新技术、现有产品优缺点等信息,实现精准创新,以及实现了创新大数据融合、创意智能推荐和解决方案生成,提高了产品研发的效率。
图4是本发明的创新创意的大数据处理系统结构示意图。
如图4所示,本发明的一种创新创意的大数据处理系统,包括上述所述的创新创意的大数据处理服务器。
其中,所述大数据处理服务器还与客户端相连。本发明在客户端实时显示由大数据处理服务器输出的可行创新方案。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!