基于US‑ELM的基因芯片表达数据分析系统及方法与流程
本发明属于医学大数据挖掘技术领域,具体涉及基于us-elm的基因芯片表达数据分析系统及方法。
背景技术:
目前,基因芯片已经成为临床研究的重要研究方式,数据分析的结果直接影响着医生对疾病的诊断。目前基因芯片数据分析的相关研究有很多,主要集中在寻找差异表达基因/交集分析、数据降维、聚类分析和功能富集分析。然而,如何获得基因芯片原始数据并将其转化为各个实验目的所需数据形式成为了技术关键点。
在现有的针对基因数据分析算法的相关研究中,所处理的基因数据大多数来源于公开基因数据库,如geo数据库。由于基因芯片数据样本量小、维度高的特点,基因数据的分析方法受到越来越多的关注。许多传统分析方法存在限制性,使得数据分析在规模以及效率上受到极大制约。
技术实现要素:
本发明提供一种基于us-elm的基因芯片表达数据分析系统及方法,采用的遗传法差异基因处理过程能筛选出更有效的明显表达差异基因,提高了数据分析的准确性。
本发明提供一种基于us-elm的基因芯片表达数据分析系统,包括:
基因预处理单元,用于对基因芯片进行预处理以获得适用于实验的数据格式,即基因表达数据矩阵;
差异基因筛选单元,基于基因表达数据矩阵寻找在基因芯片中不同个体或者是不同组织中表达发生明显变化的差异基因,获得差异表达基因矩阵;
聚类单元,用于对差异表达基因矩阵进行聚类分析,得到共表达基因序列;
富集分析单元,用于对共表达基因序列进行富集分析,得到关于基因所参与的多条通路,得出在数据上共表达基因序列的生物学功能解释。
在本发明的基于us-elm的基因芯片表达数据分析系统中,所述基因预处理单元包括:
背景校正器,用于根据mas方法将基因芯片分为16个网格区域,每个网格区域使用信号强度最低的2%的探针去计算背景值和噪声以获得初始基因数据矩阵;
标准化器,用于选择一个基因芯片作为参考芯片,将其他基因芯片和参考芯片的初始基因数据矩阵分别作为线性缩放方法的输入,依次进行线性回归分析,用回归直线对其他基因芯片的信号值做缩放,进而输出标准化矩阵;
汇总器,用于使用统计方法通过probeset的杂交信号计算出标准化矩阵的计算表达量,进而得到基因表达数据矩阵。
在本发明的基于us-elm的基因芯片表达数据分析系统中,所述差异基因筛选单元包括:
初始种群建立器,用于将基因表达数据矩阵与遗传算法染色体结构之间建立联系,再根据基因与染色体的关系实现算法的编码和解码,建立初始种群;
适应度计算器,根据适应度函数计算初始种群中每个个体的适应度;
选择算子操作器,根据初始种群中个体的适应度,对个体进行优胜劣汰操作,筛选出适应度高的个体参与进化繁殖下一代;
交叉算子操作器,用于将经筛选后的不同个体的两个染色体的部分基因相互交换重组生成新的个体;
变异算子操作器,用于改变新的个体的染色体的某些基因值,进而产生新一代种群,保持种群多样性;
算法终止器,用于当种群不在变化或达到设定的迭代次数时,终止迭代过程,获得差异表达基因矩阵。
在本发明的基于us-elm的基因芯片表达数据分析系统中,所述聚类单元包括:
变换矩阵生成器,根据us-elm原理,生成差异表达矩阵的拉普拉斯变换矩阵;
随机参数生成器,根据us-elm原理,差异表达矩阵作为输入,设定隐层节点个数,随机生成输入节点的权重向量和隐层节点的阈值;
转换器,根据us-elm原理,利用输入节点的权重向量和隐层节点的阈值生成差异表达矩阵的隐层输出矩阵;
降维器,根据us-elm原理,根据拉普拉斯矩阵和隐层输出矩阵,得到降维后的差异表达矩阵;
聚类器,利用聚类算法对降维后的差异表达矩阵进行聚类,得到共表达基因序列。
在本发明的基于us-elm的基因芯片表达数据分析系统中,所述富集分析单元包括:
kegg富集器,用于对共表达基因序列进行kegg富集分析,得到关于基因所参与的多条通路;
go富集器,用于对共表达基因序列进行go富集分析,得出在数据上共表达基因的生物学功能解释。
本发明还一种基于us-elm的基因芯片表达数据分析方法,包括如下步骤:
步骤1:对基因芯片进行预处理以获得适用于实验的数据格式,即基因表达数据矩阵;
步骤2:基于基因表达数据矩阵寻找在基因芯片中不同个体或者是不同组织中表达发生明显变化的差异基因,获得差异表达基因矩阵;
步骤3:对差异表达基因矩阵进行聚类分析,得到共表达基因序列;
步骤4:对共表达基因序列进行富集分析,得到关于基因所参与的多条通路,得出在数据上共表达基因序列的生物学功能解释。
在本发明的基于us-elm的基因芯片表达数据分析方法中,所述步骤1包括:
步骤1.1:采用根据mas方法将基因芯片分为16个网格区域,每个网格区域使用信号强度最低的2%的探针去计算背景值和噪声以获得初始基因数据矩阵;
步骤1.2:选择一个基因芯片作为参考芯片,将其他基因芯片和参考芯片的初始基因数据矩阵分别作为线性缩放方法的输入,依次进行线性回归分析,用回归直线对其他基因芯片的信号值做缩放,进而输出标准化矩阵;
步骤1.3:使用统计方法通过probeset的杂交信号计算出标准化矩阵的计算表达量,进而得到基因表达数据矩阵。
在本发明的基于us-elm的基因芯片表达数据分析方法中,所述步骤2包括:
步骤2.1:根据基因遗传规律,将基因表达数据矩阵与遗传算法染色体结构之间建立联系,再根据基因与染色体的关系实现算法的编码和解码,建立初始种群;
步骤2.2:根据适应度函数计算初始种群中每个个体的适应度;
步骤2.3:根据初始种群中个体的适应度,对个体进行优胜劣汰操作,筛选出适应度高的个体参与进化繁殖下一代;
步骤2.4:将经筛选后的不同个体的两个染色体的部分基因相互交换重组生成新的个体;
步骤2.5:改变新的个体的染色体的某些基因值,进而产生新一代种群,保持种群多样性;
步骤2.6:当种群不在变化或达到设定的迭代次数时,终止迭代过程,获得差异表达基因矩阵。
在本发明的基于us-elm的基因芯片表达数据分析方法中,所述步骤3包括:
步骤3.1:根据us-elm原理,生成差异表达矩阵的拉普拉斯变换矩阵;
步骤3.2:根据us-elm原理,差异表达矩阵作为输入,设定隐层节点个数,随机生成输入节点的权重向量和隐层节点的阈值;
步骤3.3:根据us-elm原理,利用输入节点的权重向量和隐层节点的阈值生成差异表达矩阵的隐层输出矩阵;
步骤3.4:根据us-elm原理,根据拉普拉斯矩阵和隐层输出矩阵,得到降维后的差异表达矩阵;
步骤3.5:利用聚类算法对降维后的差异表达矩阵进行聚类,得到共表达基因序列。
在本发明的基于us-elm的基因芯片表达数据分析方法中,所述步骤4包括:
步骤4.1:对共表达基因序列进行kegg富集分析,得到关于基因所参与的多条通路;
步骤4.2:对共表达基因序列进行go富集分析,得出在数据上共表达基因的生物学功能解释。
本发明的基于us-elm的基因芯片表达数据分析系统及方法至少具有以下有益效果:本发明的基于us-elm的基因芯片表达数据分析系统及方法在整体上提高了数据分析的准确性,具体的遗传法差异基因处理过程筛选出更有效的明显表达差异基因,聚类处理中得出的类别在生物学解释上具有更多的相似性。
附图说明
图1为本发明的基于us-elm的基因芯片表达数据分析系统的结构框图;
图2为本发明的基于us-elm的基因芯片表达数据分析方法的流程图。
具体实施方式
极限学习机(extremelearningmachine,elm)是一种简单易用、有效的单隐层前馈神经网络slfns学习算法。2004年由南洋理工大学黄广斌副教授提出。传统的神经网络学习算法(如bp算法)需要人为设置大量的网络训练参数,并且很容易产生局部最优解。极限学习机只需要设置网络的隐层节点个数,在算法执行过程中不需要调整网络的输入权值以及隐元的偏置,并且产生唯一的最优解,因此具有学习速度快且泛化性能好的优点。
无监督极限学习机(unsupervisedextremelearningmachine,us-elm),该算法保持了极限学习机的学习能力和计算有效性的基础上,还可用于处理聚类问题。
结合附图对本发明的基于us-elm的基因芯片表达数据分析系统及方法进行说明。
如图1所示为本发明的基于us-elm的基因芯片表达数据分析系统的结构示意图,分析系统包括基因预处理单元1、差异基因筛选单元2、聚类单元3以及富集分析单元4。基因预处理单元1用于对基因芯片进行预处理以获得适用于实验的数据格式,即基因表达数据矩阵。差异基因筛选单元2基于基因表达数据矩阵寻找在基因芯片中不同个体或者是不同组织中表达发生明显变化的差异基因,获得差异表达基因矩阵。聚类单元3用于对差异表达基因矩阵进行聚类分析,得到共表达基因序列。富集分析单元4用于对共表达基因序列进行富集分析,得到关于基因所参与的多条通路,得出在数据上共表达基因序列的生物学功能解释。
基因预处理单元1包括:背景校正器11、标准化器12和汇总器13。背景校正器11用于根据mas方法将基因芯片分为16个网格区域,每个网格区域使用信号强度最低的2%的探针去计算背景值和噪声以获得初始基因数据矩阵。标准化器12用于选择一个基因芯片作为参考芯片,将其他基因芯片和参考芯片的初始基因数据矩阵分别作为线性缩放方法的输入,依次进行线性回归分析,用回归直线对其他基因芯片的信号值做缩放,进而输出标准化矩阵。汇总器13用于使用统计方法通过probeset的杂交信号计算出标准化矩阵的计算表达量,进而得到基因表达数据矩阵。
差异基因筛选单元2包括:初始种群建立器21、适应度计算器22、选择算子操作器23、交叉算子操作器24、变异算子操作器25和算法终止器26。初始种群建立器21用于将基因表达数据矩阵与遗传算法染色体结构之间建立联系,再根据基因与染色体的关系实现算法的编码和解码,建立初始种群。适应度计算器22根据适应度函数计算初始种群中每个个体的适应度。选择算子操作器23根据初始种群中个体的适应度,对个体进行优胜劣汰操作,筛选出适应度高的个体参与进化繁殖下一代。交叉算子操作器24用于将经筛选后的不同个体的两个染色体的部分基因相互交换重组生成新的个体。变异算子操作器25用于改变新的个体的染色体的某些基因值,进而产生新一代种群,保持种群多样性。算法终止器26用于当种群不在变化或达到设定的迭代次数时,终止迭代过程,获得差异表达基因矩阵。
聚类单元3包括:变换矩阵生成器31、随机参数生成器32、转换器33、降维器34和聚类器35。变换矩阵生成器31根据us-elm原理,生成差异表达矩阵的拉普拉斯变换矩阵。随机参数生成器32根据us-elm原理,差异表达矩阵作为输入,设定隐层节点个数,随机生成输入节点的权重向量和隐层节点的阈值。转换器33根据us-elm原理,利用输入节点的权重向量和隐层节点的阈值生成差异表达矩阵的隐层输出矩阵。降维器34根据us-elm原理,根据拉普拉斯矩阵和隐层输出矩阵,得到降维后的差异表达矩阵。聚类器35利用聚类算法对降维后的差异表达矩阵进行聚类,得到共表达基因序列。
富集分析单元4包括:kegg富集器41和go富集器42。kegg富集器41用于对共表达基因序列进行kegg富集分析,得到关于基因所参与的多条通路。go富集器42用于对共表达基因序列进行go富集分析,得出在数据上共表达基因的生物学功能解释。
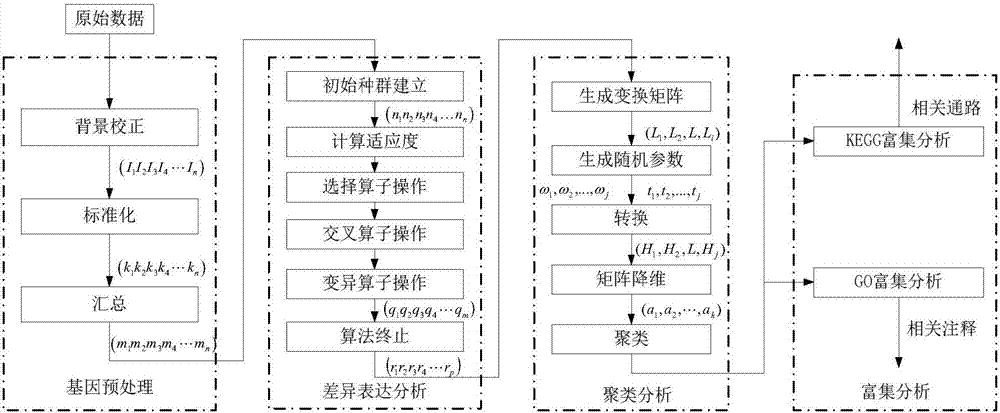
如图2所示为本发明的基于us-elm的基因芯片表达数据分析方法的流程图,本发明的分析方法包括如下步骤:
步骤1:基因预处理,对基因芯片进行预处理以获得适用于实验的数据格式,即基因表达数据矩阵(m1m2m3m4…mn);
步骤2:差异表达分析,基于基因表达数据矩阵(m1m2m3m4…mn)寻找在基因芯片中不同个体或者是不同组织中表达发生明显变化的差异基因,获得差异表达基因矩阵(r1r2r3r4…rp);
步骤3:聚类分析,对差异表达基因矩阵(r1r2r3r4…rp)进行聚类分析,得到共表达基因序列;
步骤4:富集分析,对共表达基因序列进行富集分析,得到关于基因所参与的多条通路,得出在数据上共表达基因序列的生物学功能解释。
步骤1具体包括:
步骤1.1:背景校正,实际中基因芯片有多达30%的mm探针获得的信号强度比相应pm探针的还强,做一个pm-mm或pm/mm不能够去除背景噪声的影响,因此,采用mas方法将基因芯片分为16个网格区域,每个网格区域使用信号强度最低的2%的探针去计算背景值和噪声以获得初始基因数据矩阵(i1i2i3i4…in);
步骤1.2:标准化,选择一个基因芯片作为参考芯片,将其他基因芯片和参考芯片的初始基因数据矩阵(i1i2i3i4…in)分别作为线性缩放方法的输入,依次进行线性回归分析,用回归直线对其他基因芯片的信号值做缩放,进而输出标准化矩阵(k1k2k3k4…kn);
步骤1.3:汇总,使用统计方法通过probeset(包含多个探针)的杂交信号计算出标准化矩阵(k1k2k3k4…kn)的计算表达量,进而得到基因表达数据矩阵(m1m2m3m4…mn)。
步骤2具体包括:
步骤2.1:初始种群建立,根据基因遗传规律,将基因表达数据矩阵(m1m2m3m4…mn)与遗传算法染色体结构之间建立联系,再根据基因与染色体的关系实现算法的编码和解码,建立初始种群(n1n2n3n4…nn);
步骤2.2:计算适应度,根据适应度函数计算初始种群中每个个体的适应度;
步骤2.3:选择算子操作,根据初始种群(n1n2n3n4…nn)中个体的适应度,对个体进行优胜劣汰操作,筛选出适应度高的个体参与进化繁殖下一代;
步骤2.4:交叉算子操作,将经筛选后的不同个体的两个染色体的部分基因相互交换重组生成新的个体;
步骤2.5:变异算子操作,改变新的个体的染色体的某些基因值,从而形成新的个体,产生新一代种群(q1q2q3q4…qm),其中m<n,保持种群多样性,防止过早出现收敛现象;
步骤2.6:当种群不在变化或达到设定的迭代次数时,终止迭代过程,获得差异表达基因矩阵(r1r2r3r4…rp),其中p<m。
步骤3具体包括:
步骤3.1:生成变换矩阵,根据us-elm原理,生成差异表达矩阵(r1r2r3r4…rp)的拉普拉斯变换矩阵(l1,l2,l,li);
步骤3.2:生成随机参数,根据us-elm原理,将差异表达矩阵(r1r2r3r4…rp)作为输入,设定隐层节点个数j,随机生成输入节点的权重向量ω1,ω2,…,ωj和隐层节点的阈值t1,t2,…,tj;
步骤3.3:转换,根据us-elm原理,利用输入节点的权重向量ω1,ω2,…,ωj和隐层节点的阈值t1,t2,…,tj生成差异表达矩阵(r1r2r3r4…rp)的隐层输出矩阵(h1,h2,l,hj);
步骤3.4:矩阵降维,根据us-elm原理,根据拉普拉斯矩阵(l1,l2,l,li)和隐层输出矩阵(h1,h2,l,hj),得到降维后的差异表达矩阵(a1,a2,…,ak);
步骤3.5:聚类,利用聚类算法对降维后的差异表达矩阵进行聚类,得到共表达基因序列。
步骤4具体包括:
步骤4.1:对共表达基因序列进行kegg富集分析,得到关于基因所参与的多条通路;
具体实施时,通过细胞或生物体的基因组信息去了解其较高层次的功能与作用之生物信息资源,也就是整理出现存的调控网络,并建立其中每个组件与基因间的关系,获得n个通路,并对基因所参与通路做出生物学解释;
步骤4.2:对共表达基因序列进行go富集分析,得出在数据上共表达基因的生物学功能解释。
具体实施时,根据挑选出的差异基因,计算这些差异基因同go分类中某(几)个特定的分支的超几何分布关系,go分析会对每个有差异基因存在的go返回一个p-value,小的p值表示差异基因在该go中出现了富集,提供了三层结构的系统定义方式,用于描述基因产物的功能,获得我们所需的表达矩阵的专业生物学注释。
本发明的基于us-elm的基因芯片表达数据分析系统及方法在整体上提高了数据分析的准确性,具体的遗传法差异基因处理过程筛选出更有效的明显表达差异基因,聚类处理中得出的类别在生物学解释上具有更多的相似性。
以上所述是本发明的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!