一种利用RGB图像还原3D场景的方法与流程
本发明设计涉及3维结构预测领域,特别涉及一种利用rgb图像还原3d场景的方法。
背景技术:
人类大脑有补全环境3d信息的能力。看到一个3d物体的一面,人可以猜出另外的一面的样子,并且在大脑中生成整个物体的3d结构。这种利用部分信息推测完整3d结构的能力为人类的环境认知,移动,躲避障碍物,路径规划等提供很大帮助。机器尚不具备鲁棒的3d结构补全能力。即使在红外测距仪等的帮助下,机器也只能得到可见部分的3d信息。目前帮助机器实现3d结构补全的方法也主要集中在利用cad库中预先定义好的3d物体模型来合成或拼接成与环境中物体相匹配的3d结构。这样的做法使生成的3d结构过于单一,并不能泛用到实际生活中多变的场景中。如图3所示,试验机器和人类看到同一张图片的反应,图为某场景的2d图像;图4所示机器在有深度信息的情况下对图像的理解,被遮挡的部分的信息无从得知;图5所示人类对图像的理解,人脑可以补全被遮挡的物体,还原3d结构。近年来随着监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。gan(generativeadversarialnetwork,生成对抗网络)和vae(variationalauto-encoder,变分自编码器)等自监督生成模型受到了越来越多的关注。生成模型可以利用潜在空间的随机向量,生成有意义的图像或者动画。图7-10展示了利用gan实现的2d人脸图像补全效果,图7和图9为输入图像为带有噪音的人脸图像,图8和图10为输出图像为去掉噪音后的人脸。
同样的生成模型也被扩展到生成3d结构的任务中,2016年由mit提出的3d-vae-gan可以利用物体的rgb图像推断出物体的3d图像。和人一样,现在的机器也拥有了利用rgb图像推断物体3d结构的能力。然而3d-vae-gan只能预测单个物体的3d结构,对于含有复杂环境,包含物体遮挡的场景还是无能为力。
综上所述,如何利用包含多个物体的场景的2d图像,还原场景的三维结构图,是一个亟待解决的问题。
技术实现要素:
本发明的目的是提供一种利用rgb图像还原3d场景的方法,以帮助机器理解多物体,有遮挡的复杂环境。
为了实现上述目的,本发明提供如下技术方案:一种利用rgb图像还原3d场景的方法,具体流程为:
步骤s1:读入rgb图像;
步骤s2:在图像范围内进行物体检测,将检测到的物体利用矩形窗口进行标定;
步骤s3:检测到的图像进行实例分割,得到单个物体的蒙版;
步骤s4:利用深度学习模型来预测单个物体的三维形状,输入数据为单个物体的蒙版;
步骤s5:对图像中的每对儿物体间的相对关系进行回归预测;
步骤s6:利用预测得到的物体间的相对关系构建图;
步骤s7:进行全局图优化,得到最优的物体3维空间摆放方式;
步骤s8:得到三维场景。
进一步的,步骤s2具体包括:利用深度学习模型在图像上进行特征提取,生产检测物体候选区域,检测物体窗口分类和窗口位置最优推定。其有益效果是,利用深度学习模型得到的检测结果精度高,误差小。
进一步的步骤s3具体包括:步骤s2产生的物体候选区域内部进行特征上采样,利用双线性差值的方法得到的检测物体窗口内部像素级别的分类,将窗口内类别相同的像素统合为该检测物体的蒙版。
具体的,s3步骤所述的在窗口内进行像素级别的分类所用的算法为svm。其有益效果是在检测的基础上进行分割,大大降低了多类别之间的互相干扰,提高了像素分类的质量。
进一步的步骤s4具体包括:输入由步骤s3得到的物体蒙版,利用变分自编码器(vae)将物体蒙版投影到潜在向量空间,利用生成对抗网络将潜在向量生成所对应的3维结构。
进一步的步骤s5中涉及到了一种预测物体之间的相对关系的回归算法。其特征在于:使用3d转换矩阵表示两物体之间的平移以及旋转关系;利用深度学习算法和大数据训练来使模型逼近真实的物体之间相对关系的分布。
进一步的步骤s6中的图为无向图g(v,e),其中v代表顶点,此处代表检测物体的集合,e为边的集合,此处代表检测物体之间的转换矩阵。获取g的方式为利用步骤s5分别推测两个物体间的转换矩阵。
进一步的步骤s7的目的为优化步骤s6产生的图。
本发明利用物体检测方法,检测到图像中的多个物体;对多个物体进行像素级别的分割,得到多个物体的蒙版;在此基础上,对每两个物体间的相对位置进行预测,生成无向图;最后利用图优化算法优化环境中多物体的摆放关系;本发明解决了由二维图像直接推断三维空间结构的课题。
附图说明
图1为本发明3d推定算法流程图。
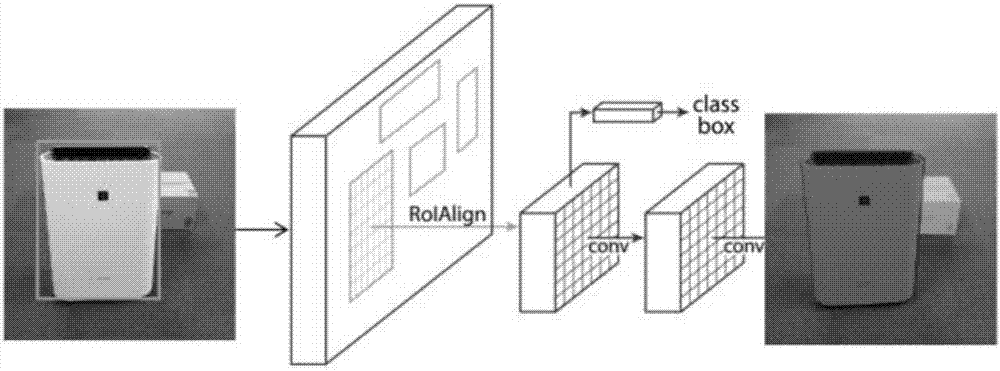
图2为基于maskrcnn的实例分割效果图。
图3为利用自编码器+生成器将图像转换成3d模型结构图。
图4为试验机器和人类看到同一张图片的反应的某场景的2d图像。
图5为所示机器在有深度信息的情况下对图像的理解的图。
图6所示人类对图像的理解的图。
图7为利用gan实现的2d输入图像为带有噪音的人脸图像。
图8为图7的输出图像去掉噪音后的人脸图。
图9为另一种利用gan实现的2d输入图像为带有噪音的人脸图像。
图10为图9的输出图像去掉噪音后的人脸图。
具体实施方式
下面介绍该发明各个步骤的具体算法。
一种利用rgb图像还原3d场景的方法,具体流程图1所示;
步骤s2所涉及的在图像范围内进行物体检测的具体实施方式如下:
在图像范围内进行物体检测,将检测到的物体利用矩形窗口进行标定。此处利用基于fasterr-cnn算法的检测方式。具体步骤为:特征提取,生产候选区域,窗口分类和精修。特征提取部分利用深度卷积神经网络(cnn)实现。cnn包含包含若干层卷基层(conv)和激活层(relu)。本方案的cnn利用imagenet训练得到的vgg网络。fasterrcnn利用rpn(候选区域生成网络)生成候选区域。在fasterrcnn中,prn是一个很小的卷积网络(3×3conv→1×1conv→1×1conv)在移动窗口中查看conv5_3卷基层特征图的全体特征量。每个移动窗口都有9个跟其感受野相关的锚盒子(anchorbox)。prn会对每个anchorbox做窗口位置回归(boundingboxregression)和窗口置信度评分(boxconfidencescoring)。通过结合以上三者的loss成为一个共同的全体特征量,整个管道可以被训练。fasterr-cnn的顶层输出也包括boundingboxregression和窗口置信度评分,这两个部分分别用来精修窗口,和将窗口内的物体进行识别/分类。
步骤s3所涉及的对检测到的图像进行实例分割,得到单个物体的蒙版的具体实施方式如下:
实例分割指的是将2d图像细分为多个图像子区域(像素的集合),其中每个子区域的像素都属于同一个物体。方案利用facebookai研究所的mask-rcnn。图2为实例分割的一个效果。对于图像中的每个物体,实例分割会生成一个蒙版(mask)。利用蒙版,可以将图像中的物体分割出来。maskrcnn是基于fasterrcnn进行了改进。通过增加一支特定类别对象掩码预测,maskrcnn扩展了面向实例分割的fasterrcnn,与已有的边界框回归量和对象分类器并行。由于fasterrcnn的rolpool并非设计用于网络输入和输出间的像素到像素对齐,maskrcnn用rolalign取代了它。rolalign使用了双线性插值来计算每个子窗口的输入特征的准确值,而非rolpooling的最大池化法。maskrcnn的训练数据集为开源库microsoftcoco。
步骤s4涉及到的利用深度学习模型来预测单个物体的三维形状的具体实施方式如下:
利用vae-gan来预测单个物体的三维形状,输入数据为单个物体的蒙版。vae(变分自编码器)用来吧图像映射到潜在变量空间(latentspace)然后再将潜在变量空间的数据映射到图像的一种自编码解码的方式。gan(生成对抗网络)是利用潜在变量空间的数据生成真实数据的方法。本方案将vae的自编码部分嫁接到gan之前,目的是利用vae将2d图像映射到潜在变量空间,然后利用gan将潜在变量映射到3d模型上面。vae-gan包括三个部分:图像编码器:e,解码器:gan,和一个识别器:d。图像编码器包括五个空间卷机内核分别为{11,5,5,5,8}和步长{4,2,2,2,1}.卷积层间使用批标准化(batchnormalization)和relu,和一个采样器用来采样200维的向量。vae-gan的结构如图3所示,输入实例蒙版→自编码器→潜在向量→生成器→重构3d形状。
vae-gan的学习过程涉及到的损失函数l包括三部分:物体重构损失lrecon,交叉熵损失l3d-gan和相对熵损失lkl。写成如下等式:
l=l3d-gan+a1lkl+a2lrecon,
其中a1和a2分别是重构损失和相对损熵失的的权重。我们设置a1=5,a2=104。其中三个损失的计算等式如下:
l3d-gan=logd(x)+log(1d(g(z))),
lkl=dkl(q(z|y)||p(z)),
lrecon=||g(e(y))x||2,
其中x是训练数据集中的3d模型,y是与之相对的2d模型,q(z|y)是潜在空间z的可变概率分布。本方案选择p(z)为一个多元高斯分布,它的均值为0,方差为1.训练vae-gan的时候需要2d图像和与之对应的3d模型同时存在。该训练数据集利用对cad模型手动标定得到。
步骤s5涉及的对图像中的每对儿物体间的相对关系进行回归预测的具体实施方式如下:
对图像中的每对儿物体间的相对关系进行回归预测。得到各个物体的3d形状之后。最后利用回归器预测3d模型之间的相对关系。3d模型之间的相对关系用3d空间的转换矩阵t表示。t是一个4x4的矩阵,其中t的左上角的3x3子矩阵代表着三维空间的旋转关,t的第四列[xt,yt,zt]表示三维空间中的平移关系。回归算法的目标就是最小化转换矩阵的预测值与实际值之间的差异。本发明采用l2损失表示这一误差。l2损失的表示方法为真实值和预测值之间差异的平方值。回归算法利mlp(多层神经网络)。训练数据中的转换矩阵的真实值是在模拟的3d模型中直接计算获取。
步骤s7中涉及到的图优化的具体实施方式如下。
步骤s6中对两两检测物体的转换矩阵进行推算,并得到了无向图g(v,e),其中v代表顶点,此处代表检测物体的集合,e为边的集合,此处代表检测物体之间的转换关系。如果环境中出现两个以上物体,由于两两物体之间都包含推测的相对位置关系,这样由不同检测物体递推到所有物体的摆放位置之间会产生误差信息。下面介绍如何选择性的采用无向图g的边集以消除这种误差。
步骤s2中利用到了深度神经网络来做物体检测算法。对于每个检测到的物体,神经网络会输出一个置信度c:confidence,来表示这个被检测到的物体的可靠程度。我们利用这个置信度对无向图的边集进行筛选:
三维空间摆放算法
- 还没有人留言评论。精彩留言会获得点赞!